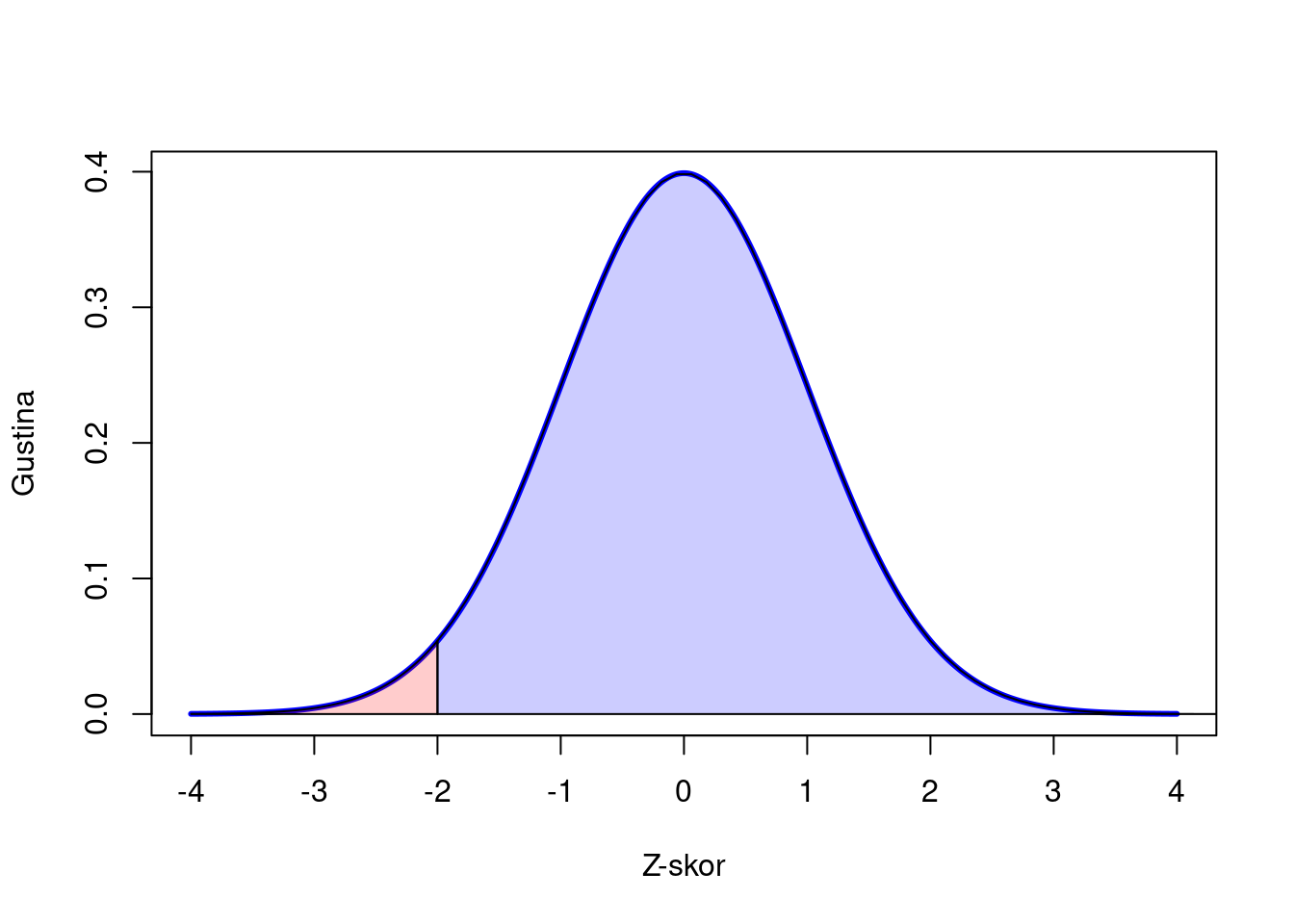
U prethodnom poglavlju susreli smo se sa grafikonom normalne distribucije i vrednošću koja se nalazi na njenom rubu, što ukazuje na to da je ta vrednost izuzetno retka.
Suština statističkog zaključivanja leži upravo u analizi retkih događaja. Kada naiđemo na rezultat koji značajno odstupa od očekivanih vrednosti, to nam pruža mogućnost da preispitamo naše početne pretpostavke o populaciji koju proučavamo.
Vratimo se na naš primer i napravimo pregled ključnih saznanja do kojih smo došli.
Sumiraćemo ključne tačke našeg primera:
Početna pretpostavka bila je da prosečna zarada u Srbiji iznosi 1000 EUR.
Na osnovu te pretpostavke konstruisali smo normalnu distribuciju aritmetičkih sredina uzoraka (Slika 6.9).
Analiza stvarnog uzorka pokazala je prosečnu zaradu od 799.8 EUR.
Koristeći standardnu grešku, izračunali smo Z-skor koji iznosi -2.58.
Ustanovili smo da se ova vrednost nalazi na ekstremnom levom kraju normalne distribucije.
Na osnovu ovih informacija, imamo dve opcije za razmatranje:
Imamo problem sa uzorkom koji je zbog svoje specifične strukture doveo je do ekstremnog rezultata.
Uzorak je adekvatan, ali je naša početna pretpostavka o populaciji bila netačna.
Drugim rečima, ako pretpostavimo da prosečna zarada iznosi 1000 EUR, a podaci iz našeg uzorka pokazuju drugačije (značajno odstupaju od te pretpostavke), onda neko mora biti „odgovoran“: ili uzorak ili pretpostavka.
U statističkom zaključivanju uvek branimo uzorak. Zbog čega? Prvenstveno zato što se oslanjamo na pretpostavku da je uzorak slučajan i da je proces prikupljanja podataka bio ispravan. Uz to, veliki uzorak donosi manju standardnu grešku, što nam daje čvrstu osnovu da verujemo da uzorak neće previše odstupati od stvarne vrednosti parametra populacije.
Kada se nađemo u situaciji gde rezultat uzorka značajno odstupa od distribucije koja proizlazi iz naše pretpostavke, logičan korak je preispitivanje te pretpostavke.
Kada od pretpostavke dođemo do retkog ili ekstremnog rezultata, logično je zaključiti da je pretpostavka verovatno pogrešna.
Retkost ili ekstremnost nekog rezultata (npr. aritmetičke sredine uzorka) izražavamo kroz standardizovane skorove, kao što je Z-skor. Z-skor predstavlja udaljenost vrednosti od centra distribucije, izraženu u broju standardnih grešaka. Ali kako znamo kada smo ušli u region ekstremnih rezultata? Odgovor leži u pravilu tri sigme (Slika 6.6). Podsetimo se da se oko 95% svih rezultata nalazi unutar 2 standardne devijacije od centra distribucije, dok se gotovo svi rezultati (99.72%) nalaze unutar 3 standardne devijacije. Ovi procenti definišu granice regiona ekstremnosti. Na primer, ako rezultat ima Z-skor +2.1, on se nalazi među 2.5% najekstremnijih rezultata iznad centra distribucije. Prema konvenciji, ovo uzimamo kao jedan od pragova ekstremnosti rezultata.
Zašto 2.5%? Zato što je 5% najekstremnijih rezultata podeljeno na dva dela, levo i desno od centra distribucije.
Zašto baš ovakav prag? Ne postoji čvrst teorijski razlog - reč je o praktičnoj konvenciji koja se zasniva na činjenici da dve standardne devijacije obuhvataju približno 95% svih rezultata u normalnoj distribuciji. Ova konvencija se pokazala korisnom i efikasnom u statističkom zaključivanju tokom proteklog veka.
Postoji i pragmatičniji pristup oceni ekstremnosti rezultata kroz p-vrednost. P-vrednost predstavlja verovatnoću dobijanja rezultata koji je jednak ili ekstremniji od onog koji smo dobili u našem uzorku. Kada je p-vrednost manja od 5% (ili 0.05), smatramo da je rezultat prešao prag ekstremnosti o kojem smo malopre govorili.
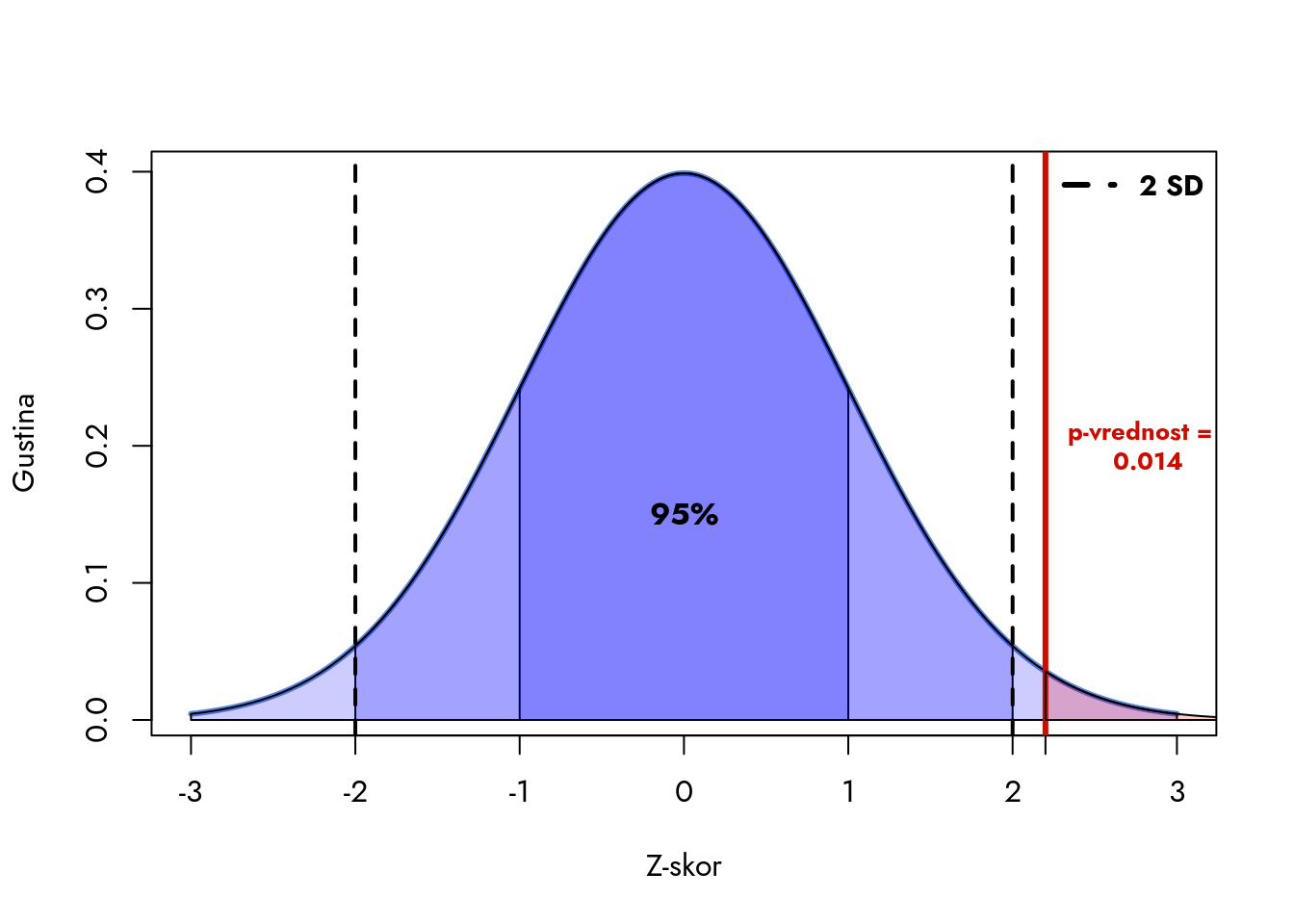
Da bismo ovo ilustrovali, razmotrimo jednostavan primer. Pretpostavimo da imamo rezultat aritmetičke sredine uzorka koji je udaljen 2.2 standardne greške od centra distribucije, ne ulazeći u detalje o izvoru podataka.
Izračunavamo gustinu distribucije za svaku vrednost Z-skor.
3
Crtamo grafikon gustine distribucije.
4
Postavljamo oznake na x-osi.
5
Prikazujemo regione statističke značajnosti kao osenčene oblasti.
6
p-vrednost dobijamo kada od 1 (ukupna verovatnoća) oduzmemo verovatnoću da se u distribucij nalazi rezultat koji je manji ili jednak 2.2
Slika 7.1: Primer p-vrednosti
Rezultat, tj. z-skor 2.2, prikazan je crvenom linijom. Površina ispod krive distribucije koja je ekstremnija od ovog rezultata označena je crvenom bojom (desni rep). Ova osenčena površina predstavlja p-vrednost. Što je p-vrednost manja, to je rezultat ekstremniji jer se nalazi u oblasti retkih vrednosti, tj. u repovima distribucije.
Suština statističkog zaključivanja je donošenje zaključaka o populaciji na osnovu informacija iz uzorka. P-vrednost nam govori koliko je verovatno da dobijemo ovakav ili ekstremniji rezultat ako je naša pretpostavka o populaciji tačna. Kada je naš rezultat u oblasti ekstremnih vrednosti, to nam sugeriše da početna pretpostavka verovatno nije tačna. Nasuprot tome, ako se rezultat našeg uzorka nalazi u središnjem delu distribucije, odnosno u oblasti očekivanih vrednosti, nemamo dovoljno dokaza da sumnjamo u početnu pretpostavku.
Statističko zaključivanje je proces donošenja odluka zasnovan na pretpostavkama i podacima iz uzorka. Dva osnovna oblika statističkog zaključivanja su testiranje nulte hipoteze i konstrukcija intervala poverenja.
Vratimo se na naš primer sa zaradom - kroz njega ćemo detaljnije objasniti proces testiranja hipoteza i koncept statističke značajnosti.
7.2 Testiranje hipoteza
Početna pretpostavka u našem prethodnom primeru bila je da prosečna zarada građana Srbije iznosi 1000 EUR. Ova pretpostavka naziva se nulta hipoteza i označava se sa \(H_0\). Nulta hipoteza predstavlja polaznu pretpostavku o vrednosti parametra populacije koju proveravamo pomoću statističkog testa. Statistički testovi kombinuju informacije iz nulte hipoteze sa informacijama iz uzorka na način koji nam omogućava donošenje odluke na kraju testa.
Princip testiranja je sličan kao u drugim oblastima istraživanja. Uzmimo za primer brzi COVID test u medicini. Početno ili nulto stanje testa je negativno. Kada test dođe u kontakt sa uzorkom krvi pacijenta, dobijamo informaciju koja nas zanima: ili je početno stanje potvrđeno - pacijent je negativan na COVID, ili je test opovrgnuo početno stanje i pokazao da je pacijent pozitivan. Da bi se opovrgnulo početno stanje, mora postojati dovoljno jak signal u uzorku krvi. Drugim rečima, koncentracija virusa mora preći određeni prag značajnosti (ili ekstremnosti) da bismo zaključili da je pacijent inficiran. U statističkom testiranju, taj signal nazivamo statistička značajnost.
Vratimo se na naš primer. Nultu hipotezu možemo zapisati ovako:
\[
H_0: \mu = 1000
\]
Šta je alternativa ovoj pretpostavci? Ako prosečna zarada građana Srbije nije 1000 EUR, onda je logična alternativa da je prosečna zarada različita od 1000 EUR. Ovu pretpostavku nazivamo alternativnom hipotezom i označavamo je sa \(H_1\).
\[
H_1: \mu \neq 1000
\]
Međutim, ovakav oblik alternativne hipoteze nije naročito informativan. Zamislite situaciju gde na konferenciji ili poslovnom sastanku predstavljate rezultat koji kaže samo da prosečna zarada u Srbiji nije 1000 EUR. Nastavićemo sa ovakvom alternativnom hipotezom, ali ćemo kasnije razmotriti i drugi, informativniji pristup.
Osnovna ideja testiranja nulte hipoteze je donošenje odluke - možemo li je odbaciti ili ne. Odbacivanje nulte hipoteze znači da smo u uzorku pronašli dovoljno jak signal koji ukazuje na njenu netačnost. Takav rezultat nazivamo statistički značajnim. Ako signal nije dovoljno jak, nultu hipotezu ne možemo odbaciti.
Jednostavnije rečeno: statistički značajan rezultat je onaj koji nam omogućava odbacivanje nulte hipoteze.
Šta je zapravo taj signal? To je informacija iz uzorka - konkretno, aritmetička sredina uzorka pretvorena u Z-skor. Z-skor meri udaljenost aritmetičke sredine uzorka od centra distribucije, izraženu kroz broj standardnih grešaka. Veliki Z-skor ukazuje da je aritmetička sredina uzorka ekstremna u odnosu na predviđanja nulte hipoteze.
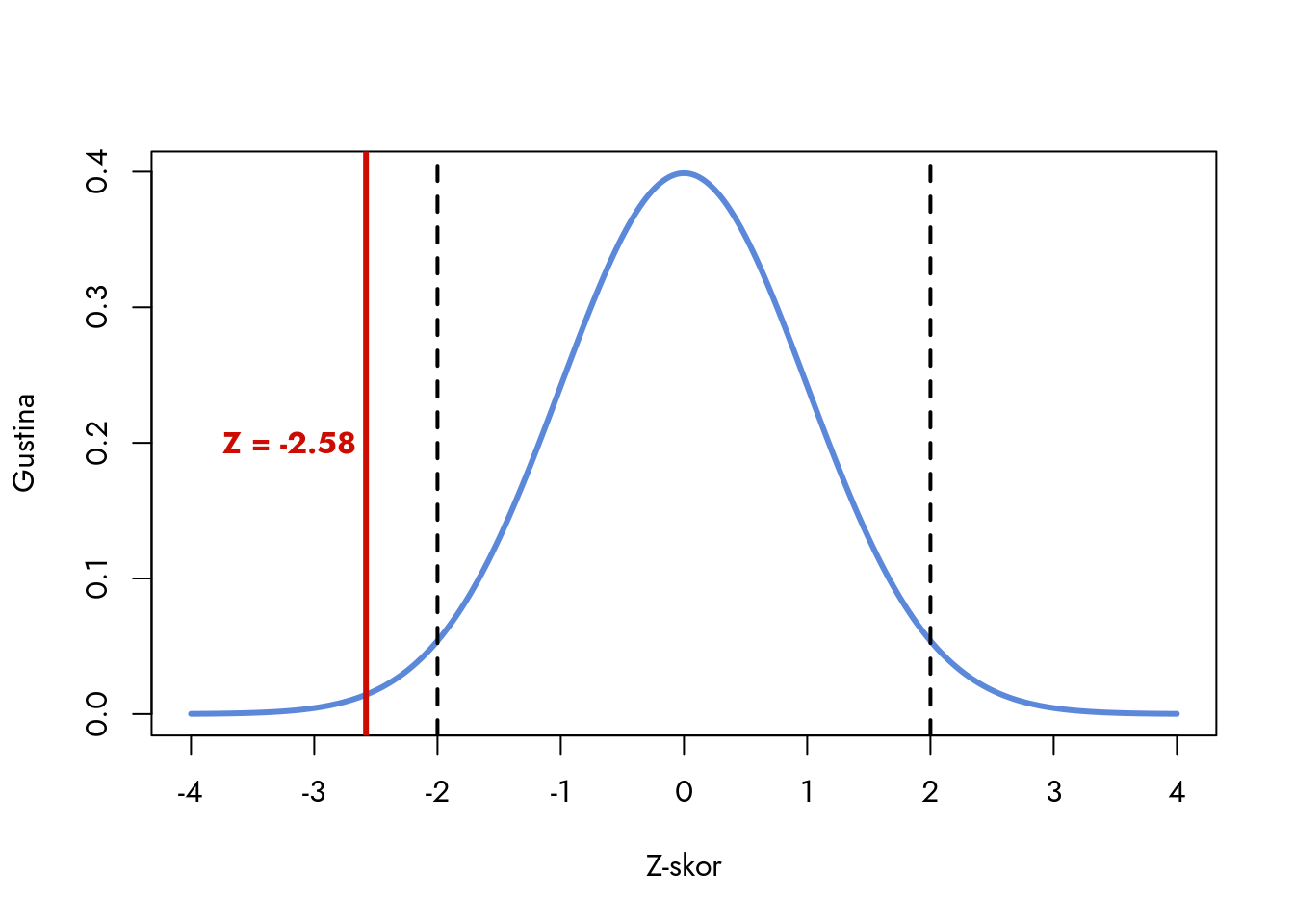
U našem primeru, prosečna zarada u uzorku iznosi 799.8 EUR, sa Z-skorom od -2.58. Prikažimo ovaj rezultat na standardizovanom normalnom rasporedu.
Crtamo crvenu liniju koja označava Z-skor našeg rezultata.
2
Dodajemo oznaku za Z-skor.
3
Dodajemo isprekidane linije koje označavaju granice regiona statističke značajnosti.
Slika 7.2: Standardizovani normalni raspored sa rezultatom iz uzorka
Kada posmatramo standardizovani normalni raspored, njegova sredina je uvek 0 i predstavlja informaciju iz nulte hipoteze. Ako je nulta hipoteza tačna, informacija iz uzorka (naš Z-skor) trebalo bi da se nađe blizu sredine distribucije, na udaljenosti do dve standardne greške od centra (isprekidane linije na grafikonu). Na grafikonu vidimo da je naš rezultat ekstreman i nalazi se u oblasti retkih vrednosti.
Ovo možemo numerički potvrditi izračunavanjem p-vrednosti za naš rezultat. P-vrednost predstavlja površinu ispod krive distribucije koja odgovara rezultatima ekstremnijim od našeg.
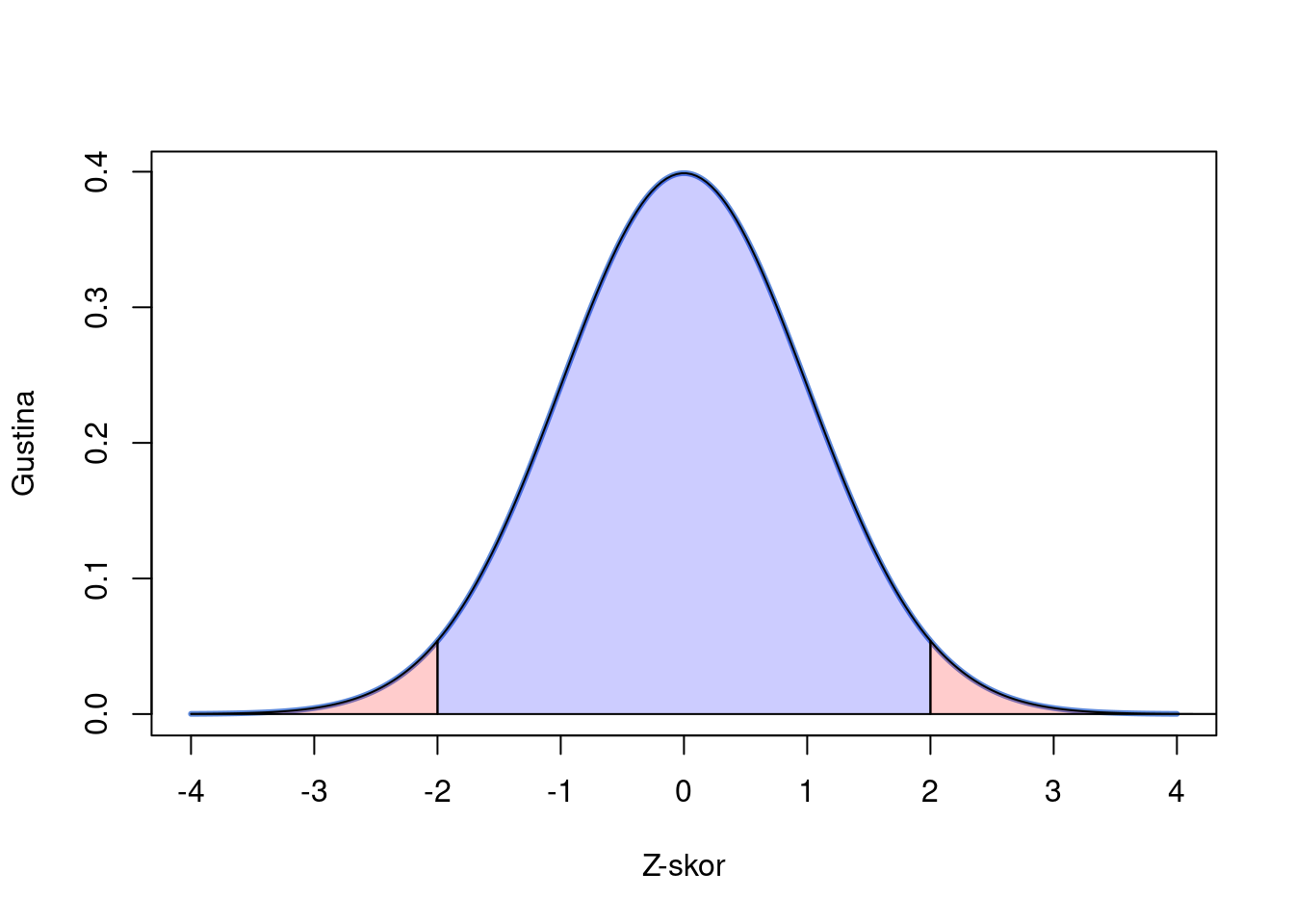
Šta znači „ekstremniji“ rezultat? Odgovor zavisi od oblika nulte hipoteze postavljene na početku testiranja. U slučaju naše nulte hipoteze (\(\mu = 0\)), rezultat se smatra ekstremnim ako je značajno manji ili značajno veći od nule. Zbog toga se regioni statističke značajnosti nalaze sa obe strane isprekidanih linija na grafikonu. Oni zajedno čine 5% najekstremnijih rezultata u distribuciji.
Slika 7.3: Oblasti ispod krive standardizovanog normalnog rasporeda
Plava oblast prikazuje rezultate koji su u skladu sa nultom hipotezom - to su očekivane vrednosti. Crvena oblast obuhvata ekstremne rezultate koji značajno odstupaju od nulte hipoteze. Da bismo odredili gde se naš rezultat nalazi u odnosu na ove oblasti, možemo izračunati p-vrednost bez potrebe za grafičkim prikazom.
P-vrednost predstavlja verovatnoću koja se dobija izračunavanjem površine ispod krive distribucije. Ovaj proces zahteva kompleksno numeričko integraljenje koje prepuštamo računaru. U R-u to radimo na sledeći način:
Prikaži kod
p_vrednost <-pnorm(-2.58)*2round(p_vrednost,3)
1
P-vrednost računamo kao verovatnoću da dobijemo rezultat manji ili jednak -2.58, pomnoženu sa 2 jer posmatramo regione značajnosti i sa leve i sa desne strane centra distribucije.
2
Zaokružujemo p-vrednost na 3 decimale.
[1] 0.01
P-vrednost iznosi 0.01, odnosno 1%. Šta nam to govori? Ako je nulta hipoteza tačna, verovatnoća da na slučajnom uzorku ove veličine dobijemo ovakav rezultat (prosečnu zaradu od 800 EUR) je samo 1%. Ovo je izuzetno mala verovatnoća, što ukazuje da je naš rezultat ekstreman u odnosu na predviđanja nulte hipoteze. Po konvenciji, ekstremnim rezultatima smatramo sve one čija je p-vrednost manja od 0.05, odnosno 5% (pravilo dve sigme).
Ovakav rezultat nas navodi da odbacimo nultu hipotezu i prihvatimo alternativnu: prosečna primanja građana Srbije (prosek na nivou populacije) nisu jednaka 1000 EUR. Odstupanje našeg rezultata od nulte hipoteze je jednostavno preveliko da bismo je zadržali.
TipKako smo došli do ove formule za p-vrednost?
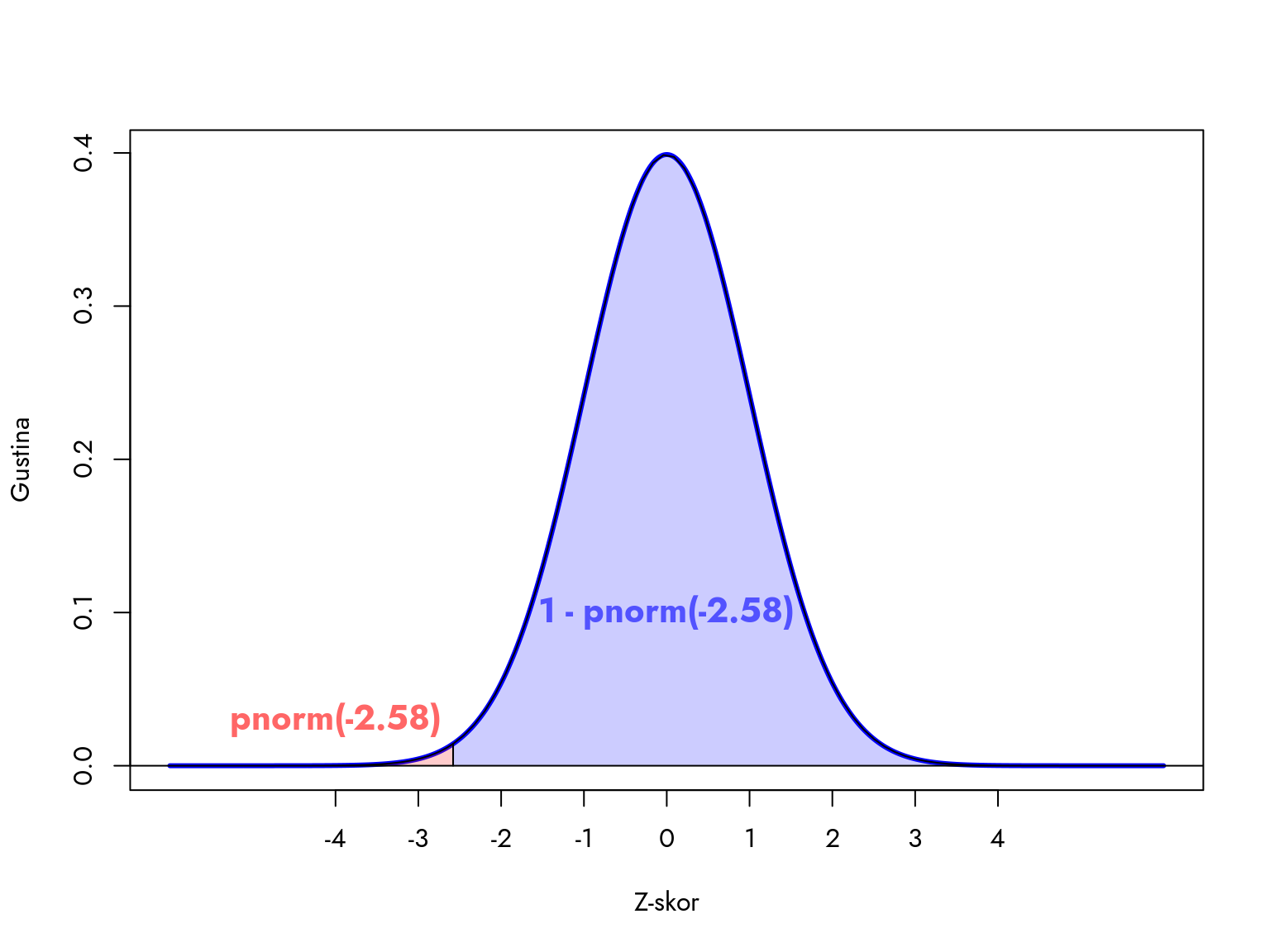
Da bismo razumeli izraz pnorm(-2.58)*2, rastavićemo ga na osnovne komponente.
Najlakše ćemo shvatiti šta se događa u ovoj formuli ako analiziramo još jedan grafički prikaz normalne distribucije.
Slika 7.4: P-vrednost kao površina ispod krive
Crvena oblast pokazuje površinu ispod krive distribucije za vrednosti manje ili jednake -2.58. To je verovatnoća dobijanja rezultata manjeg ili jednakog -2.58. Plava oblast predstavlja 1 minus ta verovatnoća, odnosno površinu ispod krive za vrednosti veće od -2.58. Mi želimo da izračunamo verovatnoću dobijanja ekstremnog rezultata - bilo manjeg od -2.58 ili većeg od 2.58. Zato množimo površinu sa 2, da bismo obuhvatili ekstremne rezultate na obe strane centra distribucije.
Funkcija pnorm() u R-u izračunava površinu ispod krive distribucije od minus beskonačno do zadate tačke.
NoteKoraci testiranja hipoteza
U ovom primeru smo uradili Z-test za proveru hipoteze o aritmetičkoj sredini. Iako se ovaj test retko koristi u praksi jer zahteva poznavanje standardne devijacije populacije (što je uglavnom nepoznato), on predstavlja odličnu osnovu za razumevanje testiranja hipoteza i koncepta statističke značajnosti.
Proces testiranja hipoteza možemo svesti na pet ključnih koraka:
Postavljanje nulte hipoteze \(H_0\) i alternativne hipoteze \(H_1\)
Izračunavanje aritmetičke sredine i standardne greške uzorka
Standardizacija aritmetičke sredine u Z-skor (statistika testa)
Računanje p-vrednosti
Donošenje zaključka: ako je p-vrednost < 0.05, odbacujemo nultu hipotezu; u suprotnom, nemamo dovoljno dokaza za njeno odbacivanje
Jednostavno ali moćno - ovih pet koraka čine srž procesa koji je revolucionirao način na koji donosimo zaključke na osnovu podataka.
TipNivoi značajnosti
„Standardni“ nivo značajnosti u statističkom zaključivanju iznosi 0.05. Ova vrednost predstavlja granicu za ekstremne rezultate, koja se nalazi na udaljenosti od 2 standardne greške od centra distribucije.
U praksi često koristimo i druge nivoe značajnosti, kao što su 0.01 ili 0.10. Izbor nivoa značajnosti zavisi od konteksta istraživanja i stepena sigurnosti koji želimo da postignemo u zaključivanju. Veći nivo značajnosti (recimo 0.10) povećava verovatnoću odbacivanja nulte hipoteze. Istovremeno, to povećava i rizik da odbacimo nultu hipotezu kada je ona zapravo tačna. O ovoj vrsti rizika detaljnije ćemo govoriti u odeljku o greškama tipa I i tipa II.
7.2.1 Jednostrane i dvostrane hipoteze
Primer koji smo obradili predstavlja dvosmernu nultu i alternativnu hipotezu. Zašto dvosmernu? Zato što se nulta hipoteza može odbaciti sa obe strane, a region statističke značajnosti je podeljen na dve oblasti u levom i desnom repu distribucije. Kao što smo ranije naveli, ovakav oblik hipoteze nije posebno informativan kada je u pitanju aritmetička sredina, jer je zaključak „prosek nije jednak 1000 EUR“ previše uopšten.
Razmotrimo sada drugačiji, precizniji oblik nulte i alternativne hipoteze:
Ovaj oblik hipoteza je jednostran jer nultu hipotezu možemo odbaciti samo sa jedne strane. Region statističke značajnosti nalazi se samo levo od centra distribucije. Pre nego što prikažemo grafički prikaz, razmotrimo logiku ovakvog pristupa.
Nulta hipoteza mora sadržati relaciju jednakosti kako bismo mogli centrirati normalnu distribuciju oko određene vrednosti - u ovom slučaju 1000 EUR. Dakle, nulta hipoteza pretpostavlja da je prosek populacije 1000 ili više. Alternativna hipoteza, suprotno tome, pretpostavlja da je prosek manji od 1000 EUR.
Ovakve hipoteze nazivamo jednostranim jer nultu hipotezu možemo odbaciti samo sa jedne strane distribucije. Hajde da to vizuelno predstavimo.
Slika 7.5: Oblasti ispod krive standardizovanog normalnog rasporeda za jednostrane hipoteze
Plava oblast označava prihvatanje nulte hipoteze, dok crvena oblast predstavlja njeno odbacivanje. Desni rep sada pripada oblasti prihvatanja nulte hipoteze jer visoka aritmetička sredina uzorka (značajno veća od 1000 EUR) potvrđuje nultu hipotezu koja tvrdi da je prosek 1000 EUR ili više.
Naš rezultat iz uzorka ostaje -2.58, ali p-vrednost se menja jer računamo površinu ispod krive distribucije samo za vrednosti manje od -2.58. Razlog je jednostavan - region značajnosti se nalazi samo sa leve strane centra distribucije, pa ne množimo vrednost sa 2.
P-vrednost za jednostrane hipoteze računamo kao verovatnoću da dobijemo rezultat manji ili jednak -2.58.
2
Zaokružujemo p-vrednost na 3 decimale.
[1] 0.005
P-vrednost je, kao što smo očekivali, dva puta manja. Odbacivanje nulte hipoteze je sada jednostavnije jer posmatramo samo jedan deo distribucije. P-vrednost iznosi 0.005, odnosno 0.5%. Ovaj rezultat je i dalje ekstreman, što nas vodi do odbacivanja nulte hipoteze.
Ono što je posebno važno jeste da je sada zaključak mnogo informativniji: „prosečna zarada u Srbiji je ispod 1000 EUR“. Ovakav zaključak je toliko jasan i direktan da ga lako možete zamisliti kao naslov na nekom internet portalu.
NoteLična karta metoda: Z-test za aritmetičku sredinu
Šta radi? Ispituje da li se aritmetička sredina uzorka značajno razlikuje od pretpostavljene aritmetičke sredine populacije (nulte hipoteze).
Kada se koristi? U situacijama kada poznajemo standardnu devijaciju populacije i želimo da proverimo da li se aritmetička sredina uzorka statistički značajno razlikuje od početne pretpostavke.
Koliko varijabli analiziramo? Jednu kvantitativnu varijablu (\(X\)). Ona može biti merena intervalnom ili racio skalom. U određenim slučajevima, prihvatljiva je i ordinalna varijabla.
Kako formulišemo hipoteze? Ako označimo pretpostavljenu vrednost aritmetičke sredine populacije sa \(\mu_0\), hipoteze možemo formulisati kao dvosmerne ili jednosmerne.
Kako izgleda statistika testa? Statistika testa je Z-skor koji se računa kao:
\[
Z = \frac{\bar{X} - \mu_0}{\frac{\sigma}{\sqrt{n}}}
\]
gde je \(\bar{X}\) aritmetička sredina uzorka, \(\mu_0\) pretpostavljena vrednost aritmetičke sredine populacije, \(\sigma\) standardna devijacija populacije i \(n\) veličina uzorka.
Kako računamo p-vrednost? Za dvostrani test, p-vrednost je jednaka dvostrukoj površini ispod krive distribucije za vrednosti manje ili veće od Z-skora, u zavisnosti od toga da li je on negativan ili pozitivan.
Za jednostrani test, p-vrednost predstavlja površinu ispod krive distribucije za vrednosti manje od Z-skora (kada je Z negativan) ili veće od Z-skora (kada je Z pozitivan).
Kako donosimo zaključak? Kada je p-vrednost manja od nivoa značajnosti (najčešće 0.05), odbacujemo nultu hipotezu. U suprotnom slučaju, nemamo dovoljno dokaza da odbacimo nultu hipotezu.
7.3 Greške pri testiranju hipoteza
Kao i kod svakog procesa donošenja odluka, suočavamo se sa rizikom pogrešnog izbora. Isto važi i za statističko testiranje. Odbacivanje nulte hipoteze nosi rizik greške, baš kao što i njeno prihvatanje može biti pogrešno. Jedinstvena prednost statističkog zaključivanja leži u tome što možemo precizno kvantifikovati verovatnoće ovih grešaka, čineći naše zaključke jasnijim i pouzdanijim.
Za ilustraciju ovih grešaka, počnimo sa jednostavnim primerom van statistike — testovima za trudnoću.
Ovi testovi detektuju hormon hCG u urinu. U normalnim okolnostima, ovaj hormon nije prisutan kod muškaraca i žena koje nisu trudne. Ipak, u retkim slučajevima, kod obe grupe mogu se javiti minimalne koncentracije ovog hormona. To znači da je očekivana vrednost (prosek) 0, ali prirodne varijacije mogu proizvesti veoma niske, ne-nulte vrednosti — ovo je izvor varijabiliteta. Test daje pozitivan rezultat samo kada koncentracija hormona pređe određeni prag. Koncentracije ispod tog praga rezultiraju negativnim testom. Ovaj mehanizam direktno odgovara konceptu statističke značajnosti.
Razmotrimo test na dva subjekta:
trudnu ženu
muškarca kao kontrolni subjekt
Za oba subjekta moguća su dva ishoda testa: pozitivan i negativan. Pogledajmo rezultate u sledećoj tabeli.
Osoba
Test
Zaključak
Interpretacija
Trudnica
Pozitivan
Tačno
Ispravan rezultat
Muškarac
Pozitivan
Greška
Lažno pozitivan test
Trudnica
Negativan
Greška
Lažno negativan test
Muškarac
Negativan
Tačno
Ispravan rezultat
U dve situacije doneli smo pogrešan zaključak. U prvom slučaju, test je pokazao pozitivan rezultat kod muškarca, iako trudnoća nije moguća. Ovo je lažno pozitivan test. U drugom slučaju, test je pokazao negativan rezultat kod trudnice, iako je trudna. Ovo je lažno negativan test.
Kod lažno pozitivnog testa, prag za pozitivan rezultat je često postavljen prenisko. To znači da test detektuje čak i minimalne koncentracije hormona, koje se prirodno javljaju kod muškaraca ili žena koje nisu trudne. Podizanjem praga za pozitivan rezultat smanjuje se verovatnoća lažno pozitivnih rezultata i povećava specifičnost testa.
Specifičnost testa predstavlja njegovu sposobnost da pravilno identifikuje osobe koje nemaju stanje koje se testira - u ovom slučaju, da razlikuje ne-trudnoću od trudnoće. Što je test specifičniji, to bolje izbegava lažno pozitivne rezultate.
U drugom slučaju, kod lažno negativnog testa, granica za pozitivan rezultat je postavljena previsoko. To znači da test možda neće detektovati ni prisustvo hormona kod trudnice ako je njegova koncentracija ispod te visoke granice. Snižavanjem praga za pozitivan rezultat smanjuje se verovatnoća dobijanja lažno negativnih rezultata i povećava se osetljivost testa.
Osetljivost testa je njegova sposobnost da pravilno identifikuje osobe koje imaju stanje koje se testira - u ovom slučaju, da potvrdi trudnoću kod trudnica. Što je test osetljiviji, to je bolji u otkrivanju stvarnih pozitivnih slučajeva i smanjivanju lažno negativnih rezultata.
Međutim, nema besplatnog ručka - povećanje osetljivosti često dolazi na račun specifičnosti. To znači da postoji neizbežan kompromis između osetljivosti i specifičnosti testa. Granicu za pozitivan rezultat treba pažljivo podesiti kako bi se postigao optimalan balans koji će svesti na minimum i lažno pozitivne i lažno negativne rezultate. Ne postoji savršen test koji će biti 100% osetljiv i 100% specifičan.
Vratimo se sada na statističko zaključivanje i razmotrimo greške koje možemo napraviti pri testiranju hipoteza.
Nulta hipoteza predstavlja negativan rezultat testa, slično situaciji kada osoba nije trudna i kada je koncentracija hormona jednaka nuli. Alternativna hipoteza odgovara pozitivnom rezultatu testa.
Lažno pozitivan test („muškarac je trudan“) u statističkom zaključivanju naziva se greška tipa I. To je situacija kada odbacimo nultu hipotezu iako je ona tačna. Jednostavnije rečeno, greška tipa I je pogrešno odbacivanje nulte hipoteze - vidimo signal tamo gde ga zapravo nema. Verovatnoću pravljenja greške tipa I označavamo sa \(\alpha\) i nazivamo je nivo značajnosti testa. Ovu vrednost smo već spominjali - ona je standardno postavljena na 0.05 i predstavlja prag za donošenje odluke o odbacivanju nulte hipoteze.
Lažno negativan test („trudnica nije trudna“) u statističkom zaključivanju nazivamo greškom tipa II. To je situacija kada prihvatimo nultu hipotezu iako je ona netačna. Jednostavnije rečeno, greška tipa II nastaje kada ne vidimo signal koji zaista postoji. Verovatnoću pravljenja greške tipa II označavamo sa \(\beta\). Za razliku od \(\alpha\), beta nije fiksna vrednost - ona zavisi od nekoliko faktora, uključujući veličinu uzorka, jačinu efekta koji pokušavamo da detektujemo i nivo značajnosti testa. O vrednosti \(\beta\) i njenom značaju detaljnije ćemo govoriti u narednom poglavlju, kada budemo analizirali snagu testa.
7.4 Intevali poverenja
Pređimo sada na drugi pristup statističkom zaključivanju. Testiranje hipoteza možemo posmatrati kao binarni proces: nultu hipotezu ili odbacujemo ili ne odbacujemo. Analiziramo da li se informacija iz uzorka nalazi u regionu značajnosti, procenjujući verovatnoću retkih događaja unutar distribucije.
Rezultat testiranja može biti informativan („Prosečna zarada u Srbiji je ispod 1000 EUR“), ali ponekad je i previše uopšten („Prosečna zarada u Srbiji nije jednaka 1000 EUR“). Zamislite da takav zaključak prezentujete na sastanku. Koje bi bilo prvo pitanje koje biste čuli? Verovatno: „U redu, ako je manja od 1000, koliko tačno iznosi?“.
Tačan i sasvim precizan odgovor na ovo pitanje ne možemo dati jer radimo sa podacima iz uzorka. Međutim, možemo napraviti procenu proseka na nivou populacije na osnovu podataka iz uzorka. Ova procena se naziva interval poverenja. Ilustrujmo ovo primerom: „Sa 95% pouzdanosti možemo reći da se prosečna zarada u Srbiji kreće između 750 i 850 EUR“. Ovo je primer rezultata statističkog zaključivanja koji nije zasnovan na testiranju hipoteza, već pripada oblasti statističkog ocenjivanja. Hajde da vidimo kako možemo konstruisati ovakav interval.
7.4.1 Konstrukcija intervala poverenja
Vratimo se na naš primer. Na uzorku od 60 ispitanika istraživali smo zarade građana Srbije. Nakon obrade podataka dobili smo prosečnu zaradu od 799.8 EUR, sa standardnom devijacijom 600 EUR. Pošto je uzorak dovoljno veliki, možemo pretpostaviti da je standardna devijacija uzorka približno jednaka standardnoj devijaciji populacije.
Šta nam ovi podaci omogućavaju da izračunamo? Prvo ćemo izračunati standardnu grešku aritmetičke sredine koristeći formulu:
\[
s_{\overline{X}} = \frac{s}{\sqrt{n}}
\]
U R-u to izgleda ovako:
Prikaži kod
s <-600n <-60s_x <- s/sqrt(n)round(s_x, 2)
1
Unosimo vrednosti standardne devijacije i veličine uzorka.
2
Računamo standardnu grešku aritmetičke sredine prema formuli.
[1] 77.46
Šta možemo da uradimo sa standardnom greškom? Vratimo se na analizu normalne distribucije aritmetičkih sredina. Kod testiranja hipoteza, u centar te distribucije postavili smo vrednost iz nulte hipoteze (1000 EUR) i posmatrali verovatnoću da se naša vrednost iz uzorka nalazi u regionu značajnosti.
Međutim, sada ne znamo koja je aritmetička sredina populacije. Zato ćemo analizirati granične slučajeve.
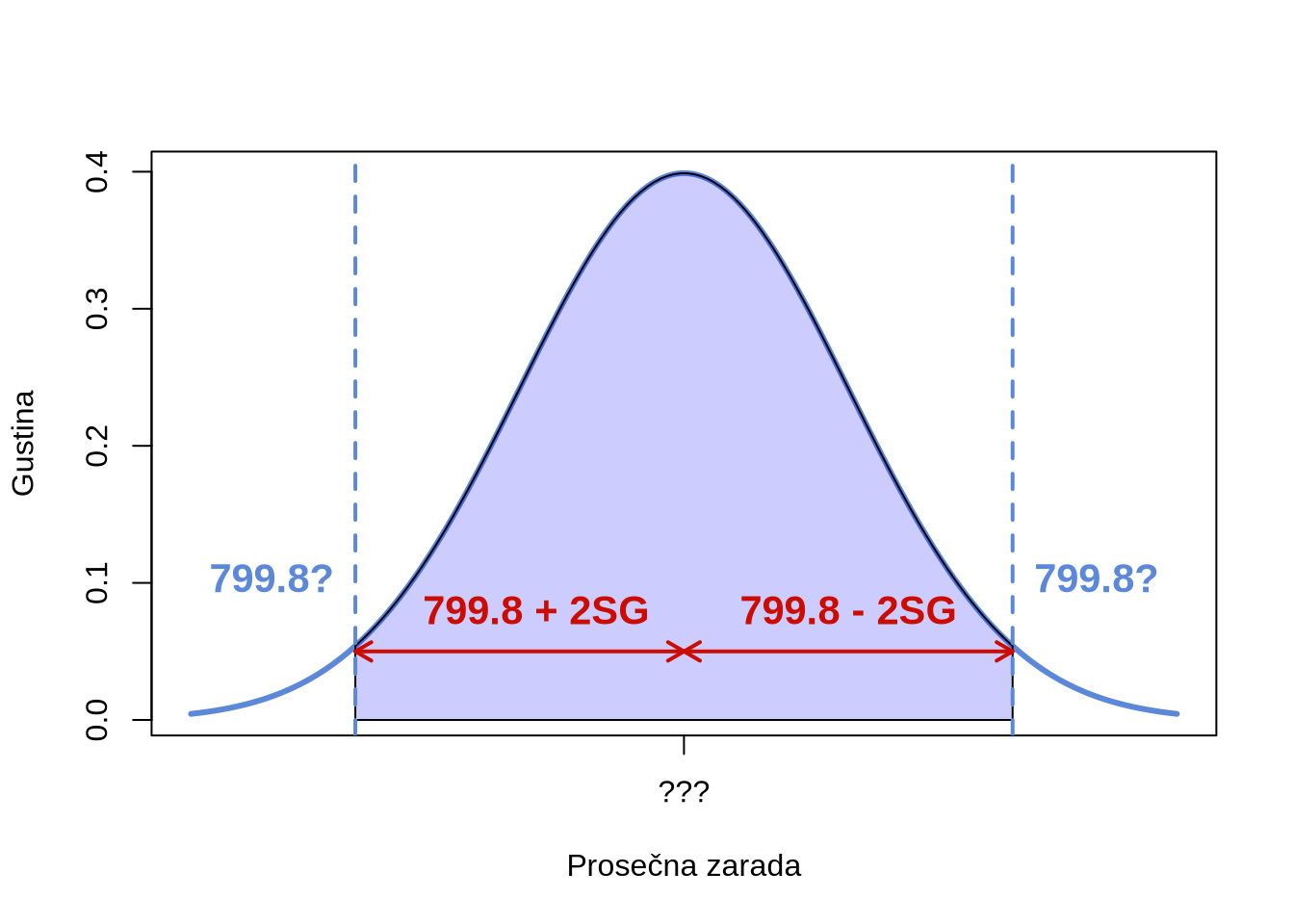
Ako pretpostavimo da se vrednost iz našeg uzorka nalazi unutar 95% vrednosti koje okružuju centar distribucije, koji su granični slučajevi? To su vrednosti udaljene približno 2 standardne greške od centra distribucije. Ove vrednosti nazivamo kritičnim vrednostima. Hajde da to vizuelno prikažemo.
Kritične vrednosti za Z distribuciju
Plave isprekidane linije označavaju granične slučajeve za aritmetičku sredinu. Pretpostavljamo da ona može odstupati najviše dve standardne greške od izmerene vrednosti. Sa ovom pretpostavkom možemo izračunati interval poverenja. Crvene linije nam pokazuju moguće pozicije aritmetičke sredine populacije.
Konstruisanjem intervala oko ovih vrednosti možemo „uhvatiti“ pravu aritmetičku sredinu populacije. Iako ne znamo tačnu vrednost, ona će biti obuhvaćena ovim intervalom ako je naša početna pretpostavka ispravna.
Interval poverenja se računa prema formuli:
\[
\overline{X} \pm Z \cdot s_{\overline{X}}
\]
ili
\[
\overline{X} - Z \cdot s_{\overline{X}} \leq \mu \leq \overline{X} + Z \cdot s_{\overline{X}}
\]
gde su:
\(\overline{X}\) - aritmetička sredina uzorka
\(s_{\overline{X}}\) - standardna greška aritmetičke sredine
\(Z\) - kritična vrednost za normalnu distribuciju (u našem slučaju 2)
\(\mu\) - aritmetička sredina populacije
U R-u to izgleda ovako:
Prikaži kod
Z <-2donja_granica <-799.8- Z * s_xgornja_granica <-799.8+ Z * s_xinterval_poverenja <-c(donja_granica, gornja_granica)cat("Intervala poverenja je od ", interval_poverenja[1], " do ", interval_poverenja[2], " EUR.")
1
Postavljamo kritičnu vrednost na 2.
2
Računamo donju i gornju granicu intervala poverenja.
3
Spajamo ove dve granice u vektor koji predstavlja interval poverenja.
4
Ispisujemo interval poverenja.
Intervala poverenja je od 644.8807 do 954.7193 EUR.
Kritična vrednost od 2 označava da smo konstruisali interval poverenja od približno 95%. Na osnovu toga možemo zaključiti da se, sa 95% pouzdanosti, prosečna zarada u Srbiji nalazi između 644.88 i 954.72 EUR.
Ovaj interval nam pruža realnu sliku o mogućem opsegu prosečne zarade u populaciji. Primetićete da interval nije naročito precizan, što je direktna posledica relativno visoke standardne greške koja proizilazi iz male veličine uzorka. Veći uzorak bi doveo do manje standardne greške, što bi rezultiralo užim i preciznijim intervalom poverenja.
NotePogrešna interpretacija intervala poverenja
Kada govorimo o intervalima poverenja, u udžbenicima statistike često se sreću određene zablude. Jedna od njih je poređenje sa testiranjem hipoteza, gde se tvrdi da intervali poverenja, za razliku od testiranja hipoteza, ne polaze od početne pretpostavke.
Ovo nije tačno. Konstrukcija intervala poverenja zapravo se zasniva na ključnoj pretpostavci - da se naš uzorak nalazi unutar centralnih 95% vrednosti distribucije (ili 99% ili 90%, zavisno od izabranog nivoa značajnosti). Ova pretpostavka je implicitna i ne moramo je formalno navoditi, ali je fundamentalna za ceo proces. Glavna razlika u odnosu na testiranje hipoteza je u tome što se ova pretpostavka ne proverava kroz sam statistički postupak.
Druga česta greška tiče se samog koncepta pouzdanosti. Često ćete čuti tvrdnje poput: „Verovatnoća da se aritmetička sredina populacije nalazi u ovom intervalu je 95%, a postoji verovatnoća od 5% da se ona nalazi izvan njega.“ Ovo nije tačno.
Vrednost koju smo dobili iz uzorka i na osnovu koje smo konstruisali interval poverenja predstavlja samo jednu od mogućih vrednosti iz populacije. Mi smo pretpostavili da se naš uzorak nalazi unutar centralnih 95% distribucije. Međutim, ne možemo obrnuti ovu logiku i tvrditi da se centar distribucije nalazi u intervalu oko naše vrednosti sa određenom verovatnoćom.
Evo ispravne interpretacije pouzdanosti: „Kada bismo ponovili uzorkovanje veliki broj puta i svaki put izračunali interval poverenja na isti način, u približno 95% slučajeva prava vrednost populacione sredine našla bi se unutar tog intervala.“
Ova interpretacija je složenija za razumevanje i često je ne naglašavamo jer je podrazumevana u samoj konstrukciji intervala poverenja. Ipak, važno je razumeti da je ovo precizna interpretacija pouzdanosti intervala poverenja.
U praksi je dovoljno reći da, na osnovu intervala poverenja od 95% pouzdanosti, prosečna zarada u Srbiji iznosi između 644.88 i 954.72 EUR. Interpretacija postaje kompleksnija kada shvatimo da je naš interval, nakon prikupljanja podataka i izračunavanja na osnovu jednog uzorka, zapravo fiksan - on je ili uspeo da obuhvati pravu vrednost populacije ili nije. Ne možemo proceniti verovatnoću tog uspeha na osnovu samo jednog uzorka.
Testiranje nulte hipoteze i konstrukcija intervala poverenja predstavljaju snažne alate za donošenje zaključaka o nepoznatim parametrima populacije. Izbor metoda zavisi od ciljeva istraživanja, a često se oba pristupa kombinuju kako bi zaključci bili precizniji i informativniji.
U svakodnevnom životu ne donosimo odluke na ovaj način, zbog čega nam statističko zaključivanje može delovati apstraktno i neprirodno. Ipak, ovakav pristup nam omogućava da jasno sagledamo granice naših zaključaka - granice koje proizilaze iz nepotpunih informacija - kao i rizik od pogrešnih odluka. To je fundamentalna razlika između statističkog i intuitivnog zaključivanja, i glavni razlog zašto je statistika postala nezaobilazan alat u savremenoj nauci i šire.
Naučna istraživanja često imaju za cilj identifikaciju specifičnih efekata ili uticaja: efikasnost neke intervencije, delotvornost leka, razlike između društvenih grupa ili povezanost između simptoma. U narednim poglavljima pokazaćemo kako se ovi ciljevi mogu ostvariti primenom statističkih testova i metoda ocenjivanja.
7.5 Zadaci
CautionZadatak 1
Novosadski vodovod saopštio je da je u uzorku od 150 merenja pijaće vode pronađena povišena koncentracija nitrata iz otpadnih voda. Koncentracija u uzorku iznosi 55 mg/L, dok je standardna devijacija 10 mg/L.
Maksimalna dozvoljena koncentracija nitrata u pijaćoj vodi je 50 mg/L. Vodovod tvrdi da nema razloga za zabrinutost i da je ovaj rezultat samo izolovani slučaj, te da je koncentracija nitrata u pijaćoj vodi u Novom Sadu i dalje na granici ili ispod nje.
Uzmimo ovu tvrdnju vodovoda kao nultu hipotezu i testiraćemo je na nivou značajnosti od 0.05.
Izračunajte Z-skor
Izračunajte p-vrednost
Testirajte nultu hipotezu
Pod pretpostavkom da je vodovod u pravu, kolika je verovatnoća da se ovakav uzorak pojavi slučajno?
CautionZadatak 2
Na uzorku od 750 domaćinstava u Srbiji utvrđeno je da je prosečan broj dece u domaćinstvu 1.2. Standardna devijacija populacije iznosi 0.5.
Proverite hipotezu da prosečno domaćinstvo u Srbiji ima najmanje jedno dete. Koristićemo nivo značajnosti 0.05.
Da biste odgovorili na ovo pitanje, potrebno je da:
Izračunate Z-skor
Izračunate p-vrednost
Vizuelno prikažete rezultat na grafikonu normalne distribucije koristeći kod iz poglavlja
CautionZadatak 3 *
Vratimo se na primer sa prosečnim zaradama u Srbiji i interval poverenja od 95% pouzdanosti. Dobili smo interval od 644.88 do 954.72 EUR.
Na vašoj prezentaciji rezultata, šefica/mentorka nije zadovoljna širinom ovog intervala. Potrebna joj je preciznija ocena prosečne zarade, sa maksimalnim odstupanjem od ±50 EUR u oba smera.
Odredite minimalnu veličinu uzorka potrebnu za postizanje ovog cilja. Koji interval poverenja očekujete da dobijete sa novim uzorkom?
Napomena: Budući da nije određen nivo pouzdanosti intervala, možete prilagoditi i taj parametar tokom analize.
Dodatni izazov: Umesto korišćenja postojeće aritmetičke sredine, simulirajte novu vrednost iz normalne distribucije aritmetičkih sredina pomoću funkcije rnorm().
CautionZadatak 4 *
Administrator jedne Instagram stranice želi da bolje razume svoju ciljnu grupu i ispita starost pratilaca. Na anketu o godinama odgovorilo je 132 pratioca. Prosečna starost je 28.2 godine, sa standardnom devijacijom (populacije) od 15.3 godine.
Konstruišite interval poverenja od 95% za prosečnu starost pratilaca stranice.
Konstruišite interval poverenja od 90% za prosečnu starost pratilaca stranice (Z vrednost za 90% je 1.64).
Administrator stranice planira da plati reklamu na Instagramu usmerenu ka određenoj starosnoj grupi. Dostupne opcije za ciljanje su: 18-24, 25-34, 35-44 godina. Na osnovu dobijenih intervala poverenja, koju starosnu grupu biste preporučili?
Analizirajte granice oba intervala. Kako biste opisali odnos između preciznosti i pouzdanosti intervala poverenja?
CautionZadatak 5 **
U našim ranijim razmatranjima naveli smo da oblast od +/- 2 standardne greške oko aritmetičke sredine obuhvata približno 95% vrednosti u distribuciji aritmetičkih sredina. Ova aproksimacija, iako korisna, nije potpuno precizna.
Hajde da pronađemo tačne vrednosti:
Izračunajte Z vrednost koja tačno definiše 95% vrednosti u distribuciji aritmetičkih sredina. Za ovo možete koristiti R funkciju qnorm().
Odredite Z vrednost koja definiše oblast koja obuhvata 99% vrednosti u distribuciji aritmetičkih sredina.
Konstruišite 99% intervale poverenja za aritmetičke sredine iz zadataka 2 i 4.