U prethodnom poglavlju smo ispitivali uticaj jedne varijable na drugu. Sada prelazimo na analizu odnosa između dve kvantitativne varijable. Istraživačko pitanje ostaje isto: postoji li uticaj nezavisne varijable na zavisnu varijablu? Međutim, metod kojim ispitujemo taj uticaj je drugačiji.
Razmotrimo konkretan primer. Imamo uzorak od 60 država sa dva ključna podatka:
godišnji budžet za zdravstvo po glavi stanovnika (u dolarima) i
ocenu kvaliteta zdravstvenog sistema (na skali od 1 do 100).
Najbolju ocenu zdravstvenog sistema dobila je Norveška (100), dok je najlošiju dobila Nigerija (29). Ocene su formirali međunarodni eksperti na osnovu više ključnih parametara. Naš zadatak je jasan - utvrditi vezu između budžeta za zdravstvo i kvaliteta zdravstvenog sistema. Preciznije, želimo odgovoriti na pitanje: imaju li države koje više ulažu u zdravstvo bolje zdravstvene sisteme?
Ovo je klasičan primer komparativne analize. Cilj nam je da ispitamo razlike u kvalitetu zdravstvenih sistema u odnosu na budžete koje države izdvajaju za zdravstvo. Međutim, za razliku od standardne komparativne analize gde poredimo jasno definisane grupe, ovde se suočavamo sa kontinuiranom skalom budžetskih vrednosti.
Krenimo od samih podataka.
Prikaži kod
podaci <-read.csv("https://gist.githubusercontent.com/atomashevic/1ea72e8ea912083492b60af7ecd07fbf/raw/7d658eb07d321126989acf774a8428dc712bfc9d/zdravstvo.csv")n <-nrow(podaci)cat("Broj opservacija:", n, "\n")min_budzet <-min(podaci$budzet)max_budzet <-max(podaci$budzet)cat("Min i max budzet:", min_budzet, max_budzet, "\n")min_kvalitet <-min(podaci$kvalitet)max_kvalitet <-max(podaci$kvalitet)cat("Min i max kvalitet:", min_kvalitet, max_kvalitet, "\n")X_budzet <-mean(podaci$budzet)X_kvalitet <-mean(podaci$kvalitet)cat("Prosečan budžet:", X_budzet, "\n")cat("Prosečan kvalitet:", X_kvalitet, "\n")
Broj opservacija: 60
Min i max budzet: 292.99 9922.57
Min i max kvalitet: 29 100
Prosečan budžet: 4893.517
Prosečan kvalitet: 64.58333
Imamo podatke za 60 država. Budžeti se kreću od oko 300 do skoro 10000 dolara po glavi stanovnika. Kvalitet zdravstvenog sistema varira od 29 do 100.
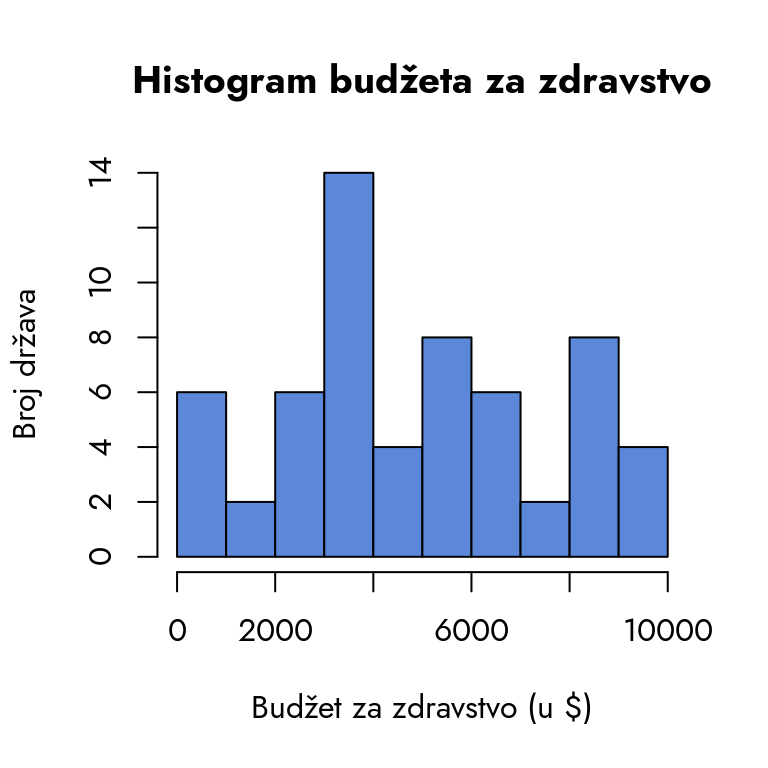
Da bismo bolje razumeli distribuciju budžeta, pogledajmo histogram.
Prikaži kod
par(family ="Jost")hist(podaci$budzet, breaks =10,main ="Histogram budžeta za zdravstvo",xlab ="Budžet za zdravstvo (u $)",ylab ="Broj država",col ="#5C88DAFF")
1
Crtamo histogram koji predstavlja varijablu izdeljenu u 10 intervala, tj. 9 kategorija.
Slika 9.1: Histogram budžeta za zdravstvo
Distribucija budžeta za zdravstvo nije normalna. Samo jedan interval, od 3000 do 4000 dolara, ima veći broj država, dok su frekvencije u ostalim intervalima ispod 10.
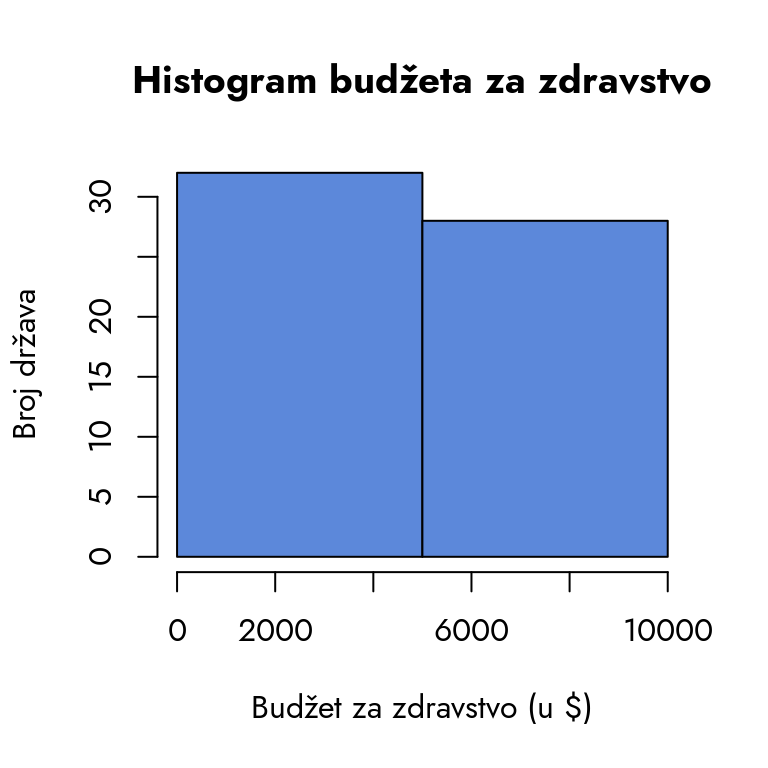
Jedan pristup bi bio da „kompresujemo“ ove intervale i napravimo 2-3 intervala sa većim frekvencijama. Na primer, mogli bismo podeliti države na one koje izdvajaju ispod i iznad 5000 dolara. To bi nam omogućilo da primenimo t-test i uporedimo ove dve grupe.
Prikaži kod
par(family ="Jost")hist(podaci$budzet, breaks =3,main ="Histogram budžeta za zdravstvo",xlab ="Budžet za zdravstvo (u $)",ylab ="Broj država",col ="#5C88DAFF")
1
Delimo podatke u 3 intervala, tj. dve kategorije.
Slika 9.2: Histogram dve kategorije budžeta za zdravstvo
Ipak, ovakav pristup dovodi do gubitka važnih informacija. Razmotrimo suštinu: postoji značajna razlika između država koje izdvajaju 100, 1000 ili 3000 dolara po glavi stanovnika za zdravstvo. Imamo precizne podatke o budžetima - zašto ih ne bismo iskoristili u punom obimu? Grupisanje u ovom slučaju ne samo da nije neophodno, već može biti i kontraproduktivno jer zamagljuje fine razlike između država.
9.2 2D analiza
Umesto grupisanja država, preciznije je analizirati svaku pojedinačno. Za svaku državu imamo dva kvantitativna podatka, što nam omogućava njihovo predstavljanje u dvodimenzionalnom koordinatnom sistemu. Na horizontalnoj osi prikazaćemo budžet za zdravstvo, a na vertikalnoj kvalitet zdravstvenog sistema. Svaka tačka u ovom prostoru predstavljaće jednu državu. Pogledajmo kako to izgleda:
Prikaži kod
par(family ="Jost")plot(podaci$budzet, podaci$kvalitet,xlab ="Budžet za zdravstvo (u $)",ylab ="Kvalitet zdravstvenog sistema",main ="Budžet za zdravstvo i kvalitet zdravstvenog sistema",col ="#CC0C00FF",pch =19)
1
Koristimo funkciju sa dva osnovna argumenta: prvi je vrednost za x-osu, a drugi za y-osu.
Slika 9.3: Dijagram raspršenosti
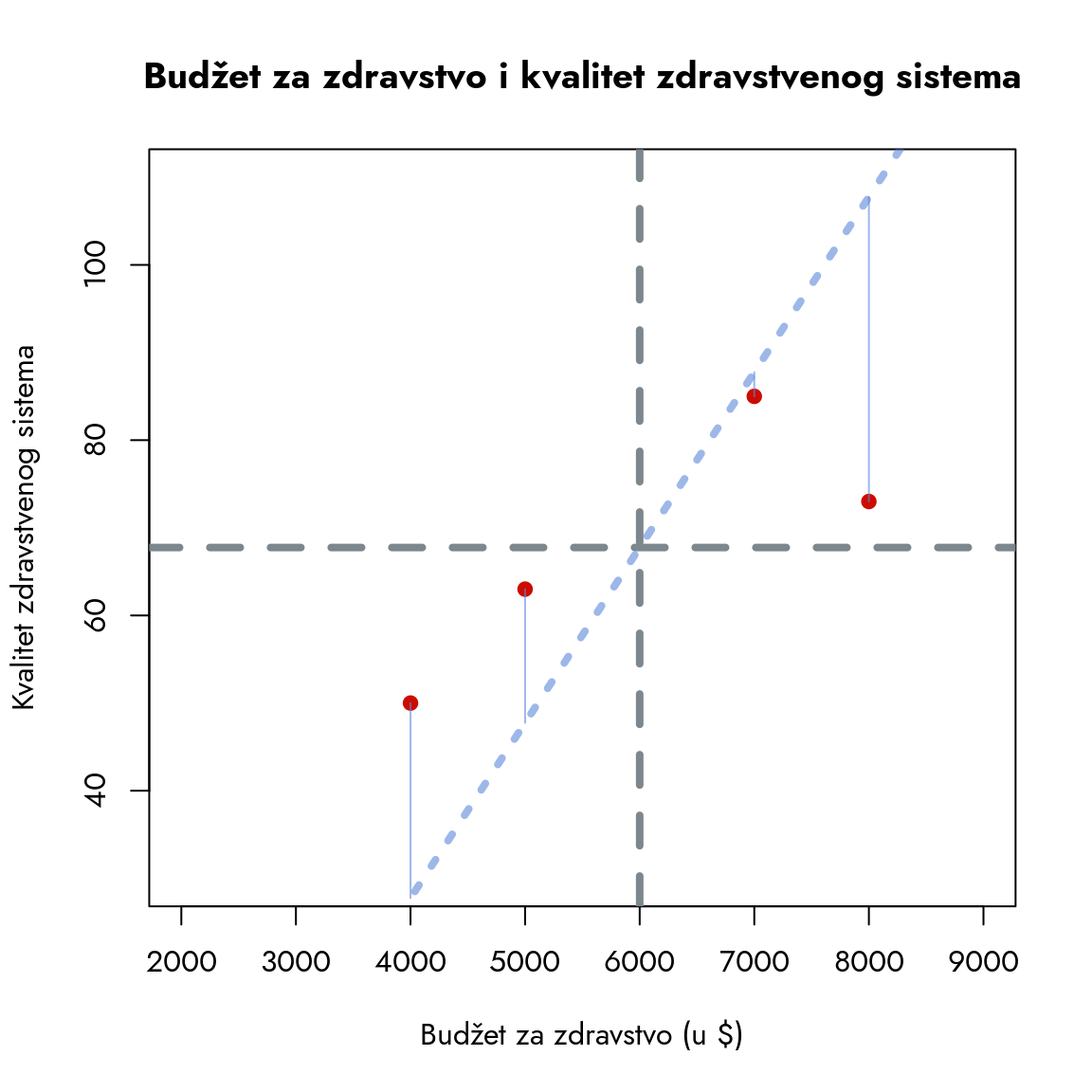
Ovaj grafikon se zove dijagram raspršenosti (eng. scatter plot). On prikazuje prostorni raspored dve varijable i njihov međusobni odnos. Na prvi pogled može delovati složen, ali postaje jasniji kada razumemo njegovu logiku.
Hajde da analiziramo šta nam dijagram govori:
U donjem levom uglu nalazi se grupa od pet država. One imaju izrazito nizak budžet za zdravstvo i loše ocene kvaliteta zdravstvenog sistema.
Centralni deo grafikona sadrži najveću koncentraciju tačaka, gde se budžeti kreću između 3000 i 8000 dolara, a kvalitet zdravstvenog sistema između 50 i 80.
U gornjem desnom uglu vidimo tri države koje izdvajaju približno 10 hiljada dolara po glavi stanovnika za zdravstvo, a kvalitet njihovih zdravstvenih sistema je između 90 i 100. Ove države prednjače po oba parametra.
Ipak, samo vizuelna analiza nije dovoljna za pouzdane zaključke o uticaju budžeta na kvalitet zdravstvenog sistema. Da bismo preciznije sagledali ovaj odnos, iskoristićemo aritmetičke sredine ovih varijabli kao referentne tačke na dijagramu.
Prikaži kod
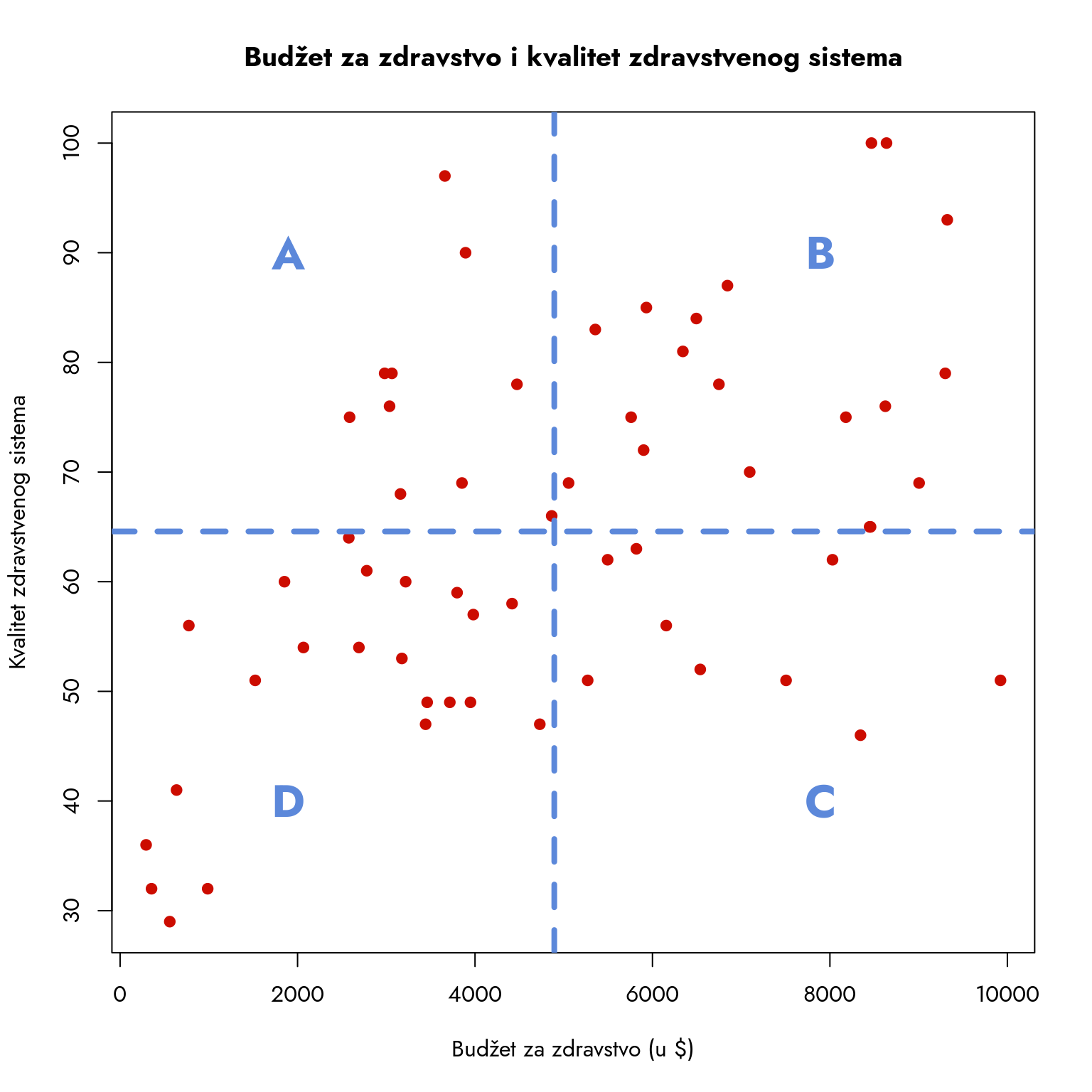
par(family ="Jost")budzet_sredina <-mean(podaci$budzet)kvalitet_sredina <-mean(podaci$kvalitet)plot(podaci$budzet, podaci$kvalitet,xlab ="Budžet za zdravstvo (u $)",ylab ="Kvalitet zdravstvenog sistema",main ="Budžet za zdravstvo i kvalitet zdravstvenog sistema",col ="#CC0C00FF",pch =19)abline(v = budzet_sredina,col ="#5C88DAFF",lty =2,lwd =4)abline(h = kvalitet_sredina,col ="#5C88DAFF",lty =2,lwd =4)text("A", x = budzet_sredina -3000, y =90, col ="#5C88DAFF", cex =2, font =2)text("B", x = budzet_sredina +3000, y =90, col ="#5C88DAFF", cex=2, font =2)text("C", x = budzet_sredina +3000, y =40, col ="#5C88DAFF", cex=2, font =2)text("D", x = budzet_sredina -3000, y =40, col ="#5C88DAFF", cex=2, font =2)
1
Koristimo funkciju plot sa dva osnovna argumenta: prvi je vrednost za x-osu, a drugi za y-osu.
2
Dodajemo dve linije koje prolaze kroz aritmetičke sredine budžeta i kvaliteta zdravstvenog sistema.
Slika 9.4: Dijagram raspršenosti sa četiri kvadranta
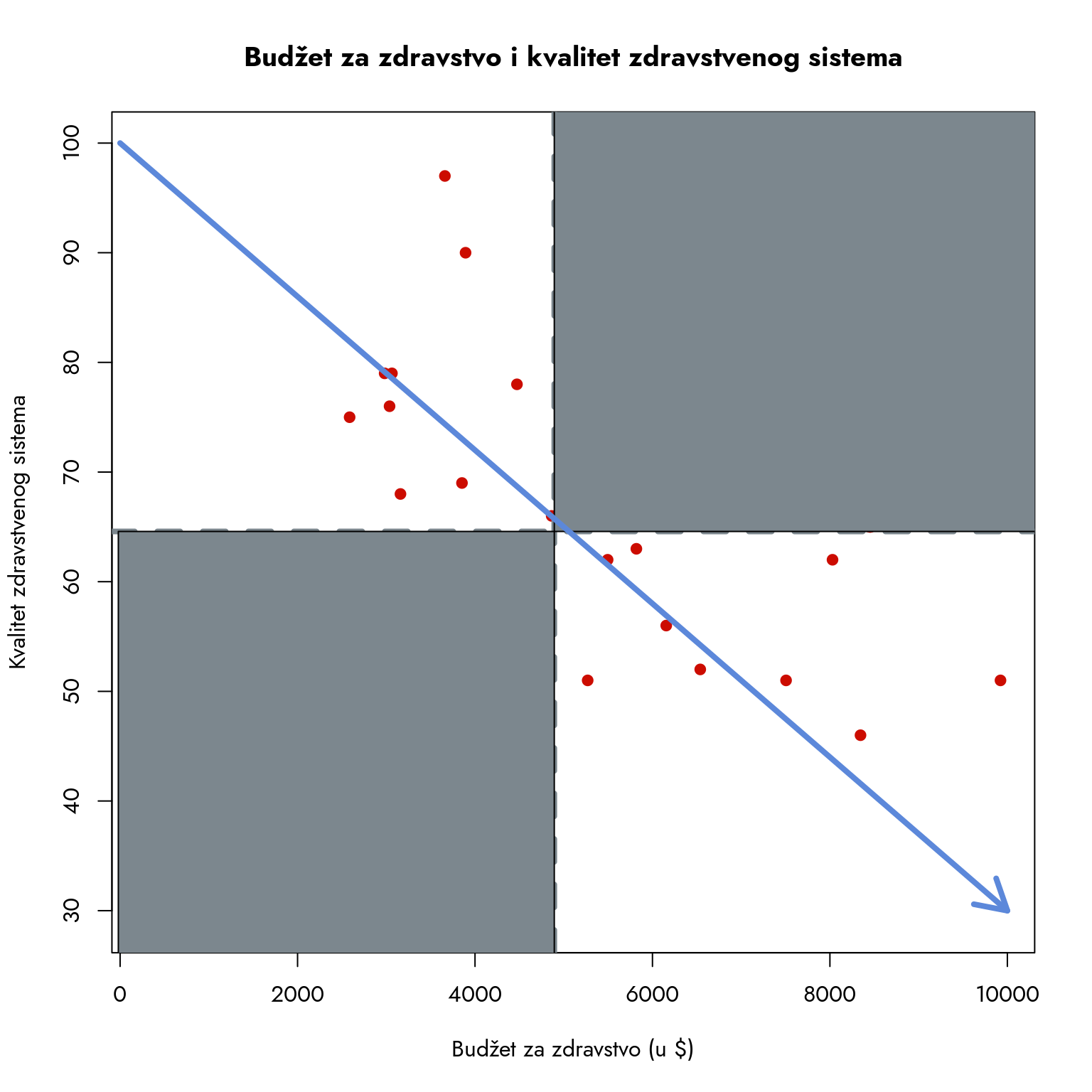
Isprekidane plave linije na grafikonu prikazuju aritmetičke sredine obe varijable. Prosečan budžet iznosi oko 4900 dolara po glavi stanovnika, dok je prosečna ocena kvaliteta približno 65. Presekom ovih linija formiraju se četiri karakteristična kvadranta: A, B, C i D. Svaki kvadrant nosi posebno značenje i pruža nam uvid u različite obrasce odnosa između budžeta i kvaliteta zdravstvenog sistema.
Kvadrant A: Države koje imaju budžet ispod proseka, ali pokazuju iznadprosečan kvalitet zdravstvenog sistema. Ove zemlje postižu značajne rezultate uz ograničena sredstva, verovatno zahvaljujući efikasnom upravljanju ili visokoj stručnosti zdravstvenog osoblja.
Kvadrant B: Države sa budžetom i kvalitetom zdravstvenog sistema iznad proseka. Ovo su lideri u našoj analizi - sistemi koji kombinuju visoka ulaganja sa visokim kvalitetom usluge.
Kvadrant C: Države koje uprkos iznadprosečnom budžetu beleže ispodprosečan kvalitet zdravstvenog sistema. Ovo ukazuje na moguće probleme u efikasnosti sistema i korišćenju raspoloživih sredstava.
Kvadrant D: Države sa budžetom i kvalitetom zdravstvenog sistema ispod proseka. Ove zemlje se suočavaju sa dvostrukim izazovom - ograničenim resursima i nezadovoljavajućim kvalitetom zdravstvene zaštite.
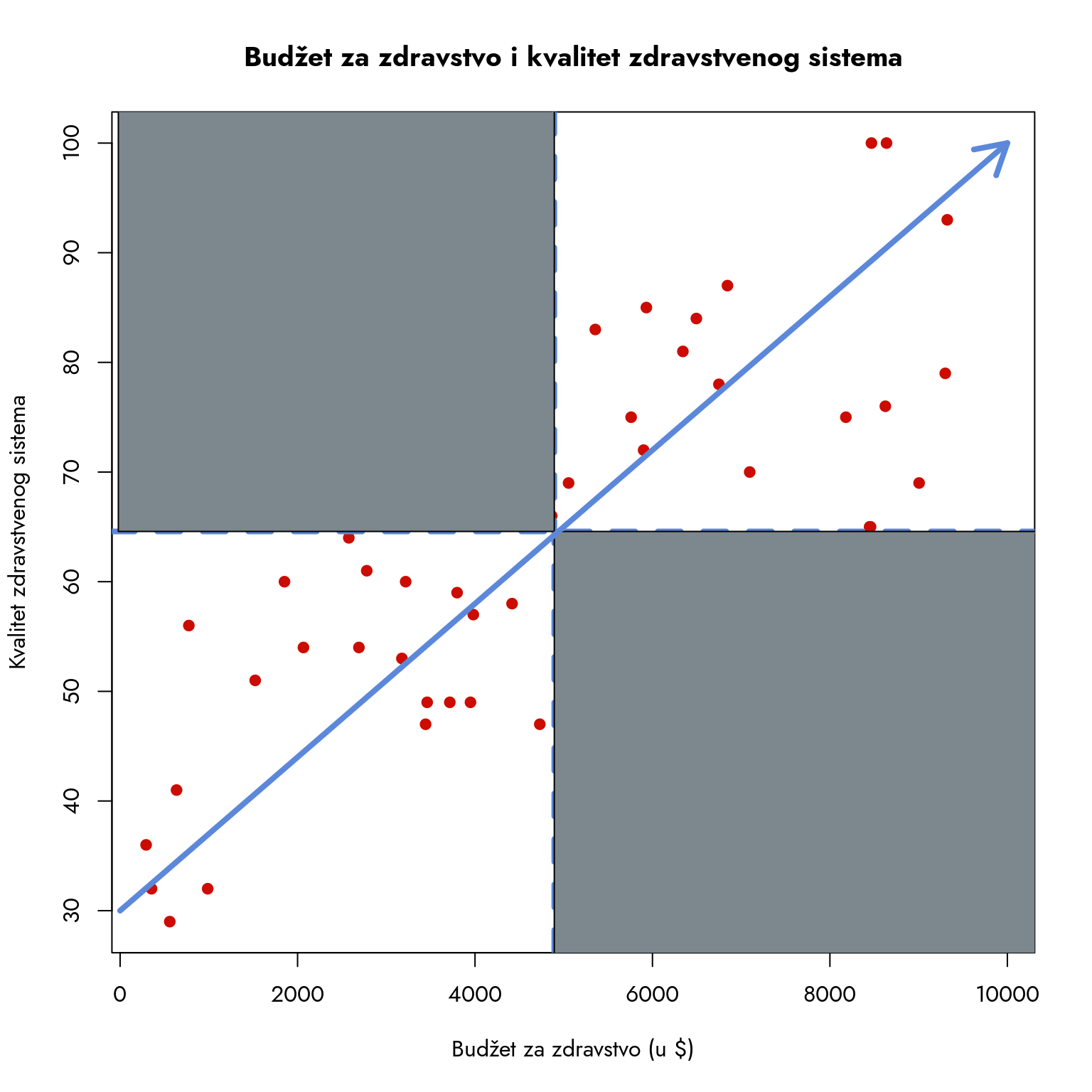
Fokusirajmo se na kvadrante B i D.
Slika 9.5: Dijagram raspršenosti sa kvadrantima B i D
Pogledajmo šta nam kvadranti govore.
Države u donjem kvadrantu (D) pokazuju jasnu vezu - nizak budžet za zdravstvo prati nizak kvalitet zdravstvenog sistema.
Gornji kvadrant (B) pokazuje komplementarnu sliku - države sa većim budžetom za zdravstvo održavaju viši kvalitet zdravstvenog sistema.
Ovakav raspored podataka je logičan i očekivan. Kada pratimo tačke od leve ka desnoj strani, uočavamo da se one kreću od donjeg levog ka gornjem desnom uglu, što je predstavljeno plavom strelicom na grafikonu.
Ako posmatramo horizontalno kretanje od leve strane, prvo uočavamo ispodprosečne budžete. Kako se pomeramo udesno, primećujemo i vertikalno kretanje ka većim ocenama kvaliteta. Da imamo samo ove vrednosti, naš zaključak bi bio nedvosmislen: budžet i kvalitet zdravstvenog sistema su pozitivno povezani. Ipak, moramo biti oprezni - ovo je samo vizuelna procena zasnovana na delimičnom skupu podataka.
Razmotrimo sada preostala dva kvadranta zasebno.
Slika 9.6: Dijagram raspršenosti sa kvadrantima A i C
Pogledajmo sada suprotnu situaciju:
Određene države sa manjim budžetima uspevaju da održe visok kvalitet zdravstvenog sistema (kvadrant A).
Pojedine države, uprkos većim izdvajanjima za zdravstvo, beleže niži kvalitet zdravstvenog sistema (kvadrant C).
Ovaj obrazac nam otkriva kako drugi faktori poput efikasnosti upravljanja sredstvima, stručnosti zdravstvenog osoblja i specifične zdravstvene politike značajno utiču na vezu između budžeta i kvaliteta zdravstva.
Kada posmatramo ove tačke, uočavamo nešto neočekivano - u nekim slučajevima povećanje budžeta prati pad kvaliteta zdravstvenog sistema. Plava strelica koja se pruža od gornjeg levog do donjeg desnog ugla jasno ilustruje ovaj kontraintuitivni odnos. Kako se krećemo desno na grafikonu, pratimo i vertikalni pad ka nižim ocenama kvaliteta.
Plave linije na prethodnim grafikonima prikazuju trend zajedničke promene dve varijable. No, vidimo da ovi trendovi ukazuju na dva različita obrasca u odnosu između budžeta i kvaliteta zdravstva. Jedan segment podataka sugeriše pozitivnu vezu, dok drugi ukazuje na negativnu povezanost. Ova dualnost nas dovodi do ključnih pitanja:
Da li zaista postoji veza između budžeta i kvaliteta zdravstvenog sistema?
Ako postoji, da li je ta veza pozitivna ili negativna?
Ili možda veza uopšte ne postoji?
Iako na našim grafikonima možemo pronaći dokaze za sve ove tvrdnje, oni nam ne daju jasan i konačan odgovor.
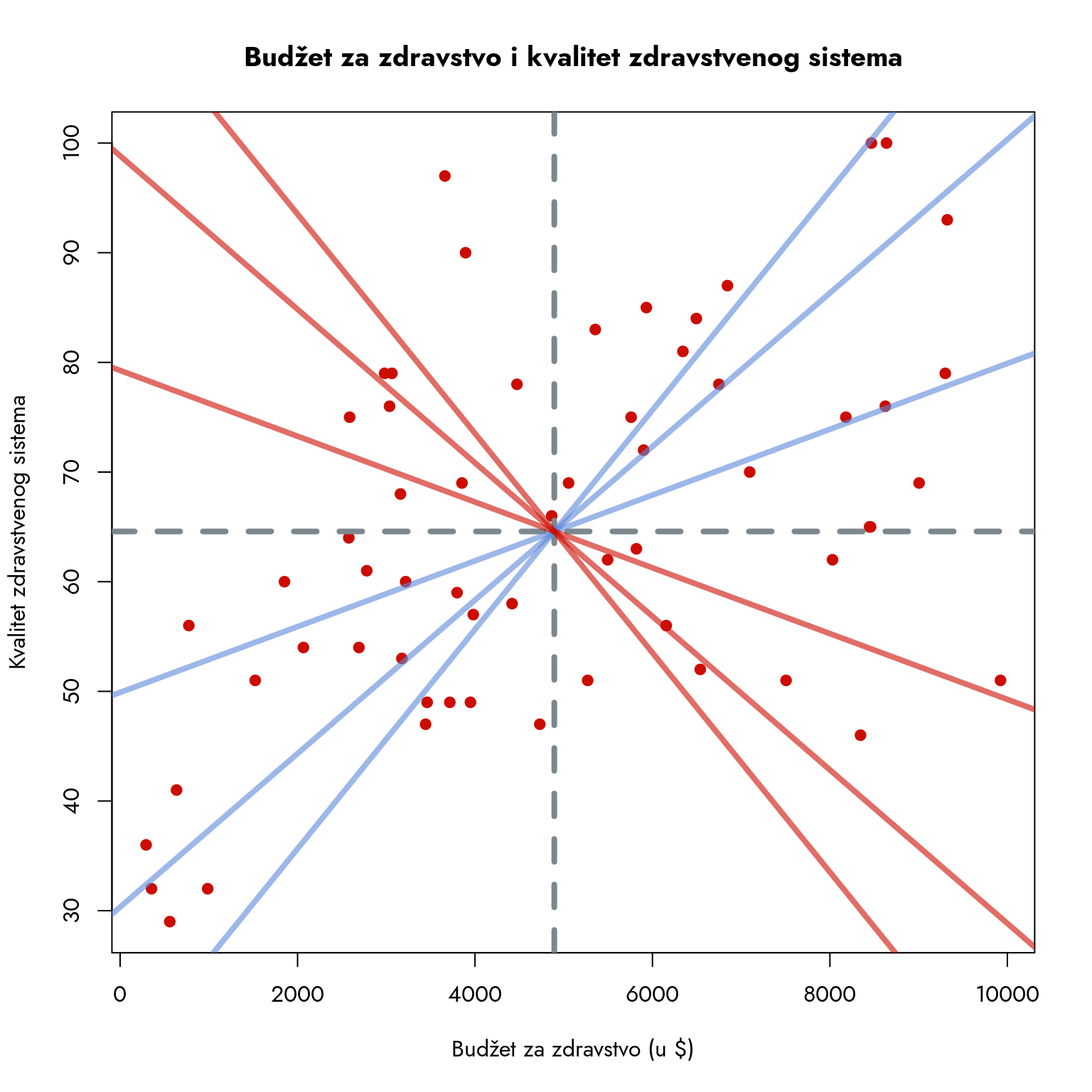
Da bismo bolje razumeli situaciju, vratimo se dijagramu raspršenosti. Da bi linija predstavljala trend zajedničke promene dve varijable, ona mora prolaziti kroz tačku koja predstavlja aritmetičke sredine obe varijable. Ova tačka, presek sredina budžeta i kvaliteta zdravstvenog sistema, opisuje centralnu tendenciju podataka. Linija treba da nam pokaže šta se dešava kada imamo podatke koji se kreću ispod i iznad tih proseka. Koje sve linije trenda možemo povući na ovom grafikonu? Pogledajmo.
Slika 9.7: Dijagram raspršenosti sa različtim potencijalnim linijama trenda
Koja od ovih linija najbolje opisuje naše podatke? Trebalo bi da to bude linija koja dobro predstavlja opšti trend podataka. U praksi, tražimo liniju koja prolazi kroz središnji deo grafikona i nalazi se na optimalnoj udaljenosti od svih tačaka. Sa 60 tačaka u našem skupu podataka, ručno pronalaženje takve linije bilo bi neprecizno i neefikasno.
Za pronalaženje optimalne linije koristimo metod linearne regresije. Ovaj pristup nam omogućava da matematički precizno odredimo liniju koja najbolje opisuje odnos između dve varijable. Regresiona linija nam pruža bogat skup informacija i pomaže nam da kvantifikujemo prirodu veze između varijabli koje proučavamo.
U nastavku ćemo detaljno objasniti konstrukciju regresione linije. Nakon toga, pokazaćemo kako nam ona omogućava da testiramo hipoteze o odnosu između varijabli koristeći rigorozne statističke metode.
9.3 Konstrukcija linije
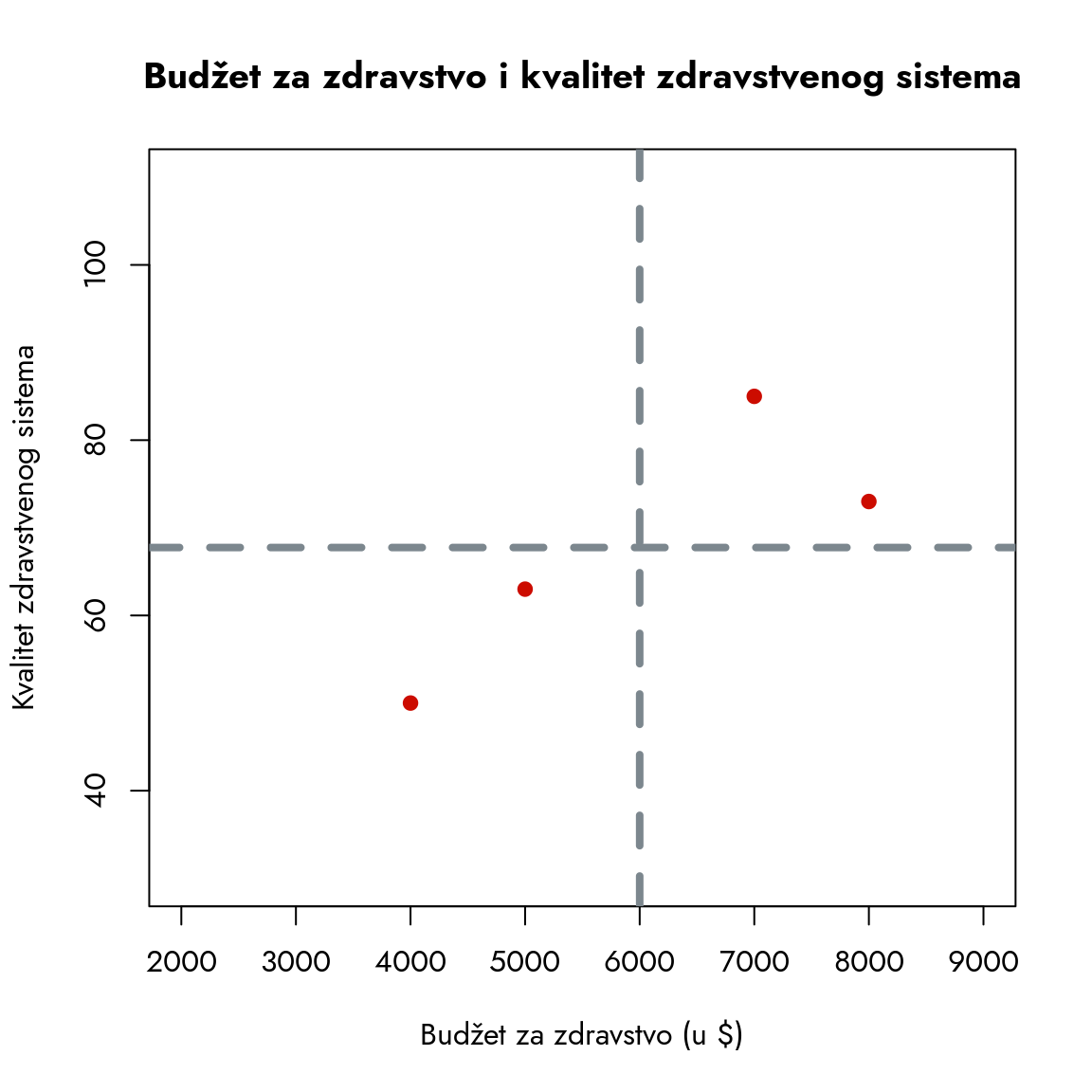
Da bismo razumeli kako se pronalazi optimalna linija, započnimo sa jednostavnijim primerom. Razmotrimo situaciju sa samo četiri države i njihovim vrednostima budžeta i kvaliteta zdravstvenog sistema.
Dijagram raspršenosti za pojednostavljeni primer
U ovom primeru sve tačke su raspoređene tako da ukazuju na potrebu za rastućom linijom. Kao što smo ranije objasnili, ta linija mora proći kroz presek sredina budžeta i kvaliteta.
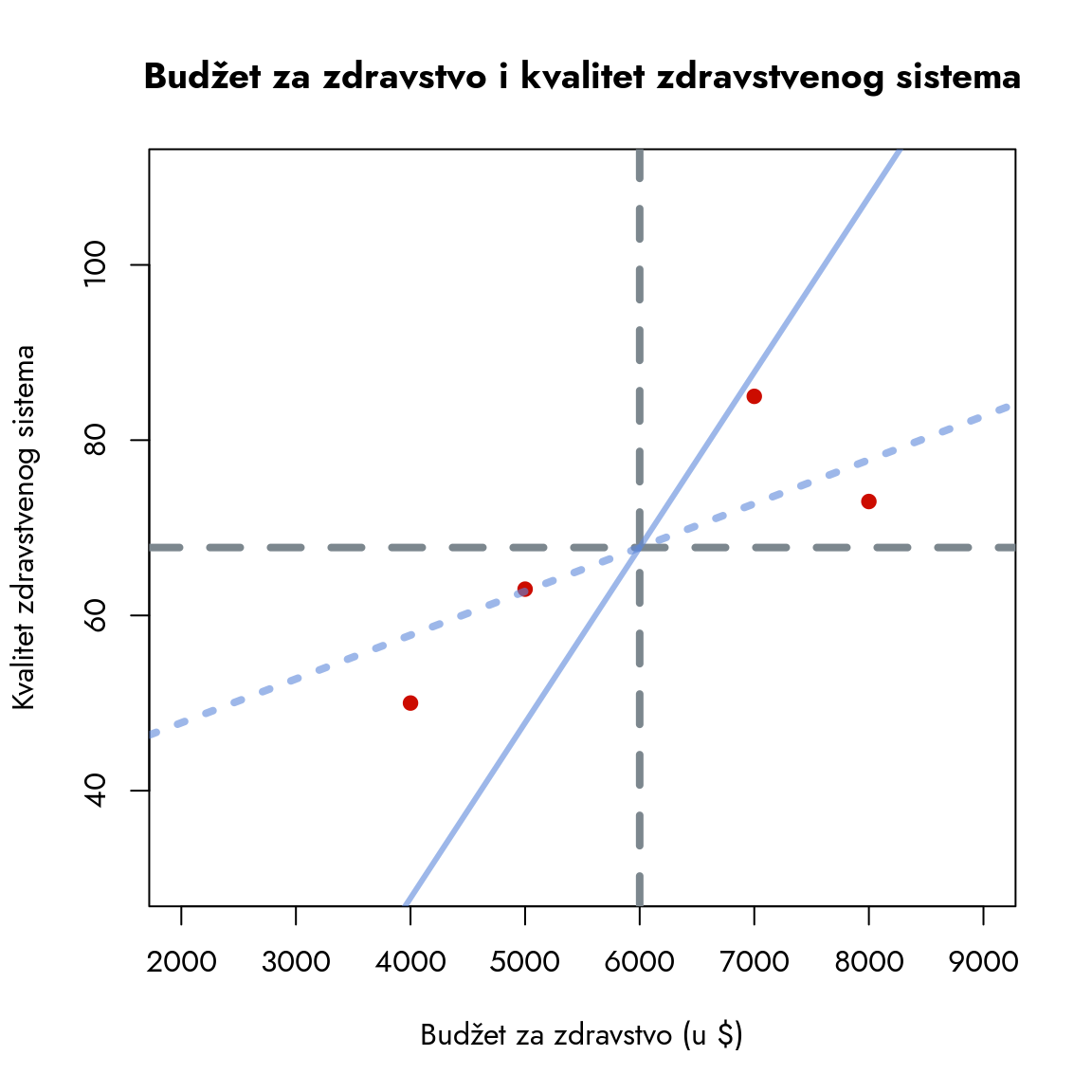
Iz geometrije znamo da su za definisanje prave potrebne dve tačke. U našem slučaju, jedna tačka je već određena - to je presek proseka budžeta i kvaliteta. Izbor druge tačke određuje nagib linije. Pošto još nemamo sistematičan način za određivanje optimalne pozicije druge tačke, počećemo sa dva proizvoljna nagiba. Rezultujuće linije su prikazane na grafikonu.
Slika 9.8: Dve linije trenda
Ove dve linije su rastuće i prolaze kroz tačku preseka aritmetičkih sredina. Njihovi nagibi se, međutim, značajno razlikuju:
Puna plava linija je strmija, sa izraženijim nagibom.
Isprekidana linija ima blaži nagib i približava se horizontalnom položaju.
Nijedna od ovih linija ne opisuje savršeno raspored tačaka u prostoru - neke tačke su bliže jednoj, druge drugoj liniji. Koja je onda bolja opcija?
Odgovor leži u preciznom merenju udaljenosti tačaka od svake linije. Počnimo sa analizom odstupanja od isprekidane linije:
Slika 9.9: Udaljenost tačaka od isprekidane linije
Plave vertikalne linije koje povezuju crvene tačke (opservacije) sa linijom trenda predstavljaju grešku, odnosno odstupanje stvarne vrednosti od predviđene vrednosti. Dužina ovih linija direktno ukazuje na preciznost modela - duže linije znače veću grešku u predviđanju.
Proverimo sada da li isprekidana linija bolje opisuje naše podatke:
Slika 9.10: Udaljenost tačaka od isprekidane linije
Ovo nije komplikovano ako razumemo osnovne principe geometrije. Svaka prava linija može se predstaviti jednostavnom jednačinom: \(y = a + bx\). Ova jednačina ima dva ključna parametra:
\(a\) je odsečak na y-osi (presečna tačka)
\(b\) je koeficijent nagiba (strmina linije)
Kada znamo ove parametre, možemo za svaku vrednost \(x\) izračunati odgovarajuću vrednost \(y\), tako da tačka \((x,y)\) leži na liniji. U našem konkretnom primeru, plavu isprekidanu liniju definišu sledeći parametri:
\[
y = 37.75 + 0.005 \times x
\]
Na primer, ako je \(x=6000\), tada je vrednost y-koordinate tačke na liniji \(y = 37.75 + 0.005 \times 6000 = 67.75\).
Izračunajmo udaljenost između prve tačke (donji levi ugao) i isprekidane linije. Empirijske vrednosti za prvu tačku su:
Izdvajamo prvu vrednost iz vektora budžeta i kvaliteta.
Vrednost x-koordinate prve tačke: 4000
Vrednost y-koordinate prve tačke: 50
Budžet za prvu tačku je 4000. Kada tu vrednost ubacimo u jednačinu linije, dobićemo procenjeni kvalitet za tu tačku na liniji:
Prikaži kod
y_linija <-37.75+0.005* x1cat("Procenjena vrednost y-koordinate na liniji:", y_linija, "\n")
1
Računamo y-koordinatu tačke na liniji prema regresionoj jednačini.
Procenjena vrednost y-koordinate na liniji: 57.75
Dobijamo 57.75, što je više od stvarne vrednosti (kao što vidimo na grafikonu).
Razlika, odnosno greška linije, izračunava se kao razlika između stvarne vrednosti i one koju daje linija:
Prikaži kod
razlika <- y1 - y_linijacat("Razlika između opservacije i linije je:", razlika, "\n")
Razlika između opservacije i linije je: -7.75
Da bismo izračunali ukupnu grešku linije, primenićemo ovaj postupak na sve tačke. Pošto ćemo ovaj proces ponavljati više puta, napišimo funkciju koja računa ukupnu grešku za svaku liniju:
Prikaži kod
ukupna_greska <-function(x, y, a, b) { y_linija <- a + b * x razlika <- y - y_linijareturn(sum(razlika^2))}
1
Ulazni parametri funkcije su vektori x i y (vrednosti opservacija) i dva parametra linije a i b.
2
Definišemo liniju i računamo y-koordinate tačaka na liniji.
3
Računamo razliku između stvarne vrednosti i vrednosti na liniji.
4
Funkcija vraća sumu kvadrata razlika.
TipZašto kvadriramo grešku?
Kada računamo grešku, koristimo kvadrat razlike između stvarne vrednosti i one koju daje linija. Zašto?
Kvadriranje čini sve vrednosti pozitivnim. Tako možemo sabirati odstupanja koja su i ispod i iznad linije bez poništavanja.
Kvadriranje daje veću težinu većim greškama. Na primer: \(3^2 = 9\) i \(5^2 = 25\). Ovo znači da će veće greške imati veći uticaj na ukupnu grešku.
Sada ćemo primeniti ovu funkciju na naše podatke. Pre nego što je vidimo na delu, napisaćemo jednačinu druge linije.
R je izračunao da je greška pune linije značajno veća nego isprekidane (Slika 9.8). Gde je puna linija najviše promašila? Imamo dva izrazita primera odstupanja.
Kada je budžet oko 4000 dolara, stvarni kvalitet zdravstvenog sistema je značajno viši od onoga što predviđa ova linija.
Kada je budžet oko 8000 dolara, stvarni kvalitet zdravstvenog sistema je značajno niži od onoga što predviđa ova linija.
Ova odstupanja zajedno pokazuju da ova linija trenda ne opisuje adekvatno odnos između dve varijable.
Obe linije smo nacrtali bez jasne strategije za pronalaženje optimalne linije – one kod koje je greška najmanja. Metod koji koristimo za pronalaženje te optimalne linije naziva se metod najmanjih kvadrata i predstavlja temelj proste linearne regresije.
9.4 Prosta linearna regresija
Regresiona analiza je metod koji opisuje kako se zavisna varijabla menja pod uticajem drugih varijabli. Kroz regresionu analizu izvodimo jednačinu koja povezuje zavisnu varijablu sa jednom ili više nezavisnih varijabli. Jednostavno rečeno, pokušavamo da razumemo kako jedna varijabla reaguje na promene u drugoj varijabli.
U ovom poglavlju bavimo se prostom linearnom regresijom - osnovnim modelom regresione analize. Ovaj model koristi jednu nezavisnu varijablu da objasni varijacije u zavisnoj varijabli. Kada koristimo više od jedne nezavisne varijable, ulazimo u područje multivarijacione analize.
Zašto linearna regresija? Zato što pretpostavljamo da se odnos između varijabli može opisati pravom linijom. Linije trenda koje smo videli ranije predstavljaju primere regresionih linija.
Rezultat linearne regresije je regresiona jednačina. Ova jednačina ima dve primene: opisuje jačinu uticaja nezavisne varijable (opisna funkcija) i omogućava nam da predvidimo vrednosti zavisne varijable, što ćemo detaljnije obraditi u narednom poglavlju.
Matematički zapisano, ako zavisnu varijablu označimo sa \(Y\), a nezavisnu sa \(X\), jednačina regresione linije ima sledeći oblik: \[
Y = b_0 + b_1 \times X
\]
Ova jednačina je slična jednačini prave linije koju smo videli ranije, ali regresija koristi drugačiju notaciju. Ovde, \(b_0\) označava slobodni koeficijent, dok je \(b_1\) koeficijent nagiba. Pre nego što detaljno objasnimo kako se izračunavaju ovi koeficijenti, razmotrimo njihovu geometrijsku interpretaciju.
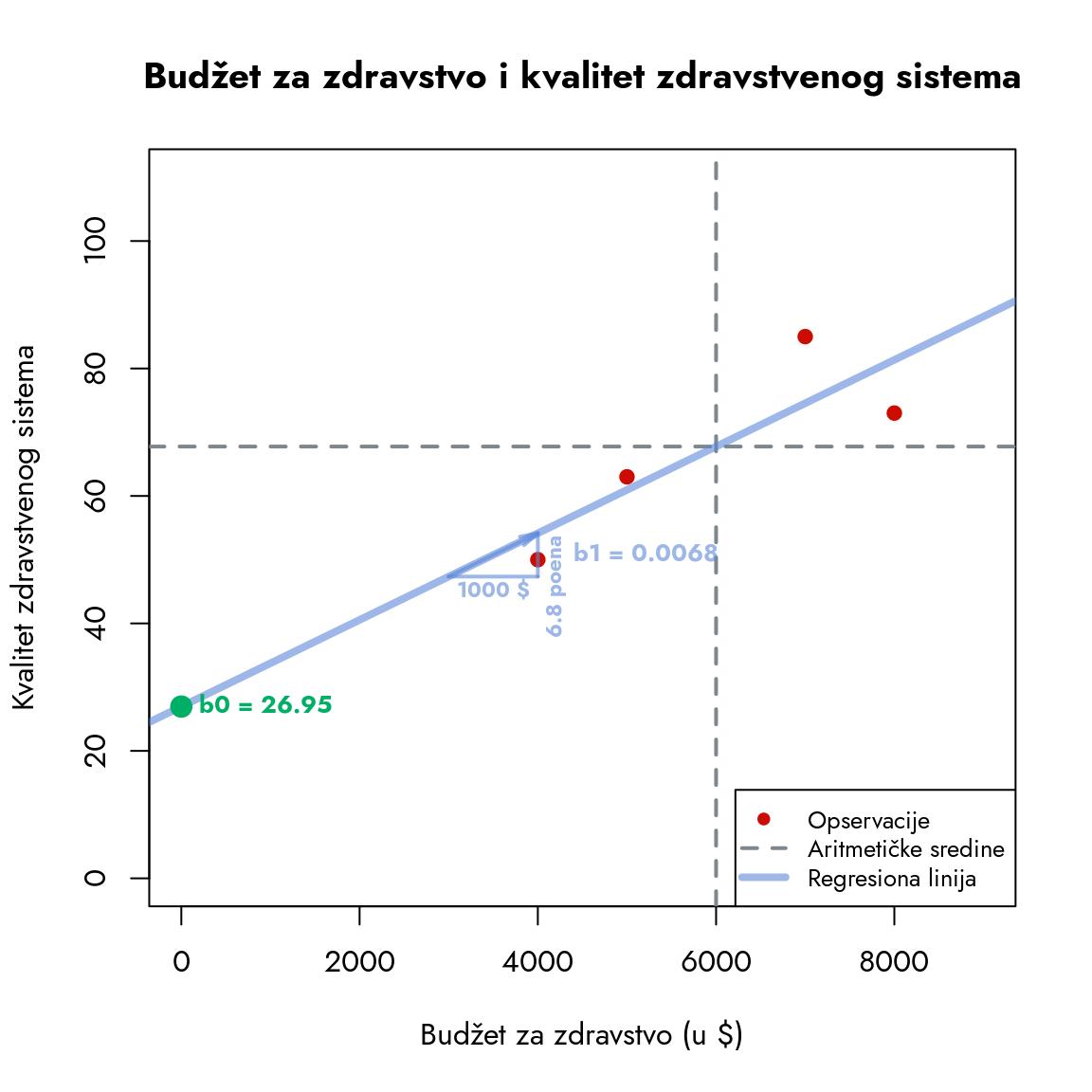
Slika 9.11: Interpretacija koeficijenata regresione linije
Na grafikonu vidimo interpretaciju oba koeficijenta. Prvi, \(b_0\), poznat kao slobodni koeficijent ili odsečak na y-osi, pokazuje vrednost zavisne varijable kada je nezavisna varijabla jednaka 0.
Konkretno, ako je budžet za zdravstvo 0 dolara, očekivana ocena kvaliteta zdravstvenog sistema bi bila \(b_0\), što je u ovom slučaju približno 27. Iako su ove vrednosti hipotetičke i retko imaju praktičnu primenu (nijedna država nema budžet za zdravstvo od 0 dolara), one nam daju polaznu tačku za razumevanje odnosa između varijabli.
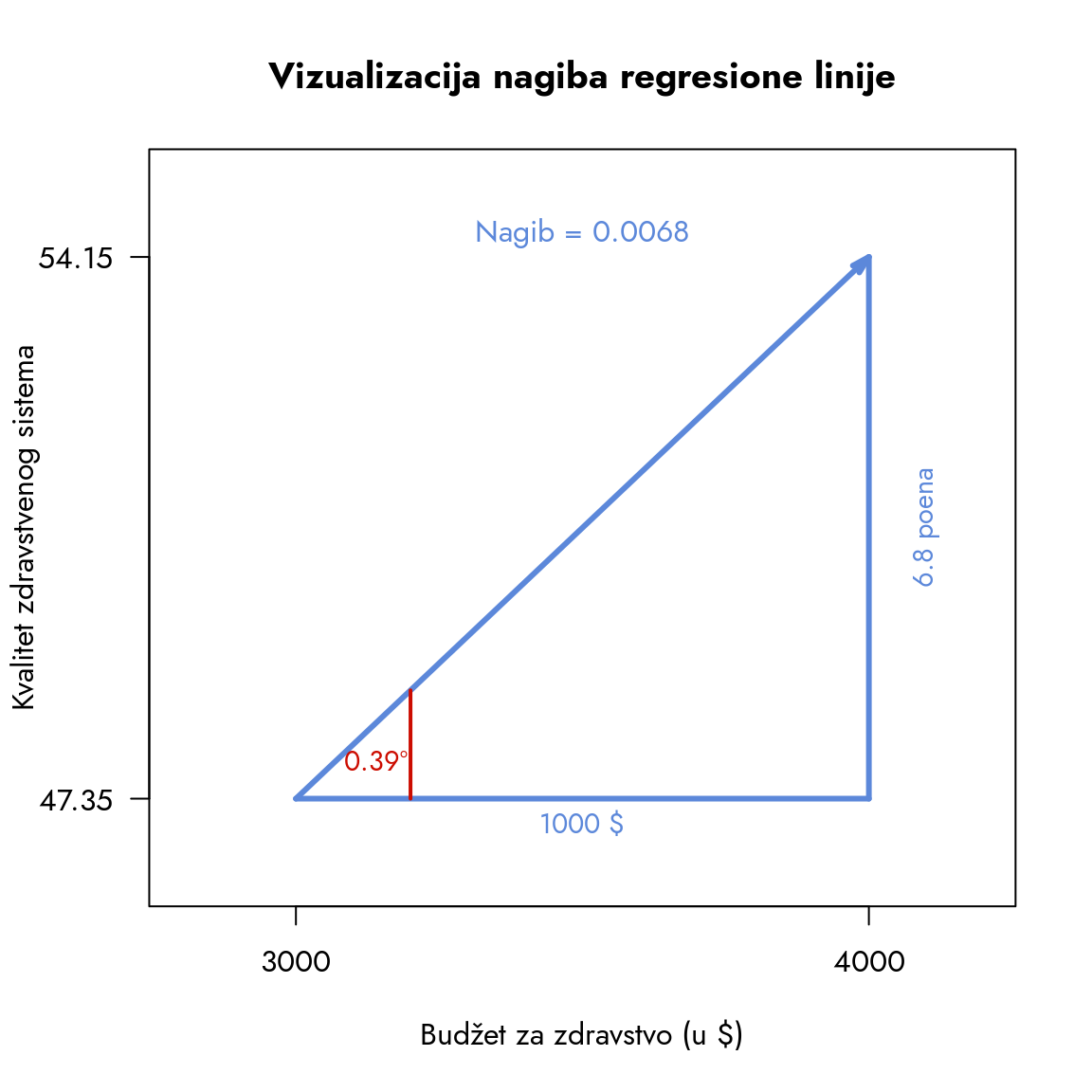
Drugi koeficijent, \(b_1\), predstavlja nagib linije. Za razliku od \(b_0\) koji označava tačku, \(b_1\) opisuje ugao pod kojim se linija pruža. Pogledajte sliku ispod koja detaljno prikazuje geometrijsku interpretaciju ovog koeficijenta.
Slika 9.12: Interpretacija koeficijenata regresione linije
Ovaj koeficijent nam otkriva jednostavnu istinu: kada se vrednost nezavisne varijable poveća za 1, vrednost zavisne varijable će se povećati za \(b_1\). Možemo skalirati ovaj odnos множењем sa proizvoljnim brojem. U našem primeru, ako se budžet poveća za 1000 dolara, kvalitet zdravstvenog sistema će se, u proseku, povećati za \(0.0068 \times 1000 = 6.8\) poena. Kroz ovaj koeficijent dobijamo jasan i precizan opis odnosa između dve varijable. Postavlja se pitanje: šta možemo očekivati da će se desiti sa zavisnom varijablom kada promenimo nezavisnu?
Fokusirajmo se na reč „očekivanje“. U kontekstu našeg primera, ovo znači da će se kvalitet u proseku povećati za 6.8 poena kada se budžet poveća za 1000 dolara. Naglasak je na „u proseku“ - neke države će odstupati od ovog obrasca, ali ovo je generalni trend koji možemo očekivati.
Ovime se vraćamo na početnu komparativnu dimenziju problema. Koeficijent nagiba nam omogućava da odgovorimo na konkretno pitanje: kolika je prosečna razlika u kvalitetu zdravstvenog sistema između država koje imaju budžet od 5000$ i 6000$? Odgovor je 6.8 poena. Ova informacija predstavlja srž regresione analize i jasno pokazuje njen komparativni karakter.
9.5 Metod najmanjih kvadrata
Sada dolazimo do suštinskog pitanja: kako odrediti ova dva koeficijenta? Za prostu linearnu regresiju, rešenje nam nudi elegantni metod najmanjih kvadrata.
Ovaj metod nam omogućava da precizno odredimo koeficijent \(b_1\). Već znamo da regresiona linija mora proći kroz tačku sredine, ali kako odabrati optimalan nagib? Metod najmanjih kvadrata ima jasan kriterijum - biramo onaj koeficijent koji minimizuje sumu kvadrata odstupanja između stvarnih vrednosti i vrednosti predviđenih linijom. Matematički rečeno, tražimo koeficijent koji daje najmanju moguću vrednost sume kvadrata greške (eng. Sum of Squared Errors, SSE).
NoteOptimizacija i funkcija cilja
Većina statističkih metoda u svojoj osnovi funkcioniše po principu optimizacije određene funkcije. U našem slučaju, optimizujemo funkciju greške regresije. Ova funkcija zavisi od koeficijenata regresione linije i naš cilj je da je minimizujemo. Takvu funkciju nazivamo funkcijom cilja (eng. objective function).
Statistika je nastala kao grana primenjene matematike, i mnogi statistički metodi su zapravo matematički postupci optimizacije. To podrazumeva korišćenje numeričkih metoda, integrala i diferencijalnih jednačina za pronalaženje rešenja.
U naprednijim oblastima statistike i računarstva, poput mašinskog učenja i veštačke inteligencije, ovaj pristup je zamenjen algoritmima koji se zasnivaju na iterativnom pristupu. Ovi algoritmi su računarski efikasniji i brži, ali su istovremeno manje transparentni i teži za razumevanje. Ipak, osnovni princip ostaje isti: pronaći vrednosti parametara koji minimizuju funkciju cilja kako bi se ostvario željeni cilj modela.
Ključno je razumeti da postupak minimizacije ima jedinstveno analitičko rešenje. Šta to znači u praksi? To znači da kroz određene matematičke operacije (parcijalni izvodi greške u odnosu na regresione koeficijente) dolazimo do jedinstvenog rešenja. Drugim rečima, postoji precizna formula koja nam omogućava izračunavanje koeficijenata \(b_0\) i \(b_1\) tako da greška regresije bude minimalna.
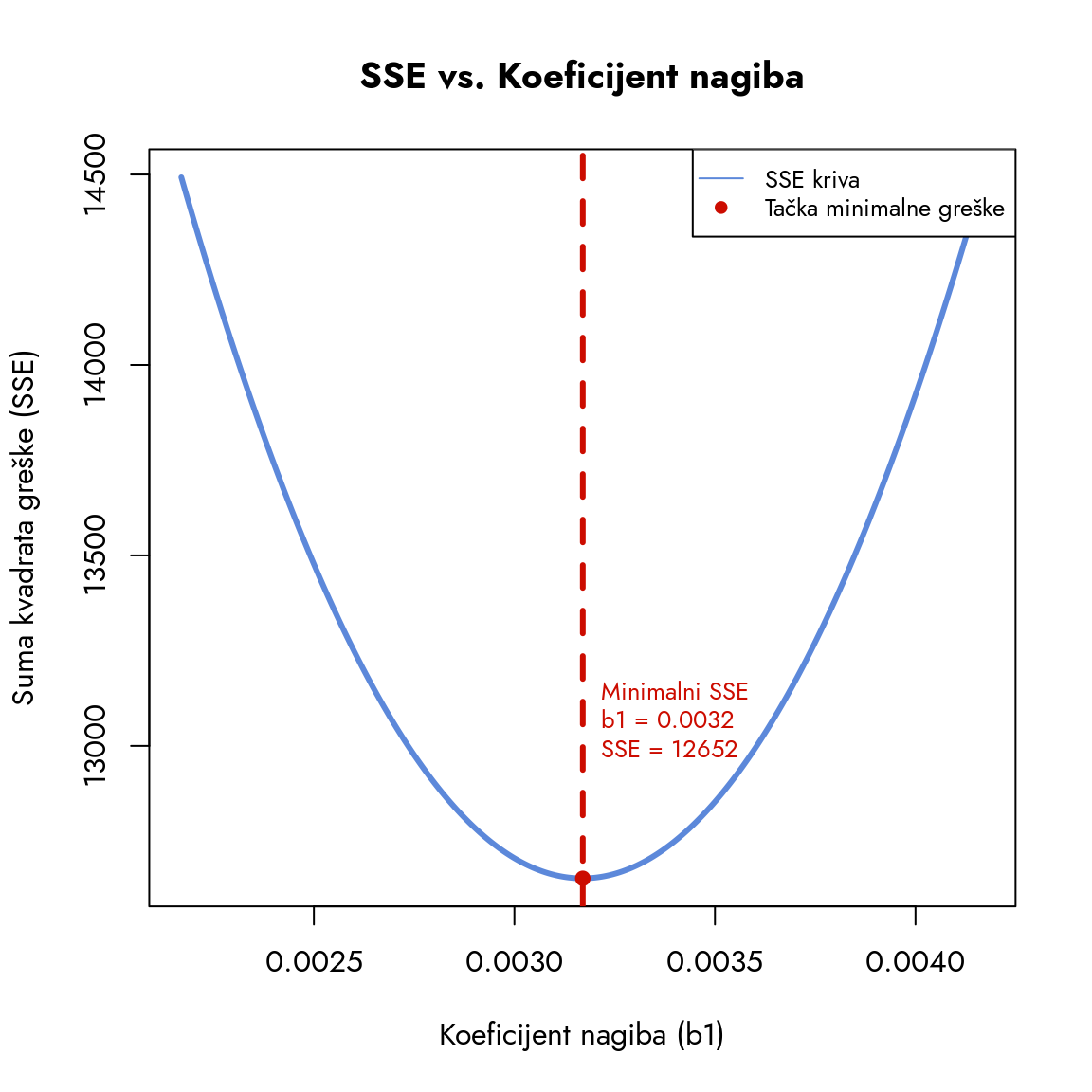
Slika 9.13: Minimizacija greške regresije
Nećemo ulaziti u detalje, ali osnovna logika pronalaženja optimalne vrednosti \(b_1\) je jasno prikazana na slici iznad. Grafikon prikazuje sumu kvadrata greške (SSE) kao funkciju različitih koeficijenata nagiba. Pošto radimo sa prostom regresijom i pravom linijom, funkcija uvek ima ovakav oblik. Cilj metoda najmanjih kvadrata je da pronađe minimum ove krive - da se spusti do najniže tačke i odredi vrednost koja daje najmanju moguću grešku. Do tog minimuma dolazimo formulom:
\[
b_1 = \frac{\text{Cov}(X, Y)}{s_X^2}
\]
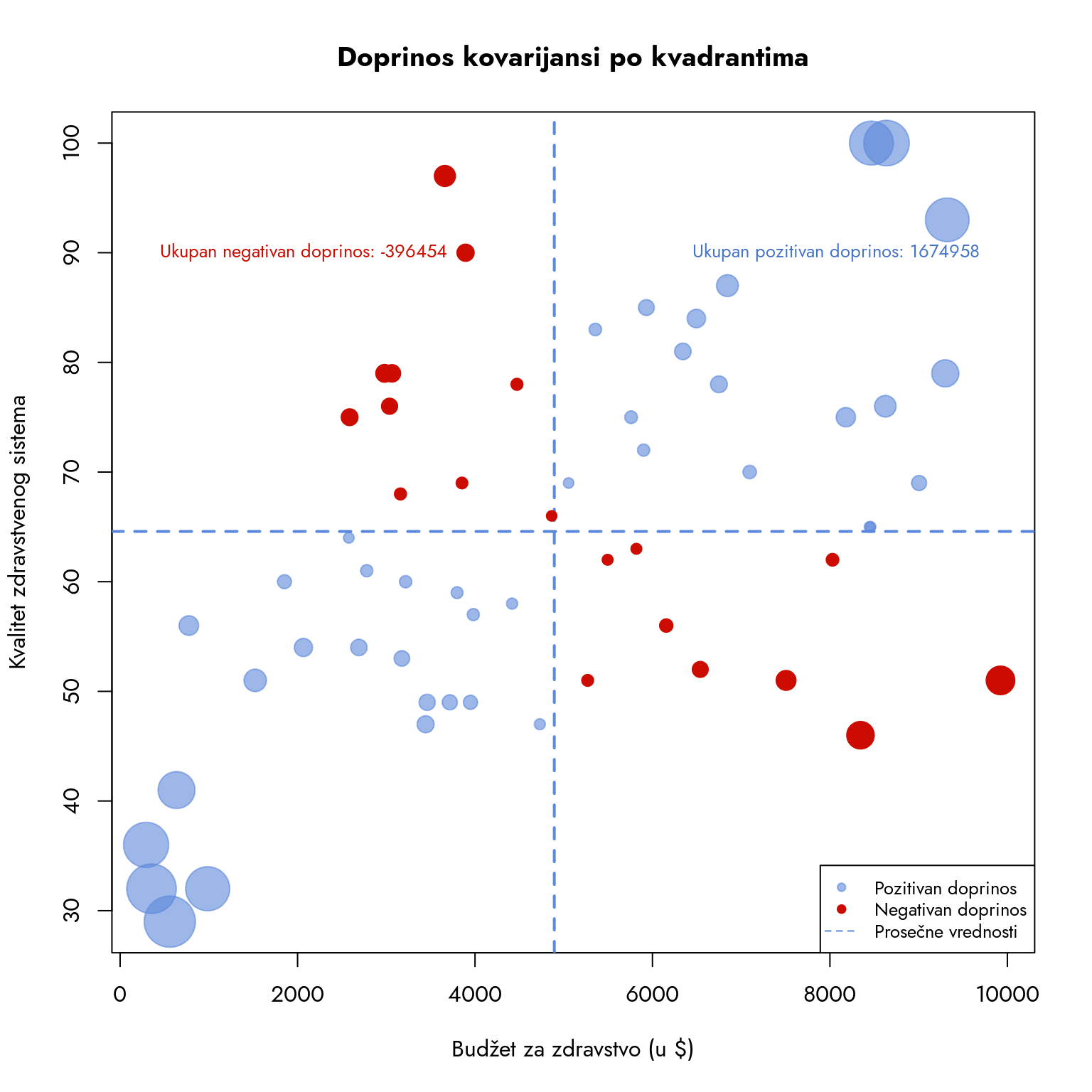
Donji deo razlomka predstavlja varijansu nezavisne varijable, dok gornji deo predstavlja kovarijansu, označenu kao \(\text{Cov}(X,Y)\). Kovarijansa meri zajedničku varijabilnost dve varijable - drugim rečima, govori nam koliko dosledno promena jedne varijable prati promenu druge.
Razmotrimo situaciju koju ilustruje Slika 9.4. Imamo države sa budžetom za zdravstvo oko 2000 dolara. Te države se nalaze u kvadrantu D, sa budžetima i ocenama kvaliteta ispod proseka. Kada se pomerimo desno na X-osi, vidimo države sa budžetom oko 8000 dolara. Od četiri takve države, dve su u kvadrantu C, jedna u kvadrantu B, a jedna na granici B i C. Iako smo budžet povećali četiri puta, dve države su i dalje ispod proseka, jedna je na nivou proseka, a jedna iznad proseka u pogledu kvaliteta zdravstvenog sistema. Ovo jasno pokazuje da povećanje budžeta nije dosledno praćeno povećanjem kvaliteta zdravstvenog sistema.
Kovarijansa kvantifikuje doslednost zajedničkih promena dve varijable. Savršena doslednost postoji kod determinističkog odnosa. Uzmimo primer fiksnog kursa između dve valute - 100 evra uvek vredi 11800 dinara. Udvostručenje iznosa u evrima neizbežno znači udvostručenje iznosa u dinarima jer je odnos deterministički. Međutim, kod stohastičkog odnosa, udvostručenje u jednoj varijabli ne garantuje proporcionalno povećanje u drugoj.
Kovarijansa upravo meri konzistentnost stohastičkog odnosa između varijabli. Pogledajmo formulu:
Na prvi pogled, kovarijansa deluje složeno, ali je suština jednostavna - ona meri udaljenost tačaka u različitim kvadrantima (Slika 9.4). U formuli za kovarijansu, brojilac predstavlja proizvod odstupanja opservacija obe varijable od njihovih aritmetičkih sredina. Na našem grafikonu sa kvadrantima, to je proizvod udaljenosti svake tačke od centra grafikona (preseka aritmetičkih sredina). Šta nam ovaj proizvod govori?
Opservacije u kvadrantima B i D daju pozitivan doprinos kovarijansi. U kvadrantu B, obe udaljenosti su pozitivne, što rezultira pozitivnim proizvodom. U kvadrantu D, obe udaljenosti su negativne, ali njihov proizvod je opet pozitivan. Nasuprot tome, opservacije u kvadrantima A i C umanjuju kovarijansu. Konačna vrednost kovarijanse predstavlja ishod „nadmetanja“ između ova četiri kvadranta. Mogući su sledeći ishodi:
Dominiraju pozitivne vrednosti (B i D kvadranti). Više opservacija se nalazi u ovim kvadrantima, a njihove udaljenosti su ukupno veće nego u drugim kvadrantima. Rezultat je relativno visoka pozitivna kovarijansa.
Prevladavaju negativne vrednosti (A i C kvadranti). Ishod je relativno niska pozitivna kovarijansa.
Izjednačen rezultat. Pozitivne i negativne udaljenosti se približno poništavaju, što vodi ka kovarijansi bliskoj nuli.
Na narednom grafikonu vidimo kako se ovi odnosi manifestuju u našem primeru budžeta i kvaliteta zdravstvenog sistema.
Slika 9.14: Dijagram raspršenosti sa prikazom dorpinosa opservacija kovarijansi. Veličina tačke ukazuje na doprinos opservacije kovarijansi.
Brojevi su veliki. Pozitivna suma dominira, što potvrđuje da kvadranti B i D imaju veći uticaj na model. Koji kvadranti nose najveću težinu? Iz veličine tačaka na grafikonu jasno je da su to države sa niskim budžetom i niskim kvalitetom zdravstva, kao i tri države u gornjem desnom uglu koje kombinuju velike budžete sa visokom ocenom kvaliteta.
Kovarijansu možemo jednostavno izračunati u R-u koristeći funkciju cov.
Vidimo da je kovarijansa veliki, pozitivan broj. Sam podatak o pozitivnom predznaku je koristan, ali numerička vrednost nam ne govori mnogo. Slično kao kod varijanse, kovarijansa ima jedinicu mere koja nema praktičnu interpretaciju.
Hajde da se vratimo na formulu za koeficijent nagiba. Pozitivna kovarijansa i dominacija kvadranata B i D vode ka pozitivnom koeficijentu nagiba. To znači da će regresiona linija prolaziti kroz ove dominantne kvadrante.
Sada možemo jednostavno izračunati vrednost koeficijenta nagiba koji minimizuje sumu kvadrata greške.
Ovo je vrednost koju smo uočili na grafikonu minimizacije sume kvadrata greške: \(b_1 = 0.0032\). Kroz ovaj proces smo otkrili da je koeficijent nagiba, glavni regresioni koeficijent, zapravo odnos kovarijanse i varijanse nezavisne varijable. On kvantifikuje koliki je zajednički varijabilitet u odnosu na varijabilitet nezavisne varijable. Što je apsolutna vrednost koeficijenta veća, to je veza između varijabli jača i konzistentnija.
Kada imamo koeficijent nagiba, jednostavno možemo izračunati i drugi regresioni koeficijent. Znamo da regresiona linija mora proći kroz tačku koja predstavlja aritmetičke sredine obe varijable (\((\overline{X}, \overline{Y})\)). Primenom ovih vrednosti u jednačini regresione linije, dobijamo:
Izračunavamo slobodni koeficijent pomoću formule koja koristi aritmetičke sredine obe varijable.
[1] "Slobodni koeficijent:"
[1] 49.07
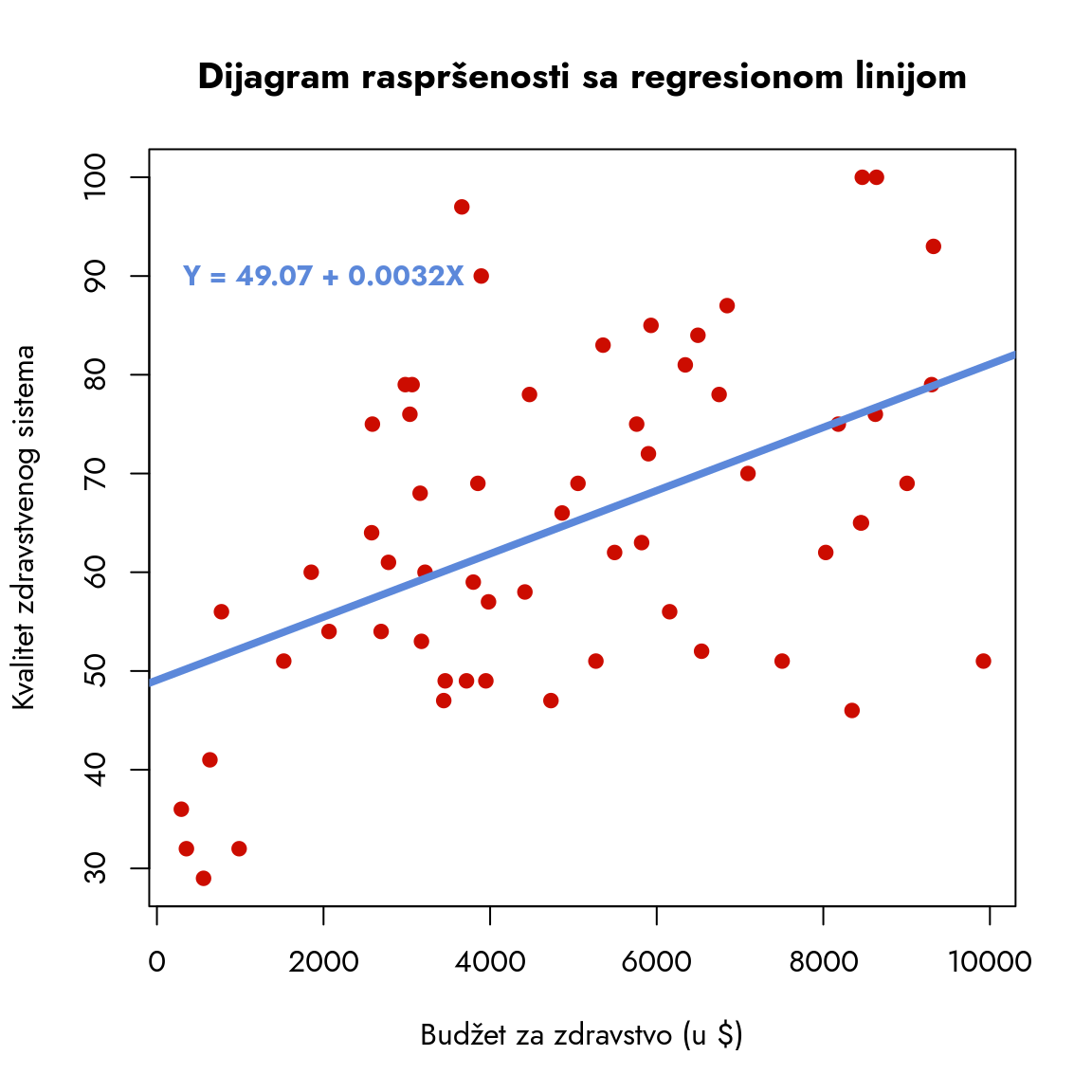
Dakle, naša regresiona jednačina izgleda ovako:
\[
Y = 49.07 + 0.0032X
\]
Na dijagramu rasprešnosti možemo najzad ucrtati liniju za koju znamo da sigurno predstavlja liniju koja je prolazi kroz tačku proseka obe varijable i najmanje je udaljena od svih drugih tačaka.
Prikaži kod
par(family ="Jost")b0 <-49.07b1 <-0.0032plot(podaci$budzet, podaci$kvalitet,xlab ="Budžet za zdravstvo (u $)",ylab ="Kvalitet zdravstvenog sistema",main ="Dijagram raspršenosti sa regresionom linijom",col ="#CC0C00FF",pch =19)abline(a = b0, b = b1, col ="#5C88DAFF", lwd =4)text(2000, 90, expression(bold(paste("Y = 49.07 + 0.0032X"))), col ="#5C88DAFF", cex =0.9, font =2)
1
Postavljamo vrednosti koeficijenata \(b_0\) i \(b_1\).
2
Crtamo dijagram raspršenosti.
3
Crtamo regresionu liniju sa odgovarajućim koeficijentima.
Slika 9.15: Dijagram raspršenosti sa regresionom linijom
9.6 Regresioni model
Regresiona linija proizilazi iz uzorka i opisuje samo informacije koje u njemu nalazimo. Međutim, ako želimo da izvedemo šire zaključke i opišemo odnos između dva fenomena na nivou populacije, potreban nam je regresioni model.
Model možemo zapisati na sledeći način:
\[
Y = \beta_0 + \beta_1 \times X + \varepsilon
\]
Kao što vidite, postoje značajne razlike u načinu kako formulišemo regresionu liniju. Prvo, koristimo grčka slova \(\beta\) i \(\epsilon\), što označava da se regresioni model odnosi na nepoznate parametre populacije. Slobodni koeficijent \(\beta_0\) i koeficijent nagiba \(\beta_1\) su sada nepoznate vrednosti o kojima ćemo, kao i u prethodnim poglavljima, pokušati da donesemo zaključke uz pomoć statističkog testa. Preostaje nam \(\epsilon\) - nepoznati parametar koji opisuje ukupnu grešku regresije.
Ranije smo naglasili da je odnos koji opisuje regresija stohastički. To znači da regresiona linija, odnosno njen nagib \(\beta_1\), neće savršeno opisati odstupanja svih tačaka od linije. Ta odstupanja su zapravo greške regresije \(\varepsilon_i\). One predstavljaju sve faktore koji utiču na kvalitet zdravstvenog sistema, a koje nismo obuhvatili budžetom. Ove greške su stohastičke - slučajne su i nezavisne od budžeta, rezultat svih ostalih faktora koji oblikuju kvalitet zdravstvenog sistema.
Na nivou uzorka, lako smo izračunali grešku regresije. Međutim, na nivou populacije to nije moguće jer ne znamo sve opservacije koje postoje u „velikom svetu“. Upravo zato je \(\varepsilon\) nepoznati parametar populacije.
Pred nama su dva ključna koraka. Prvi je testiranje regresione hipoteze na osnovu rezultata iz uzorka - želimo utvrditi da li je regresioni model statistički značajan na nivou populacije. Drugi je dijagnostika modela - proveravamo da li regresioni model adekvatno opisuje odnos između varijabli i da li su pretpostavke o grešci ispunjene.
9.6.1 Testiranje statističke značajnosti regresionog modela
Vratimo se našem primeru. Na nivou uzorka dobili smo sledeću regresionu liniju:
\[
Y = 49.07 + 0.032 \times X
\]
Koeficijenti \(b_0\) i \(b_1\) iz uzorka su naše najbolje procene parametara populacije \(\beta_0\) i \(\beta_1\). Kritičan korak je testiranje statističke značajnosti koeficijenta nagiba, jer on definiše prirodu veze između varijabli. Vrednost bliska 0 ukazuje na odsustvo linearne veze (efekti iz kvadranata A i C neutrališu efekte iz kvadranata B i D).
U našem primeru, dobili smo koeficijent koji nije tačno 0, ali je blizu te vrednosti. Ovo nas dovodi do poznatog problema - kako utvrditi da li je dobijena vrednost dovoljno različita od nule da bismo mogli doneti pouzdan zaključak? Odgovor leži u primeni statističkog testa ili intervala poverenja. Razmotrićemo oba pristupa.
Prvo definišimo nultu hipotezu. Ona postulira odsustvo efekta, što u kontekstu regresije znači da je koeficijent nagiba jednak nuli:
Alternativna hipoteza tvrdi da efekat postoji, odnosno da koeficijent nagiba nije jednak 0. U ovom dvosmernom obliku ne razmatramo smer uticaja, već samo njegovo postojanje.
Kako testiramo ovu hipotezu? Potrebna nam je test statistika - standardizovana vrednost koeficijenta nagiba. Do nje dolazimo deljenjem koeficijenta nagiba njegovom standardnom greškom. Standardna greška koeficijenta nagiba meri preciznost naše procene. Manja greška ukazuje na precizniju procenu.
Hajde da pokušamo da razumemo ovu formulu. Imenilac predstavlja koren sume kvadrata odstupanja nezavisne varijable - to je suština formule za varijansu. Manja odstupanja povećavaju grešku regresije. Zašto je to tako? Kada nezavisna varijabla nema dovoljno varijabiliteta, ne može dobro objasniti promene zavisne varijable.
Zamislite ekstremnu situaciju: sve države u uzorku imaju identičan budžet. Imali bismo 60 tačaka vertikalno poređanih na istoj X koordinati. Nijedna regresiona linija ne bi mogla smisleno objasniti varijacije u kvalitetu zdravstva - jednostavno nema osnove za to. Greška regresije bi bila ogromna (tehnički, beskonačna zbog deljenja nulom). Zato je ključno da naše nezavisne varijable pokazuju značajan varijabilitet.
Brojilac predstavlja grešku regresije. Izračunavamo je deljenjem sume kvadrata odstupanja od regresione linije (SSE) sa stepenima slobode. Model ima dva nepoznata parametra (\(\beta_0\) i \(\beta_1\)), što znači da je broj stepeni slobode \(n-2\).
Dakle, standardna greška koeficijenta b1 (\(s_{b_1}\)) predstavlja odnos greške regresione linije i varijabiliteta nezavisne varijable. Mi zapravo merimo grešku regresije u odnosu na preciznost merenja \(X\). Za nisku vrednost standardne greške potrebna su nam dva elementa: regresiona linija koja minimizira odstupanja (što automatski dobijamo metodom najmanjih kvadrata) i nezavisna varijabla sa dovoljnim varijabilitetom.
Izračunajmo standardnu grešku koeficijenta nagiba za naš primer. Potrebni su nam sledeći elementi:
Primenjujemo formulu za standardnu grešku - imenilac je koren sume kvadrata odstupanja X od njegove srednje vrednosti.
Standardna greška koeficijenta nagiba: 0.00074
Za testiranje koristimo t-test. Ako je nulta hipoteza tačna (nema regresionog efekta), vrednost koeficijenta nagiba je 0. U tom slučaju, vrednosti nagiba u uzorku variraju oko nule, a te standardizovane varijacije prate t-raspodelu sa n-2 stepena slobode.
Jednostavnije rečeno - moguće je da regresija na nivou populacije ne postoji, a da mi u uzorku dobijemo malu (pozitivnu ili negativnu) vrednost zbog slučajnosti. T-testom proveravamo da li je vrednost koeficijenta nagiba iz uzorka statistički značajno različita od nule.
Računamo t-statistiku deljenjem koeficijenta nagiba sa standardnom greškom.
t-statistika: 4.35
Vrednost 4.35 se nalazi daleko u desnom repu t-raspodele. Za donošenje zaključka potrebna nam je p-vrednost. Naš model ima 58 stepeni slobode (60 opservacija - 2 nepoznata parametra). P-vrednost računamo pomoću funkcije pt koja izračunava vrednost t-raspodele. Pošto testiramo dvosmernu hipotezu, zanima nas verovatnoća da je t-statistika veća od 4.31 ili manja od -4.31.
Prikaži kod
p_vrednost <-2*pt(-abs(t_statistika), df = n -2)cat("p-vrednost:", round(p_vrednost, 3), "\n")
1
Računamo p-vrednost koristeći funkciju pt.
p-vrednost: 0
P-vrednost je toliko niska da je R zaokružuje na 0. Pred nama je jak dokaz za odbacivanje nulte hipoteze. Možemo zaključiti da postoji statistički značajan regresioni efekat na nivou populacije. Drugim rečima, linearna zavisnost između budžeta i kvaliteta zdravstvenog sistema nije ograničena samo na naš uzorak, već se može generalizovati na širu populaciju.
9.6.2 Interval poverenja za koeficijent nagiba
Sada kada imamo sve potrebne elemente, konstruisaćemo interval poverenja za koeficijent nagiba. Struktura ovog intervala je slična onoj iz prethodnog poglavlja, ali se ovde fokusiramo konkretno na \(b_1\) i njegovu standardnu grešku.
Formula za interval poverenja glasi:
\[
b_1 \pm t_{\alpha/2} \times S_{b_1}
\]
Hajde da ovo primenimo u praksi. Izabraćemo nivo poverenja od 95% i izračunati raspon vrednosti za koeficijent nagiba koristeći R.
Izračunavamo kritičnu vrednost t-raspodele za 95% nivo poverenja.
2
Konstruišemo interval poverenja za koeficijent nagiba.
Interval poverenja za koeficijent nagiba: 0.0017 0.0047
Zamislite da smo uzeli 100 različitih uzoraka iz populacije i za svaki izračunali regresioni model. U 95 od tih 100 slučajeva, koeficijent nagiba bi se našao između 0.0017 i 0.0046. Ovo nije samo teorijski koncept - možemo ga jasno prikazati na grafiku. Pogledajmo vizuelnu reprezentaciju:
Slika 9.16: Interval poverenja za koeficijent nagiba.
Pogledajmo pažljivo plavu osenčenu oblast na ovom grafikonu. Ona predstavlja opseg mogućih regresionih linija, uzimajući u obzir 95% interval poverenja i veličinu našeg uzorka. Ova vizualizacija nam elegantno prikazuje neizvesnost u našoj proceni regresione linije.
TipRazlika između linije i modela
U čemu je razlika između regresione linije i regresionog modela? Pogledajte pažljivo gornji grafikon - on elegantno ilustruje tu razliku. Plava neprekidna linija je regresiona linija koju smo dobili iz uzorka. Ali primetite plavu osenčenu oblast oko nje - to je regresioni model u punom smislu. Model obuhvata mnogo više od same linije jer uključuje sve neizvesnosti vezane za regresionu liniju. Te neizvesnosti su prikazane kroz interval poverenja.
Dakle, model nam pruža potpuniju sliku time što uzima u obzir varijabilnost koju sama linija ne može da predstavi. Ovo je ključni uvid: regresioni model nije samo jedna linija, već čitav prostor mogućih linija koje su konzistentne sa našim podacima. Kada shvatimo ovu razliku, jasnije vidimo zašto je model moćniji alat od proste linije - on nam govori ne samo šta očekujemo, već i koliko smo sigurni u ta očekivanja.
Primetićemo da se mnoge opservacije nalaze van plave oblasti mogućih regresionih linija. Čak i kada u obzir uzmemo neizvesnost koeficijenata, tačno predviđanje svih vrednosti kvaliteta zdravstvenog sistema ostaje izazov. Ovo je značajan uvid. Da bismo razumeli kako ove greške utiču na pouzdanost našeg modela, moramo sprovesti detaljnu dijagnostiku. Ovaj korak je ključan za razumevanje stvarnih mogućnosti i ograničenja regresionog modela pred nama.
9.7 Dijagnostika proste linearne regresije
Do sada smo primenili metod najmanjih kvadrata da bismo našli optimalnu regresionu liniju. Testiranjem hipoteza potvrdili smo da je nagib statistički značajan i konstruisali interval poverenja oko linije.
Sada prelazimo na analizu grešaka regresione linije - reziduale. Reziduali predstavljaju razlike između stvarnih i predviđenih vrednosti zavisne varijable. Centralna pretpostavka regresionog modela je da su reziduali slučajni. Drugim rečima, tretiramo ih kao čist šum - rezultat nasumičnih faktora koji onemogućavaju savršeno predviđanje. U našem primeru, to su svi nekontrolisani faktori koji utiču na kvalitet zdravstva, a nisu obuhvaćeni modelom. Pošto je ova greška slučajna, očekujemo da bude nezavisna od objašnjavajuće varijable i da prati normalnu raspodelu.
Zašto baš normalnu? Ako su reziduali zaista slučajni, prirodno je očekivati da budu simetrično raspoređeni iznad i ispod linije. Većina reziduala trebalo bi da bude umereno udaljena od linije, dok bi ekstremna odstupanja trebalo da budu retka. Ovaj obrazac odgovara upravo normalnoj raspodeli. Kada reziduali prate normalnu raspodelu, to je snažan indikator da naš model dobro opisuje podatke i da greška ne narušava njegovu validnost.
Hajde da ispitamo da li naši reziduali zadovoljavaju ove pretpostavke.
NoteZašto nenormalnost ugrožava validnost modela?
Nenormalna distribucija reziduala je jasan signal da naš regresioni model ne hvata nešto važno. To je kao da nam podaci šapuću: „Propustili ste nešto bitno“. Najčešće, ovo ukazuje na postojanje trećeg faktora koji utiče na naš model, a koji nismo uzeli u obzir.
Ovo direktno narušava našu ključnu pretpostavku o slučajnosti greške. Kada greška nije slučajna, već sistemska posledica izostavljenog faktora, naš model gubi pouzdanost. Ne možemo se više osloniti na njegova predviđanja, a posebno ne na koeficijent nagiba koji bi trebalo da nam pokaže jačinu veze između varijabli.
Kako rešiti ovaj problem? Odgovor leži u konstrukciji složenijeg modela koji će obuhvatiti više faktora. Međutim, to zalazi u područje naprednije statistike i prevazilazi okvire ovog udžbenika.
Drugi mogući uzrok nenormalnosti je nelinearan odnos između varijabli. Zamislite da pokušavate da opišete krivudavu liniju pravom - to jednostavno neće dati dobre rezultate. U takvim slučajevima, linearna regresija nije pravi alat za naš problem. Kako to možemo proveriti? Dijagram raspršenosti je naš prvi indikator - jasna zakrivljenost u rasporedu tačaka sugeriše da treba razmotriti nelinearne modele regresije.
Hajde da pogledamo kako izgleda distribucija reziduala u našem slučaju.
Postavljamo vrednosti koeficijenata \(b_0\) i \(b_1\).
2
Računamo rezidualne vrednosti
3
Pravimo histogram reziduala
4
Dodajemo krivu gustine reziduala
5
Dodajemo krivu normalne raspodele sa istom srednjom vrednošću i standardnom devijacijom kao i reziduali
6
Legenda u gornjem desnom uglu
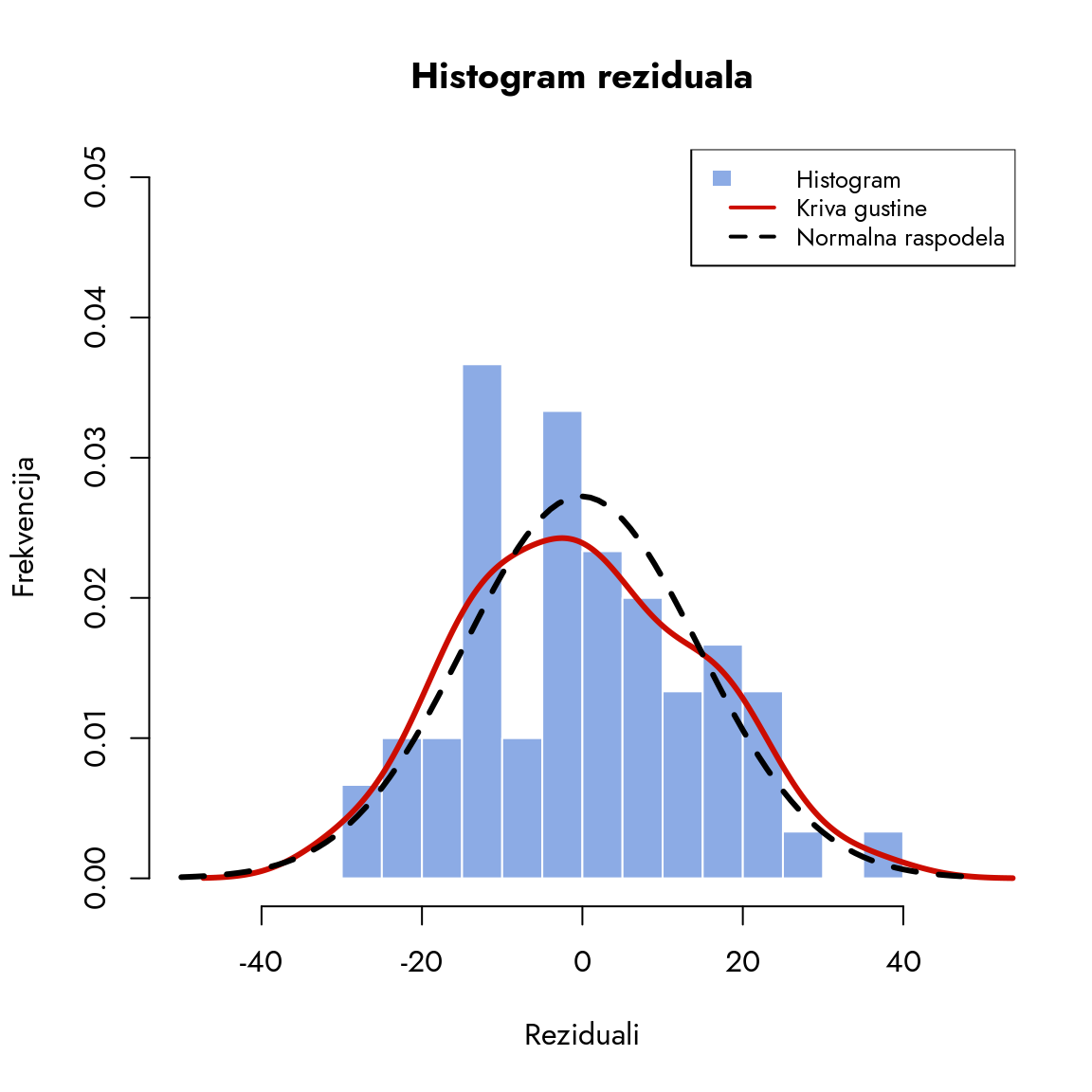
Slika 9.17: Histogram i kriva gustine reziduala
Šta nam otkriva ovaj grafikon? Crvena kriva distribucije reziduala odstupa od isprekidane normalne distribucije. Kako se razlikuju? Kriva reziduala je znatno spljoštenija. Ovo ukazuje da je greška više ravnomerno raspoređena u intervalu, bez ekstremnih vrednosti u repovima. Međutim, to takođe znači da nema koncentracije reziduala oko nule. Vizuelno, kriva gustine reziduala je relativno simetrična, slično normalnoj raspodeli.
Visoka spljoštenost ne narušava značajno validnost zaključka, ali upozorava da greška nije koncentrisana oko nule, već je ravnomerno raspoređena. Posledično, greška predviđanja može biti veća nego što bismo očekivali kod normalne raspodele.
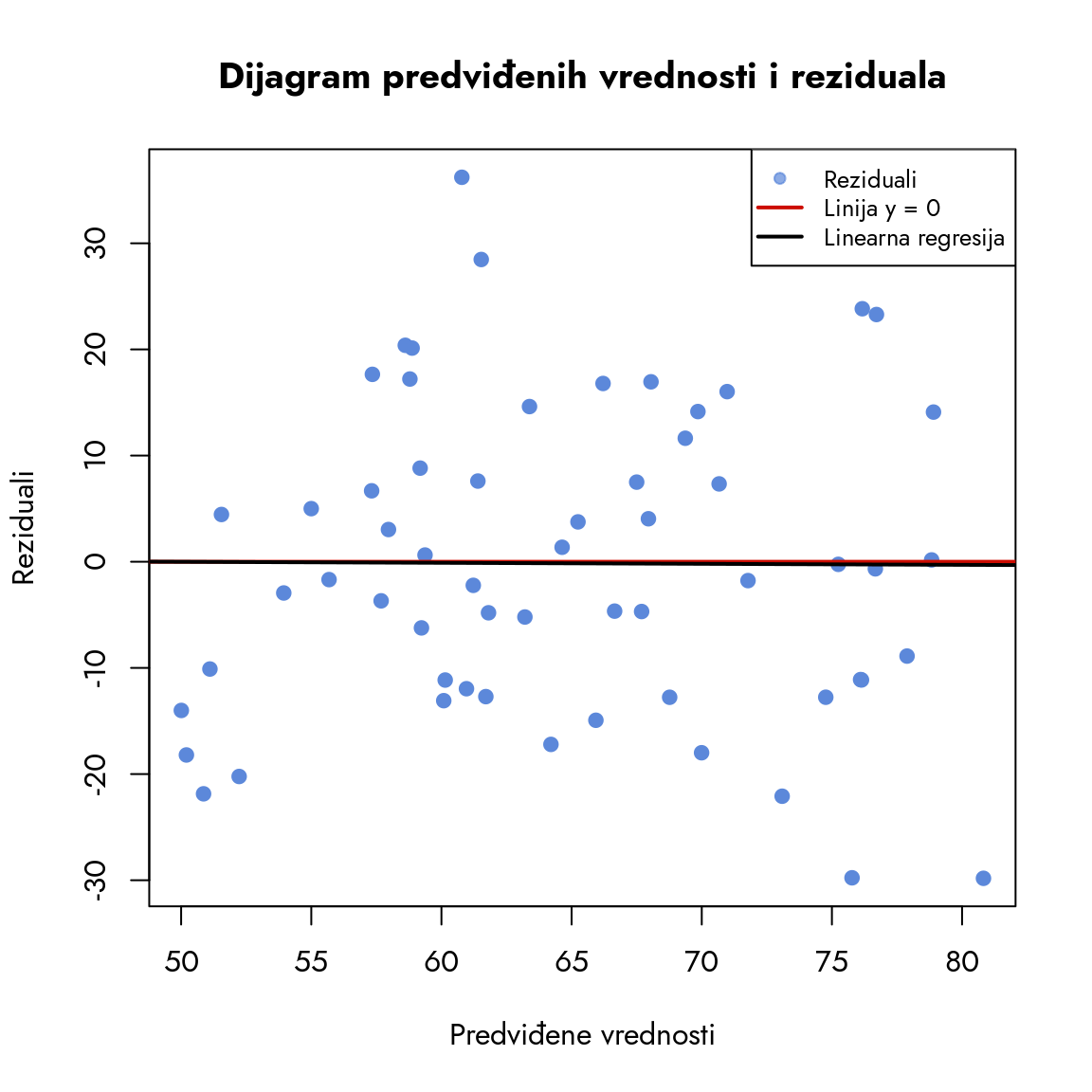
Drugi ključni dijagnostički pristup je analiza odnosa između predviđenih vrednosti i reziduala. U idealnom slučaju, ne bi trebalo da postoji veza između ovih veličina. Hajde da ispitamo taj odnos. Na x-osi ćemo prikazati predviđene vrednosti zavisne varijable iz regresione jednačine, a na y-osi reziduale. Ako su reziduali zaista slučajni, ne bi trebalo da uočimo nikakav obrazac. Prisustvo obrasca bi ukazivalo da je greška sistemski povezana sa nekim aspektom zavisne varijable koji nismo obuhvatili modelom.
Prikazujemo dijagram predviđenih vrednosti i reziduala
3
Dodajemo horizontalnu liniju na nuli
4
Pravimo regresiju između predviđenih vrednosti i reziduala
5
Dodajemo regresionu liniju
Slika 9.18: Dijagram predviđenih vrednosti i reziduala
Na grafikonu uočavamo da su tačke, odnosno parovi (predviđena vrednost, rezidual), raspoređeni gotovo nasumično i ne formiraju nikakav očigledan obrazac. Recimo, ne vidimo da se najveća negativna greška javlja kada je predviđena vrednost najmanja. Kada bismo podelili grafikon na kvadrante, videli bismo da su tačke ravnomerno raspoređene u sva četiri kvadranta.
Kako da potvrdimo ovu tvrdnju matematički? Na dijagramu, pored crvene horizontalne linije koja označava nulu, vidimo i crnu liniju. Ta crna linija predstavlja linearnu regresiju između predviđenih vrednosti i reziduala. Njen oblik nam govori sve - kada bi postojala značajna veza između predviđenih vrednosti i reziduala, linija bi imala primetan nagib. No, ona je gotovo savršeno horizontalna, što matematički potvrđuje odsustvo povezanosti između ovih veličina. To je jak dokaz da naš model adekvatno opisuje podatke.
NoteRegresija za dijagnostiku regresije?
Možda se pitate kako je moguće koristiti novu regresiju (predviđene vrednosti i reziduali) za dijagnostiku postojeće regresije? Ovo je prirodno pitanje. Odgovor je jednostavan - ne kreiramo novi model, već samo vizuelno prikazujemo trend između predviđenih vrednosti i reziduala pomoću regresione linije.
U sledećem poglavlju ćemo istražiti naprednije metode za analizu veze između predviđenih vrednosti i reziduala, ali trenutno je ovaj pristup sasvim dovoljan. Primetićete da smo postupak dobijanja regresione linije sveli na samo dve linije koda. Detaljno objašnjenje funkcije lm sledi na kraju ovog poglavlja, a njenu punu primenu ćete upoznati kroz ostatak udžbenika.
Ove metode predstavljaju osnovne oblike dijagnostike regresionog modela, s naglaskom na reziduale. Važno je razumeti da dijagnostika nije metod za donošenje zaključaka poput testiranja hipoteza. Umesto toga, ona nam otkriva dublju strukturu modela i njegove granice. Kako budemo napredovali kroz gradivo, upoznaćemo dodatne tehnike za merenje efikasnosti regresionog modela.
9.8 Regresioni model u R-u
Do sada smo korak po korak gradili regresioni model i vršili dijagnostiku koristeći osnovne R funkcije. R nam ipak nudi efikasnije alate za rad sa regresijom. Najvažnija među njima je funkcija lm (eng. linear model), koja nam omogućava brzu konstrukciju regresionog modela. Pogledajmo kako ova funkcija radi na našem primeru:
Prikaži kod
model <-lm(kvalitet ~ budzet, data = podaci)model
1
Konstruišemo regresioni model koristeći funkciju lm. Prvi argument je formula regresije, a drugi argument je skup podataka.
Funkcija lm koristi formulu za definisanje regresionog modela. U našem primeru, kvalitet ~ budzet označava da predviđamo kvalitet zdravstvenog sistema pomoću budžeta. R primenjuje ovakvu notaciju za sve modele: levo od znaka ~ nalazi se zavisna varijabla, a desno je formula modela, koja je u ovom slučaju jednostavno budzet. Ova R notacija direktno odgovara regresionoj jednačini koju smo ranije definisali.
Nakon što prikažemo model, dobijamo ključne komponente regresione jednačine - njene koeficijente. Intercept predstavlja \(b_0\) (slobodni član), dok ispod njega, uz oznaku budzet, nalazimo \(b_1\).
Za detaljniju analizu modela koristimo funkciju summary.
Prikaži kod
summary(model)
Call:
lm(formula = kvalitet ~ budzet, data = podaci)
Residuals:
Min 1Q Median 3Q Max
-29.523 -11.245 -0.986 9.639 36.324
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.907e+01 4.073e+00 12.05 < 2e-16 ***
budzet 3.170e-03 7.354e-04 4.31 6.4e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 14.77 on 58 degrees of freedom
Multiple R-squared: 0.2426, Adjusted R-squared: 0.2295
F-statistic: 18.58 on 1 and 58 DF, p-value: 6.404e-05
Hajde da proučimo rezultate našeg modela. Svaka linija ispisa nosi važne informacije:
Reziduali: Brojevi koji pokazuju koliko naš model odstupa od stvarnosti. Medijana od -0.986 ukazuje da je model prilično precizan. Najveće odstupanje je 36, a najmanje -29.523. Ovi brojevi nam daju jasan uvid u opseg grešaka modela.
Koeficijenti: Ovo je centralni deo našeg modela. Fokusirajmo se na red označen sa budzet. Tu nalazimo vrednost koeficijenta, standardnu grešku, t-statistiku i p-vrednost. Ovi brojevi potvrđuju rezultate koje smo ranije dobili manuelnim računanjem.
Rezidualna standardna greška (s): Vrednost koja kvantifikuje prosečno odstupanje predviđenih od stvarnih vrednosti. Manja greška ukazuje na precizniji model.
Koeficijent determinacije: Mera koja kvantifikuje koliko naš model objašnjava varijabilitet podataka. O ovome detaljnije u nastavku.
F-statistika: Test koji meri značajnost celokupnog modela. Ovaj koncept ćemo detaljnije obraditi u narednim poglavljima.
Zašto je ovaj pristup koristan? R nam je dao objekat model koji sadrži sve ključne informacije o našoj regresiji. Ovaj objekat je moćan alat za dalju analizu i testiranje.
Na primer, možemo lako dobiti reziduale koristeći funkciju residuals(model). Ovo nam omogućava brzu dijagnostiku i vizualizaciju rezultata.
Vredi napomenuti da funkcija residuals ne zahteva direktno podatke iz matrice, već koristi kompletan regresioni model. Ovaj model već sadrži sve potrebne informacije za izračunavanje reziduala.
Takav pristup nas prirodno vodi ka još jednom bitnom koraku u dijagnostici reziduala - analizi Kukove distance. Kukova distanca je precizan alat koji identifikuje opservacije sa ekstremnim rezidualima. Ovakve opservacije mogu narušiti normalnost reziduala i iskriviti odnos između reziduala i predviđenih vrednosti. Formula za Kukovu distancu je jednostavna:
U ovoj formuli, \(e_i\) su reziduali, \(s\) je greška regresije, a \(h_{ii}\) elementi dijagonale matrice \(H\), poznate kao matrica uticaja. Matrica \(H\) meri koliko pojedinačne opservacije utiču na regresioni model. Kako? Proces je jasan: izračunamo regresioni model bez svake pojedinačne opservacije i uporedimo ga sa originalnim modelom. Ako postoji velika razlika, ta opservacija ima značajan uticaj na model. Kukova distanca precizno kvantifikuje ovaj uticaj.
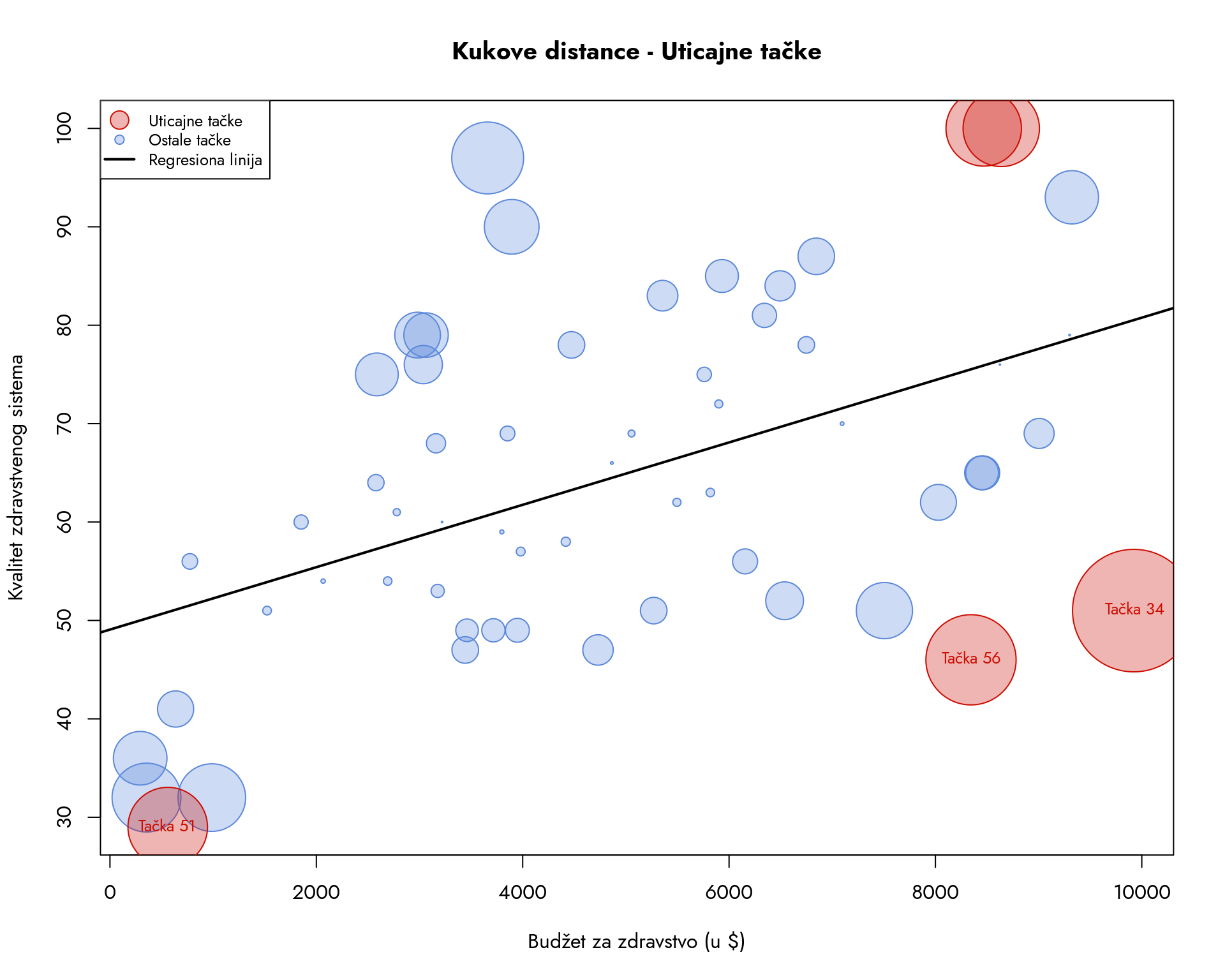
Opservacije sa visokom Kukovom distancom zaslužuju detaljniju analizu. One mogu značajno narušiti validnost modela i biti izvor sistemskih problema. Izračunajmo Kukove distance za naš model i analizirajmo rezultate.
Dobijene vrednosti su relativno male. Da bismo ih ispravno protumačili, potrebno je izračunati kritičnu vrednost za Kukove distance. Ova vrednost se računa kao \(\frac{4}{n-k-1}\), gde je \(n\) broj opservacija, a \(k\) broj nezavisnih varijabli. Opservacije čija je Kukova distanca iznad ove kritične vrednosti smatraju se značajno uticajnim za model.
U našem slučaju, s obzirom da koristimo prostu regresiju, imamo \(k = 1\) i \(n = 60\). Izračunajmo kritičnu vrednost:
\(\frac{4}{60-1-1} = \frac{4}{58} \approx 0.069\)
Sada možemo identifikovati sve opservacije čija je Kukova distanca veća od 0.069. Te opservacije zahtevaju detaljniju analizu jer mogu bitno uticati na parametre našeg modela.
Prikaži kod
granica <-4/ (nrow(podaci) -2)problemi <- podaci[kukove_distance > granica, ]cat("Opservacije sa velikom Kukovom distancom: \n")print(problemi)
1
Izračunali smo gornju granicu za Kukove distance
2
Identifikovali smo opservacije koje prelaze tu granicu
Pronašli smo pet država koje značajno odstupaju od modela: one pod brojevima 34, 37, 46, 51 i 56. Ovde vidimo zanimljiv obrazac - neke od njih imaju visoke budžete i visok kvalitet zdravstvenog sistema, dok druge beleže izrazito niske vrednosti za obe varijable.
Za bolju vizuelnu analizu, konstruisaćemo dijagram raspršenosti sa dodatnom dimenzijom. Na njemu će veličina svake tačke odgovarati njenoj Kukovoj distanci - što je tačka veća, to je njen uticaj na model značajniji. Problematične opservacije biće
Slika 9.19: Dijagram raspršenosti sa regresionom linijom i Kukovim distancama
Tačke koje smo identifikovali nalaze se na obodima dijagrama i značajno odstupaju od regresione linije. Ova situacija nije jedinstvena za regresiju - svi metodi koji koriste kovarijansu su osetljivi na ekstremne vrednosti.
Kako pristupiti ovim odstupajućim opservacijama? Prvi korak je provera tačnosti podataka. Greške pri unosu su česte, posebno u anketnim istraživanjima gde ispitanik može napraviti jednostavnu grešku - na primer, uneti „3“ umesto „33“ za godine starosti, što dramatično menja regresioni model.
Često istraživači eliminišu opservacije sa visokom Kukovom distancom. Ovo je metodološki problematično iz dva razloga: veštački poboljšava regresioni model i narušava slučajnost uzorka. Ispravan pristup je drugačiji - ako otkrijemo grešku u podacima, ispravljamo je i ponovno računamo model.
U našem primeru, identifikacija odstupajućih opservacija (tri sa najvećom Kukovom distancom su označene na dijagramu) poboljšava naše razumevanje zavisnosti. Država 51 pokazuje izrazito niske vrednosti obe varijable, dok opservacije 34 i 56 demonstriraju da visok budžet nije dovoljan uslov za visok kvalitet zdravstvenog sistema. Ovi uvidi su ključni za razumevanje složenosti odnosa koji analiziramo.
9.9 Objašnjenje i predviđanje
Interpretacija regresionog modela ima dva ključna aspekta: objašnjenje i predviđanje.
Objašnjenje: Regresioni model nam otkriva kako se jedna varijabla menja u zavisnosti od druge. U našem primeru jasno vidimo da kvalitet zdravstvenog sistema raste sa povećanjem budžeta. Kroz ovaj uvid saznajemo: - Da li postoji zajednička promena dve varijable? - U kom smeru se odvija ta promena? - Koliko je ta promena intenzivna?
Model nam takođe omogućava da identifikujemo koje opservacije značajno oblikuju ovaj odnos i da procenimo da li naši podaci pružaju dovoljno informacija za razumevanje veze između varijabli. Ovo nas vodi ka dubljoj teorijskoj analizi.
Predviđanje: Zamislite situaciju gde predstavljamo analizu donosiocima odluka. Njihovo ključno pitanje će verovatno biti: „Ako povećamo budžet za zdravstvo na 8500 dolara po glavi stanovnika godišnje, kakav kvalitet zdravstvenog sistema možemo očekivati?“. Regresiona analiza na ovo pitanje daje precizan, ali ograničen odgovor.
Regresija pokazuje izuzetnu preciznost u predviđanju prosečnih vrednosti zavisne varijable. To znači da pouzdano možemo proceniti prosečan kvalitet zdravstvenog sistema za zemlje sa određenim budžetom. Na primer, države koje izdvajaju 8500 dolara po glavi stanovnika u proseku dostižu ocenu kvaliteta oko 73. Kritično je razumeti - ovo ne znači da će svaka država koja poveća budžet na 8500 dolara nužno dostići ocenu 73.
Za procenu preciznosti regresije u predviđanju koristimo intervale poverenja. Počnimo sa intervalom poverenja za prosečnu vrednost regresije. Formula je složena, ali vredi je razumeti:
\(t_{\alpha/2}\) - kritična vrednost t-raspodele za 95% interval poverenja
\(s\) - standardna greška regresije
\(n\) - broj opservacija
\(x\) - vrednost nezavisne varijable za koju pravimo predviđanje (u našem primeru 8500)
\(\bar{x}\) - srednja vrednost nezavisne varijable
Izraz pod korenom je ključan za razumevanje preciznosti regresije. On nam pokazuje da je regresija najpreciznija kada je \(x\) blizu \(\bar{x}\). To znači da regresija najpouzdanije predviđa vrednosti koje su bliske proseku nezavisne varijable. Što se više udaljavamo od proseka, preciznost predviđanja opada.
Ovo je fundamentalan uvid u prirodu regresije - ona nije pouzdan alat za predviđanje ekstremnih ili neuobičajenih vrednosti. Regresija je najsnažnija u domenu prosečnih vrednosti, gde daje najpreciznije rezultate.
U narednom koraku ćemo vizuelno prikazati ovaj interval poverenja da bismo bolje sagledali njegove karakteristike.
Slika 9.20: Intervali poverenja za prosečnu vrednost i indivdiualne predikcije
Crvena linija predstavlja regresionu liniju. Crvene isprekidane linije označavaju intervale poverenja za srednju predviđenu vrednost. Primetite kako se ove linije savijaju sa leve i desne strane grafikona - nisu prave. To ilustruje važan koncept: interval je najuži u centru grafikona (u oblasti prosečnog budžeta) i postepeno se širi kako se udaljavamo od sredine. Ovo empirijski potvrđuje ranije objašnjenje - regresija daje najpreciznije rezultate u oblasti proseka. Osobina direktno proizlazi iz člana \(x - \bar{x}\) u formuli intervala poverenja.
Na grafikonu uočavamo i plave isprekidane linije. One su značajno udaljenije od centra i predstavljaju interval predviđanja za pojedinačna opažanja. Ovaj interval je primetno širi od intervala poverenja za srednju vrednost, što jasno ukazuje na manju preciznost pri predviđanju pojedinačnih opservacija.
Kada želimo predvideti specifičnu vrednost kvaliteta zdravstvenog sistema za određenu državu, neophodno je konstruisati interval poverenja oko proseka. Konstrukcija se zasniva na pretpostavci da opservacije oko predviđene vrednosti prate t-raspodelu. Praktično, to znači da će neke države imati rezultate iznad proseka, druge ispod, ali ne očekujemo ekstremna odstupanja. Na osnovu ove pretpostavke formiramo interval poverenja za predviđenu pojedinačnu vrednost. Ovaj interval je širi od intervala poverenja za srednju vrednost, odražavajući inherentnu neizvesnost pri predviđanju pojedinačnih slučajeva.
Razlika između ova dva intervala poverenja leži u dodatku „+1“ ispod korena. Ovaj mali dodatak značajno proširuje interval, ukazujući na znatno veću grešku individualnog predviđanja. Zašto? Kada predviđamo pojedinačnu vrednost, moramo uzeti u obzir ne samo grešku u proceni srednje vrednosti, već i slučajnu grešku - uticaj svih faktora koje nismo obuhvatili modelom. Širi interval pokazuje da na kvalitet zdravstva utiču mnogi faktori osim budžeta. Posledično, interval postaje toliko širok da gubi praktičnu upotrebljivost za individualna predviđanja.
Uzmimo konkretan primer sa grafikona. Za državu koja izdvaja 6000 dolara po glavi stanovnika za zdravstvo, naš model predviđa kvalitet zdravstvenog sistema između 35 i 95. Raspon je toliko širok da ne pruža nikakvu korisnu informaciju - zaključak koji bismo mogli izvesti i bez regresione analize.
Ovo nije mana regresionog modela, već prirodno ograničenje proste regresije. U stvarnom svetu društvenih nauka, retko koji fenomen možemo objasniti samo jednim prediktorom. Za preciznija predviđanja potrebne su naprednije metode multivarijacione analize koje mogu obuhvatiti više relevantnih faktora istovremeno.
9.10 Zaključak
Ovo poglavlje je zahtevalo strpljenje i fokus jer smo prošli kroz niz fundamentalnih koncepata. Razmotrimo glavni cilj regresione analize: opisivanje linearne zavisnosti jedne varijable od druge. U našem primeru, istraživali smo kako kvalitet zdravstvenog sistema zavisi od budžeta za zdravstvo.
Prevedeno na jezik geometrije, naš zadatak je bio pronaći pravu liniju koja optimalno opisuje odnos između dve varijable. Ova regresiona linija minimizuje odstupanja od svih opservacija. Za njeno pronalaženje primenili smo metod najmanjih kvadrata koji sistemski smanjuje grešku regresije.
Regresiona linija proizlazi iz podataka uzorka. Međutim, nas zanima zavisnost na nivou cele populacije, pa moramo proveriti da li linija iz uzorka verno predstavlja taj širi odnos. To postižemo testiranjem hipoteza i konstruisanjem intervala poverenja.
Nakon potvrde značajnosti modela na nivou populacije, prelazimo na dijagnostiku. Ona se temelji na analizi reziduala - odstupanja stvarnih od predviđenih vrednosti. Ključna pretpostavka je slučajnost reziduala. Ako su reziduali zaista slučajni, model je pouzdan. To proveravamo kroz tri ključne analize: normalnost reziduala, njihov odnos sa predviđenim vrednostima i Kukove distance.
U završnom delu razmotrili smo prediktivnu moć modela. Prosta linearna regresija efikasno predviđa prosečne vrednosti zavisne varijable, ali pokazuje ograničenja u predviđanju pojedinačnih vrednosti.
Svi ovi elementi zajedno otkrivaju složenost odnosa između dve kvantitativne varijable. Postoji još jedan važan aspekt ovog odnosa koji opisuje regresioni model - korelacija, koju ćemo detaljno istražiti u narednom poglavlju.
NoteLična karta metoda: prosta linearna regresija
Šta radi? Testira uticaj jedne kvantitativne varijable na drugu.
Kada se koristi? Kada želimo da predvidimo ili objasnimo vrednost jedne kvantitativne varijable pomoću druge.
Koliko varijabli imamo? Dve kvantitativne varijable merene na intervalnom ili racio mernom nivou. U posebnim slučajevima, varijable mogu biti ordinalne.
Kako glase hipoteze? Nulta hipoteza tvrdi da je koeficijent nagiba \(\beta_1\) jednak nuli, odnosno da ne postoji uticaj nezavisne varijable na zavisnu. Alternativna hipoteza tvrdi suprotno - da postoji uticaj.
Test statistika: T-test koristimo da proverimo da li je koeficijent nagiba različit od nule. Test statistiku izračunavamo deljenjem procenjenog koeficijenta nagiba njegovom standardnom greškom.
\[
t = \frac{\hat{b}_1}{s_{\hat{b}_1}}
\]
gde je \(\hat{b}_1\) procenjeni koeficijent nagiba, a \(s_{\hat{b}_1}\) njegova standardna greška.
Kako računamo p-vrednost? P-vrednost predstavlja dvostuku površinu ispod t-distribucije od vrednosti t-statistike do beskonačnosti. Drugim rečima, merimo kolika je verovatnoća da dobijemo vrednost t-statistike koja je jednaka ili ekstremnija od izračunate, pod pretpostavkom da je nulta hipoteza tačna.
9.11 Zadaci
CautionZadatak 1
U ovom zadatku analiziramo odnos između vremena provedenog na društvenim mrežama i akademskog uspeha studenata. Naši podaci sadrže informacije o prosečnom broju sati koje studenti dnevno provode na društvenim mrežama i njihovim prosečnim ocenama. Cilj nam je da pomoću proste linearne regresije ispitamo kako vreme na društvenim mrežama utiče na akademski uspeh.
Postupak ćemo izvesti kroz tri koraka:
Najpre ćemo kreirati dijagram raspršenosti koji vizuelno prikazuje odnos između ove dve varijable.
Zatim ćemo, korak po korak, izračunati koeficijente regresione linije koristeći metod najmanjih kvadrata.
Na kraju ćemo ucrtati dobijenu regresionu liniju na dijagram raspršenosti i interpretirati rezultate.
Za početak, učitajmo podatke:
Prikaži kod
podaci <-read.csv("https://gist.githubusercontent.com/atomashevic/17d9f2b7432ba72c926859924e5a9753/raw/b36866440b70d6098dc2081da332a63a312e8682/dm-prosek.csv")
CautionZadatak 2
Testirajtee hipotezu o postojanju linearne zavisnosti između vremena provedenog na društvenim mrežama i prosečne ocene studenata. Nivo značajnosti je 0.05. Bitno je da razumete i ispravno protumačite rezultate testa.
CautionZadatak 3 *
Testirajte hipotezu da vreme provedeno na društvenim mrežama ima negativan uticaj na prosečnu ocenu studenata. Postavite nivo značajnosti na 0.05. Protumačite rezultate testa i analizirajte kako se razlikuju od rezultata iz Zadatka 2.
CautionZadatak 4 *
Uradite punu dijagnostiku dobijenog regresionog modela.
Normalnost reziduala
Odnos između reziduala i predviđenih vrednosti
Kukove distance
Na osnovu sva tri metoda dijagnostike, napišite jedan paragraf teksta koji objašnjava aspekte odnos korišćenja društvenih mreža i akademskog uspeha u odnosu na ono što nam govori dijagnostika reziduala.
CautionZadatak 5 **
Zamislite da se od vas traži (iako nema previše smisla) obrnuta analiza - da predviđate vreme provedeno na društvenim mrežama na osnovu prosečne ocene studenata.
Koristeći lm funkciju, konstruišite regresioni model i interpretirajte rezultate. Razmislite kako se koeficijenti razlikuju u odnosu na prethodnu analizu. Kako interpretirate rezultate ovog modela?