U prethodnim poglavljima upoznali smo različite statističke metode. Krenuli smo od t-testa za jedan uzorak, prešli na t-test za dva uzorka, zatim na regresiju, korelaciju i ANOVA-u, i konačno stigli do regresione analize. Kroz ovaj proces otkrivali smo duboke veze između ovih naizgled različitih metoda.
Posebno je zanimljivo kako su koeficijent nagiba regresije i Pirsonov koeficijent korelacije zapravo dva lica iste pojave - načini da kvantifikujemo kovarijansu između dve varijable. Kada izračunamo koeficijent korelacije, mi zapravo dobijamo geometrijsku sredinu dva koeficijenta nagiba: jedan iz regresije gde je prva varijabla zavisna, a drugi iz regresije gde je ona nezavisna promenljiva.
Videli smo da ANOVA efikasno rešava problem višestrukog testiranja hipoteza. Ona nam omogućava da istovremeno testiramo više grupa, bez povećanja verovatnoće greške tipa I. Post-hoc testovi nam precizno pokazuju koje grupe se međusobno razlikuju, ispravljajući ograničenja standardnog t-testa.
Regresiona analiza se prirodno nadovezuje na ANOVA-u, pri čemu kategoričku varijablu zamenjujemo kvantitativnom. Dekompozicija varijanse, koja je ključna za ANOVA-u, ima svoju paralelu u regresionoj analizi gde ispitujemo odnos između regresionog i rezidualnog dela ukupnog varijabiliteta zavisne varijable.
Ove veze nisu slučajne niti su tu da zbune istraživača pri odabiru metoda. One ukazuju na duboku povezanost između svih analiza koje smo predstavili u ovom udžbeniku. Na kraju, one razotkrivaju i prividnu nejasnoću u samom nazivu udžbenika - sve ove analize su manifestacije jednog jedinstvenog statističkog okvira: opšteg linearnog modela.
12.2 Opšti linearni model
Ponovo se vraćamo na linije. Sve što smo radili kroz ovaj udžbenik svodi se na jedan princip - pronalaženje linije koja najbolje opisuje odnos između dve varijable. U regresiji i korelaciji smo to direktno prikazali kroz vizualizacije na dijagramu raspršenosti. Iako za neke druge analize, poput ANOVA-e i t-testa, nismo eksplicitno crtali linije, osnovni princip ostaje isti.
Da bismo razumeli kako konstruišemo ove linije, moramo sagledati problem na opštijem nivou. U svim predstavljenim analizama radimo sa dve varijable: jednom zavisnom i jednom nezavisnom. Opšti linearni model je statistički okvir koji može predstaviti odnos između ove dve varijable kroz linearnu funkciju.
Opšti linearni model u svom osnovnom obliku možemo zapisati kao:
\[
Y = BX + U
\]
gde je \(Y\) zavisna varijabla, \(X\) nezavisna varijabla, \(B\) predstavlja koeficijente modela, a \(U\) njegovu grešku. Ovaj model je osnova za sve analize koje smo predstavili u ovom udžbeniku. Koristimo \(B\) kao jedinstvenu oznaku koja sadrži koeficijente modela jer, kao što ćemo videti, u nekim situacijama model može imati više od jednog koeficijenta.
Interpretacija koeficijenata modela zavisi od prirode varijabli koje koristimo. Ovo možemo najbolje ilustrovati na primeru koji obuhvata različite tipove varijabli, što će nam omogućiti da demonstriramo primenu svih analiza kroz perspektivu linearnog modela.
Razmotrimo podatke iz anketnog istraživanja o medijskom ponašanju građana. Glavni fokus je na samoproceni ispitanika o vremenu koje provode prateći političke vesti kroz različite medije (TV, radio, štampani mediji, internet). Uz to, prikupljeni su i podaci o izlaznosti na prethodnim parlamentarnim izborima, starosti i obrazovanju ispitanika. Varijable su organizovane na sledeći način:
pracenje_vesti - vreme provedeno u praćenju političkih vesti u minutima dnevno
glasao - učešće ispitanika na prethodnim izborima (vrednosti „Da“ i „Ne“)
starost - starost ispitanika u godinama
obrazovanje - stepen obrazovanja ispitanika (vrednosti „Osnovno“, „Srednje“, „Više“)
Pogledajmo kako možemo primeniti opšti linearni model na ovim podacima. Počećemo sa analizom odnosa između praćenja vesti i izlaznosti na izbore.
12.3 Alternativni t-test
U ovom primeru konstruišemo model: pracenje_vesti ~ glasao. Zavisna varijabla je pracenje_vesti, a nezavisna varijabla je glasao. Nezavisna varijabla je binarna i kategorička.
Ovo je klasičan primer t-testa, ali ovde ga posmatramo kao deo opšteg linearnog modela. Kako primeniti ovaj model u našem slučaju? Model možemo zapisati u sledećem obliku:
\[
Y = B_DA + B_{NE} X_{NE} + U
\]
Pogledajmo šta se ovde dešava. Model ima dva koeficijenta: \(B_{DA}\) i \(B_{NE}\). Grupa ispitanika koji su odgovorili „Da“ na pitanje o glasanju je referentna grupa. To znači da je koeficijent modela (koji u regresiji nazivamo slobodnim koeficijentom) zapravo aritmetička sredina vrednosti zavisne varijable za ovu grupu. Koeficijent \(B_{NE}\) predstavlja razliku između referentne grupe i grupe ispitanika koji nisu glasali. U regresiji, ovo je ono što nazivamo koeficijentom nagiba.
NoteIndikatorske varijable
Varijablu \(X_{NE}\) nazivamo indikatorska ili dummy varijabla. Ona nastaje transformacijom početne varijable glasao u numeričku binarnu varijablu gde vrednost 1 označava da ispitanik nije glasao, a 0 da jeste. Ova transformacija nam omogućava da koristimo kategoričke varijable u linearnim modelima.
Za neke kategoričke varijable nije dovoljna samo jedna indikatorska varijabla. U tim slučajevima koristimo više indikatorskih varijabli, pri čemu svaka predstavlja jednu kategoriju. Na primer, za varijablu obrazovanje referentna kategorija je „Osnovno“, pa koristimo dve indikatorske varijable za „Srednje“ i „Visoko“. Kombinacijom ove dve varijable, koje mogu imati vrednost 0 ili 1, možemo da rekonstruišemo sve tri kategorije obrazovanja.
Srednje obrazovanje
Visoko obrazovanje
Kategorija
0
0
Osnovno
1
0
Srednje
0
1
Visoko
Ovim pristupom transformišemo kategoričke podatke u format koji linearni modeli mogu da obrade. Kada kodiramo kategoričke varijable na ovaj način, možemo precizno meriti kako svaka kategorija utiče na zavisnu varijablu. Na primer, možemo direktno izmeriti koliko kategorija „Visoko“ utiče na zavisnu varijablu u poređenju sa referentnom kategorijom „Osnovno“.
Kroz opšti linearni model u ovom slučaju saznajemo prosečnu razliku u vremenu praćenja političkih vesti između onih koji su glasali i onih koji nisu. Model nam daje jasan uvid u to koliko minuta dnevno više ili manje provode apsitenti u odnosu na birače prateći političke vesti. Ako je koeficijent koji opisuje ovu razliku statistički značajan, možemo zaključiti da uočena razlika nije slučajna već postoji i na nivou cele populacije.
Pogledajmo kako to izgleda u praksi koristeći R.
Prikaži kod
podaci <-read.csv("https://gist.githubusercontent.com/atomashevic/8cfc7453347471c26ea0892a1a946c4e/raw/0c2682066f2a298d73d52405ca87e7ae45c28726/politika.csv")model_1 <-lm(pracenje_vesti ~ glasao, data = podaci)summary(model_1)
1
Primenjujemo linearni model na podatke koristeći funkciju lm. Zavisna varijabla je pracenje_vesti, a nezavisna varijabla je glasao.
Call:
lm(formula = pracenje_vesti ~ glasao, data = podaci)
Residuals:
Min 1Q Median 3Q Max
-52.589 -21.589 -0.837 20.163 94.411
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 52.589 1.235 42.584 <2e-16 ***
glasaoNe -3.751 1.897 -1.978 0.0482 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 29.64 on 998 degrees of freedom
Multiple R-squared: 0.003905, Adjusted R-squared: 0.002907
F-statistic: 3.912 on 1 and 998 DF, p-value: 0.04821
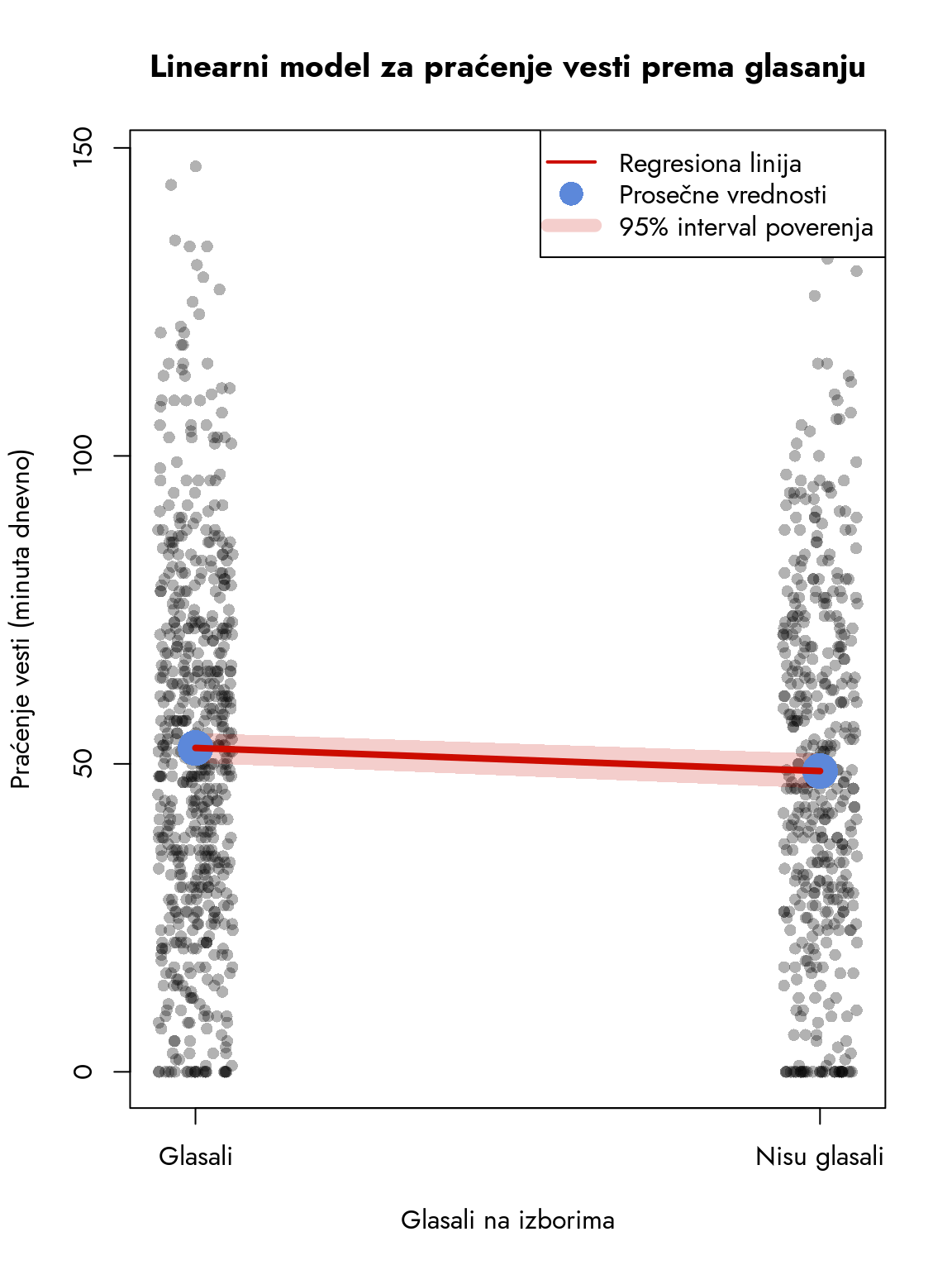
Pogledajmo tabelu sa koeficijentima. Drugi red nosi oznaku glasaoNe, gde vidimo da je vrednost koeficijenta \(B_{NE}\) jednaka -3.751. Ova vrednost nam pokazuje da ispitanici koji nisu glasali u proseku prate vesti o politici 3.751 minuta manje dnevno u poređenju sa onima koji su glasali. Standardna greška ovog koeficijenta iznosi 1.897, što daje t-vrednost od -1.98. P-vrednost je nešto manja od 0.05, što nas dovodi do zaključka da je uočena razlika statistički značajna.
Dakle, pokazali smo da postoji merljiva razlika u praćenju vesti između birača i apstinenata. Preciznije, utvrdili smo da izlazak na izbore ima jasan efekat na vreme provedeno u praćenju političkih vesti - oni koji nisu glasali u proseku provedu nekoliko minuta manje dnevno prateći politička dešavanja.
Kada pogledamo rezultate, vidimo da je Intercept koeficijent jednak 52.589, što predstavlja \(B_{DA}\), odnosno aritmetičku sredinu vrednosti zavisne varijable za referentnu grupu. Rezultati F-testa, koji upoređuje objašnjenu i neobjašnjenu varijansu modela, takođe su zanimljivi. Test je statistički značajan (\(p=0.04\)), a F-statistika od 3.91 nam pokazuje da model uspešno objašnjava značajan deo ukupne varijanse.
Da bismo potvrdili valjanost ove specifikacije modela, uporedićemo rezultate sa klasičnim t-testom koristeći funkciju t.test u R-u.
Izdvajamo vrednosti zavisne varijable za apstinente.
3
Primenjujemo t-test na ove dve grupe.
Welch Two Sample t-test
data: biraci and apsistenti
t = 1.9895, df = 930.23, p-value = 0.04694
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.05090431 7.45165072
sample estimates:
mean of x mean of y
52.58854 48.83726
Dobijamo identične rezultate koji nas vode ka istom zaključku. Svaki linearni model proizvodi najmanje dva koeficijenta koje možemo iskoristiti za konstrukciju linije. Ali kakva je to linija u slučaju t-testa?
Slika 12.1: Linearni model za praćenje vesti prema glasanju
Ova linija povezuje dve aritmetičke sredine i predstavlja suštinu t-testa kroz perspektivu linearnog modela. Slobodni koeficijent \(B_{DA}\) označava aritmetičku sredinu referentne grupe, dok \(B_{NE}\) pokazuje razliku između aritmetičkih sredina dve grupe. Pošto je koeficijent nagiba negativan, linija opada i pokazuje da ispitanici koji nisu glasali u proseku manje vremena posvećuju praćenju vesti.
Upravo ova jednostavna geometrijska interpretacija - linija koja povezuje dve aritmetičke sredine - daje nam jasan uvid u to kako t-test za dva nezavisna uzorka funkcioniše kao poseban slučaj opšteg linearnog modela.
12.4 Regresija i korelacija kao liearni model
Sada ćemo ispitati vezu između vremena provedenog u praćenju političkih vesti i starosti ispitanika. Ovaj odnos možemo predstaviti elegantno prostim linearnim modelom:
\[
Y = B_0 + B_1X + U
\]
gde je \(Y\) vreme provedeno u praćenju političkih vesti, \(X\) starost ispitanika, \(B_0\) slobodni koeficijent, \(B_1\) koeficijent nagiba, a \(U\) greška modela.
Slobodni koeficijent \(B_0\) ima jasnu interpretaciju - to je aritmetička sredina zavisne varijable kada je vrednost nezavisne varijable nula. U našem slučaju ta vrednost nema praktičnog smisla jer bi predstavljala procenu vremena koje novorođenče provodi prateći političke vesti. Bez obzira na to, koeficijent \(B_1\) nam daje korisnu informaciju - on pokazuje prosečnu promenu u vremenu praćenja vesti za svaku dodatnu godinu starosti ispitanika.
Pogledajmo kako to izgleda u R-u.
Prikaži kod
model_2 <-lm(pracenje_vesti ~ starost, data = podaci)summary(model_2)
1
Primenjujemo linearni model na podatke koristeći funkciju lm. Zavisna varijabla je pracenje_vesti, a nezavisna varijabla je starost.
Call:
lm(formula = pracenje_vesti ~ starost, data = podaci)
Residuals:
Min 1Q Median 3Q Max
-61.085 -20.929 -0.429 19.563 93.422
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 30.74442 3.03477 10.131 < 2e-16 ***
starost 0.44772 0.06395 7.001 4.66e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 28.99 on 998 degrees of freedom
Multiple R-squared: 0.04681, Adjusted R-squared: 0.04586
F-statistic: 49.01 on 1 and 998 DF, p-value: 4.662e-12
Vidimo da slobodni koeficijent iznosi približno pola sata, dok je koeficijent nagiba 0.4. To nam pokazuje da se vreme provedeno u praćenju vesti o politici povećava za 0.4 minuta dnevno sa svakom dodatnom godinom starosti ispitanika. T-statistika od 7 i p-vrednost bliska nuli jasno ukazuju na statističku značajnost ove veze. F-statistika od 49 potvrđuje snagu modela - varijansa objašnjena modelom značajno nadmašuje neobjašnjenu varijansu.
Model nam ne daje direktnu informaciju o korelaciji između varijabli, ali poznajemo koeficijent determinacije \(R^2 = 0.04681\). Iz njega možemo jednostavno izračunati koeficijent korelacije u R-u.
Prikaži kod
r =sqrt(summary(model_2)$r.squared)cat("Koeficijent korelacije je:", round(r, 2))
1
Izračunavamo koeficijent korelacije iz koeficijenta determinacije dobijenog iz rezultata linearnog modela.
Koeficijent korelacije je: 0.22
Dobili smo pozitivnu korelaciju umerenog intenziteta između vremena provedenog u praćenju političkih vesti i starosti ispitanika. Linearni model nam je tako pružio sve informacije potrebne za interpretaciju i regresionog i korelacionog odnosa između dve kvantitativne varijable. Ova veza je očekivana i intuitivna - sa godinama raste interesovanje za političke teme i vesti.
12.5 Alternativna ANOVA
Zamenom starosti sa obrazovanjem u prethodnom primeru dobijamo linearni model koji odgovara modelu opisanom u prethodnom poglavlju. S obzirom na to da obrazovanje ima tri kategorije, model će imati sledeći oblik:
\[
Y = B_{O} + B_{S}X_{S} + B_{V}X_{V} + U
\]
gde su \(B_{O}\), \(B_{S}\) i \(B_{V}\) koeficijenti modela, a \(X_{S}\) i \(X_{V}\) indikatorske varijable koje označavaju da li ispitanik ima srednji ili visoki stepen obrazovanja. \(B_O\) predstavlja aritmetičku sredinu vrednosti zavisne varijable za referentnu grupu, dok \(B_S\) i \(B_V\) predstavljaju razlike između aritmetičke sredine referentne grupe i grupa koje se upoređuju.
Pogledajmo kako to izgleda u praksi koristeći R.
Prikaži kod
model_3 <-lm(pracenje_vesti ~ obrazovanje, data = podaci)summary(model_3)
1
Primenjujemo linearni model na podatke koristeći funkciju lm. Zavisna varijabla je pracenje_vesti, a nezavisna varijabla je obrazovanje.
Call:
lm(formula = pracenje_vesti ~ obrazovanje, data = podaci)
Residuals:
Min 1Q Median 3Q Max
-68.233 -20.388 -0.388 18.843 87.612
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 40.463 2.207 18.334 < 2e-16 ***
obrazovanjeSrednje 6.925 2.482 2.790 0.00538 **
obrazovanjeVisoko 27.771 2.889 9.612 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 28.09 on 997 degrees of freedom
Multiple R-squared: 0.1061, Adjusted R-squared: 0.1043
F-statistic: 59.17 on 2 and 997 DF, p-value: < 2.2e-16
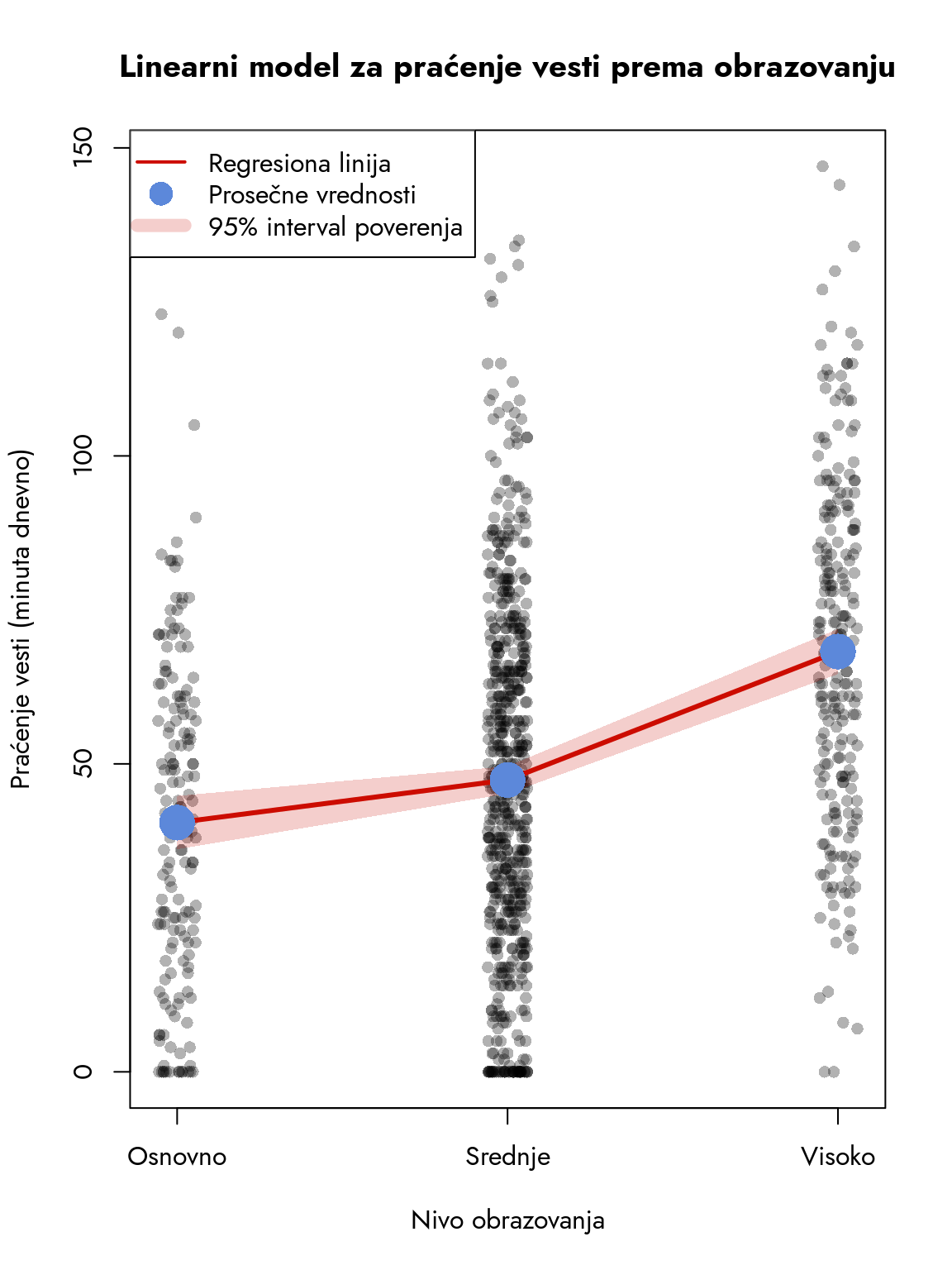
Analiza rezultata pokazuje nekoliko ključnih elemenata. Prvo, oba \(B\) koeficijenta su pozitivna i statistički značajna, što ukazuje na jasnu razliku u prosečnom vremenu praćenja političkih vesti između posmatranih grupa i referentne grupe. F-statistika od 59.17 sa p-vrednošću blizu 0 odbacuje omnibus nultu hipotezu o jednakosti svih koeficijenata modela. Koeficijent determinacije približno iznosi 0.1, što znači da model objašnjava 10% varijanse zavisne varijable.
Rezultate ovog linearnog modela možemo predstaviti grafički kroz linije na dijagramu raspršenosti. Postavlja se pitanje - kako konstruisati liniju kada imamo tri koeficijenta umesto uobičajena dva?
Rešenje leži u konstrukciji dva povezana linearna segmenta. Prvi segment prikazuje razliku između aritmetičke sredine referentne grupe i grupe sa srednjim obrazovanjem, dok drugi segment pokazuje razliku između aritmetičkih sredina grupa sa srednjim i visokim obrazovanjem. Ova dva segmenta spajaju se u tački koja predstavlja aritmetičku sredinu grupe sa srednjim obrazovanjem, formirajući jedinstvenu sliku odnosa između nivoa obrazovanja i vremena praćenja vesti.
Slika 12.2: Linearni model za praćenje vesti prema obrazovanju
Na osnovu ovog grafičkog prikaza jasno se vidi porast vremena provedenog u praćenju političkih vesti sa višim nivoom obrazovanja ispitanika. Crveno osenčena oblast oko linije predstavlja interval poverenja - našu procenu neizvesnosti u ovom odnosu. Kada kombinujemo vizualni prikaz sa numeričkim rezultatima linearnog modela, dobijamo preciznu sliku o tome kako stepen obrazovanja utiče na vreme koje ispitanici posvećuju praćenju političkih vesti.
Kroz ova tri primera demonstrirali smo kako se naizgled različite statističke analize mogu svesti na različite specifikacije opšteg linearnog modela. Model nam pruža moćan i jednostavan alat za opisivanje odnosa između dve varijable kroz linearnu funkciju. Ovakav pristup nam otkriva suštinsko jedinstvo svih statističkih analiza koje smo obradili u ovom udžbeniku.
12.6 Šta dalje?
Stigli smo do kraja udžbenika gde naše putovanje kroz statističko zaključivanje i konstrukciju statističkih modela završavamo prostim linearnim modelom.
Važno je razumeti da ovaj udžbenik nije zamišljen kao priručnik za primenu statističkih metoda, već kao vodič za razumevanje njihove suštine. Nismo se fokusirali na mehaničko praćenje koraka ili proveru uslova za primenu određenih metoda. Umesto toga, cilj je bio da shvatite logiku koja stoji iza statističkih metoda - ne da biste ih samo primenjivali, već da biste mogli da koristite to razumevanje kada razmišljate o istraživačkim problemima.
Mnogi izazovi u primeni statistike u društvenim i drugim naukama nastaju jer se statistička analiza često tretira kao završna faza istraživanja, a ne kao njegov integralni deo. Ovo dovodi do problema poput pogrešne upotrebe p-vrednosti, nerazumevanja koncepta efekta ili nagomilavanja grešaka u zaključivanju. Jedini put ka rešenju je razvijanje dublje intuicije o procesu statističkog zaključivanja i njegovim ključnim elementima.
Kada osmišljavamo istraživanje, biramo varijable i njihove merne skale, potrebna nam je intuicija o tome kako bi mogla izgledati kovarijansa između određenih varijabli, kakva bi mogla biti distribucija razlika između grupa, koja je očekivana veličina efekta, i da li je potrebno testirati jednosmernu ili dvosmernu hipotezu. Ova intuicija je ključna za kvalitetno istraživanje.
12.7 Preporuke za nastavak putovanja
Materijal predstavljen u ovom udžbeniku je prvi korak u izgradnji intuicije. Ipak, on je ograničen na relativno jednostavne primere koji služe za ilustraciju osnovnih ideja.
Ako želite da nastavite sa produbljivanjem razumevanja statističkog zaključivanja, pred vama su tri glavna pravca:
multivarijantna analiza,
strukturno modeliranje,
bejzijanska statistika.
Multivarijantna analiza će vam omogućiti da u potpunosti savladate opšti linearni model koji može obuhvatiti različite kombinacije zavisnih i nezavisnih varijabli. Ova analiza se može proširiti i na latentne konstrukte - varijable koje ne možemo direktno meriti, što je posebno bitno u društvenim naukama. Ovaj pravac će vas voditi kroz niz naprednih metoda: eksploratornu faktorsku analizu, analizu glavnih komponenti, kanoničku korelaciju, diskriminantnu analizu, logističku regresiju i hijerarhijske modele.
Odličan prvi korak u ovom pravcu je udžbenik Regression and Other Stories(Gelman i ostali, 2020) (dostupan besplatno ovde). Iako ne pokriva sve navedene metode i modele, predstavlja izvrstan vodič kroz multivarijantnu analizu zasnovanu na opštem linearnom modelu i linearnoj regresiji.
Drugi pravac je strukturno modeliranje koje se bavi modelovanjem složenih odnosa između varijabli, posebno kada su te varijable latentne. Ovaj pristup je od ključnog značaja u psihologiji, sociologiji, ekonomiji i drugim društvenim naukama. On vas vodi ka upoznavanju modela kao što su: SEM (strukturno jednačenje modela), LCA (latentna klasna analiza), LTA (latentna tranziciona analiza) i drugi.
Za temeljno razumevanje strukturalnog modeliranja, preporučujem serijal predavanja Saše Epskampa (Epskamp, 2019a, 2019b) dostupnih kroz kurseve SEM1 i SEM2.
Na kraju, bejzijanska statistika predstavlja sasvim drugačiji pristup statističkom zaključivanju koji uspostavlja neposredniju vezu između osnovnih principa verovatnoće (koje smo upoznali u ovom udžbeniku) i procesa zaključivanja. Najbolji resurs i najprirodniji način za izgradnju intuicije o bilo kom obliku statističkog zaključivanja je knjiga i kurs Statistical Rethinking(McElreath, 2020). Iako knjiga nije besplatno dostupna, kompletan sadržaj kursa zasnovanog na knjizi, uključujući video snimke predavanja, možete besplatno pronaći ovde.
Na kraju, ovaj udžbenik dopunjuje kolekciju izdvanja Filozofskog fakulteta u Novom Sadu koja se bave statističkim metodama u društvenim naukama. Ovi resursi su besplatno dostupni studentima i svim zainteresovanima. Udžbenici pokrivaju oblasti deskriptivne statistike (Sokolovska, 2013), tehnike vizualizacije u bazičnoj statistici (Pajić, 2020) i tehnike vizualizacije u naprednoj statistici i statističkom zaključivanju (Jevremov, 2023).
Koji god put daljeg učenja da odaberete, nadam se da ćete u njemu pronaći inspiraciju i intelektualno zadovoljstvo!
12.8 Zadaci
Ovo poglavlje nema nove zadatke. Umesto toga, vratite se na zadatke iz prethodnih poglavlja i rešite ih koristeći funkciju lm u R-u. Time ćete utvrditi razumevanje opšteg linearnog modela i njegove povezanosti sa svim statističkim metodama koje smo obradili.
Epskamp, S. (2019a). SEM1 (2019) - Stats Recap.
Epskamp, S. (2019b). SEM2 Lecture 1 - Expectation and Covariance Algebra.
Gelman, A., Hill, J., & Vehtari, A. (2020). Regression and Other Stories (1st edition). Cambridge University Press.
Jevremov, T. (2023). Primena tehnika vizualizacije u naprednoj statistici. Filozofski fakultet.
McElreath, R. (2020). Statistical Rethinking: A Bayesian Course with Examples in R and Stan (Second edition). CRC Press.
Pajić, D. (2020). Primena tehnika vizualizacije u bazičnoj statistici (str. 290). Filozofski fakultet.
Sokolovska, V. (2013). Deskriptivna statistika. Filozofski fakultet.