Prikaži kod
podaci <- read.csv("https://sm.atomasevic.com/data/kandidati.csv")
head(podaci) kandidat mladi
1 Ana 0
2 Bogdan 1
3 Bogdan 0
4 Ana 0
5 Ana 0
6 Ana 0Teorija verovatnoće je matematička disciplina koja nam omogućava da kvantifikujemo neizvesnost i donosimo zaključke u situacijama gde imamo ograničene informacije o događajima i njihovim ishodima.
Ova definicija može delovati apstraktno, ali teorija verovatnoće je zapravo veoma praktičan alat koji prožima sve naučne discipline. Nije slučajno što se često naziva „logikom nauke“ (Jaynes, 2003). Da bismo razumeli njenu moć i praktičnu vrednost, počećemo od osnovnih koncepata i videti kako se oni primenjuju kroz praktične primere u programskom jeziku R.
Osnovni pojam teorije verovatnoće je eksperiment. Eksperiment u ovom kontekstu predstavlja nešto sasvim drugačije od eksperimenta u fizici ili hemiji. Eksperiment je bilo koja situacija u kojoj postoji neizvesnost o tome šta će se desiti.
Uzmimo za primer bacanje kockice. To je idealan primer eksperimenta jer ne možemo sa sigurnošću predvideti ishod. Kada bacimo kockicu, može se dogoditi jedan od šest mogućih ishoda. Događaj predstavlja konkretnu realizaciju eksperimenta, tokom koje se ostvario jedan od tih mogućih ishoda.
Da pojednostavimo ovaj koncept. Kada bacite kockicu i ona pokaže broj 3, „bacanje kockice“ je naš eksperiment, „kockica je pokazala 3“ je događaj koji se odigrao, a sam broj 3 je ishod tog eksperimenta. Ovo razlikovanje između eksperimenta, događaja i ishoda je ključno za razumevanje teorije verovatnoće.
Verovatnoća je mera izvesnosti događaja - broj između 0 i 1 koji nam govori koliko je verovatno da će se određeni događaj ostvariti. Vrednost 0 označava nemoguć događaj, dok vrednost 1 označava izvestan događaj koji će se sigurno desiti.
Za računanje verovatnoće neophodno je razumeti strukturu eksperimenta: koliko mogućih ishoda postoji i kako se događaj koji nas zanima uklapa u tu strukturu.
Uzmimo praktičan primer: želimo izračunati verovatnoću da kockica pokaže paran broj. Ovaj događaj se može ostvariti kada kockica pokaže 2, 4 ili 6. Bacanje kockice ima ukupno 6 mogućih ishoda, pri čemu je svaki ishod jednako verovatan. Verovatnoća ovog događaja je stoga 3/6, odnosno 0.5.
Princip izračunavanja je jasan - broj povoljnih ishoda delimo sa ukupnim brojem mogućih ishoda. U našem primeru, događaj se može ostvariti na 3 načina, dok je ukupan broj ishoda 6. Količnik 3/6 = 0.5 nam govori da postoji 50% šanse da kockica pokaže paran broj.
Uslovna verovatnoća predstavlja verovatnoću da će se jedan događaj desiti pod uslovom da se drugi događaj već dogodio. Razmotrimo sledeću situaciju: bacili smo kockicu i znamo da je pao paran broj. Kolika je verovatnoća da je taj broj baš 2?
Princip izračunavanja uslovne verovatnoće je prirodan: prebrojavamo povoljne ishode i delimo ih ukupnim brojem mogućih ishoda, ali sada uzimamo u obzir samo one ishode koji zadovoljavaju postavljeni uslov. U našem primeru, paran broj na kockici može biti 2, 4 ili 6 (ukupno 3 mogućnosti), a broj 2 se pojavljuje samo jednom. Stoga je verovatnoća da smo dobili 2, pod uslovom da znamo da je broj paran, jednaka 1/3.
U matematičkoj notaciji, ako događaj dobijanja parnog broja označimo sa \(B\), a događaj dobijanja broja 2 sa \(A\), uslovnu verovatnoću zapisujemo kao \(P(A|B)\). Ovde \(B\) predstavlja dodatnu informaciju koja modifikuje našu procenu verovatnoće događaja \(A\).
Uporedimo ovo sa neuslovljenom verovatnoćom. Verovatnoća da pri proizvoljnom bacanju kockice dobijemo 2 je \(P(A) = 1/6\). Verovatnoća dobijanja parnog broja je \(P(B) = 1/2\). Međutim, verovatnoća dobijanja 2 pod uslovom da je broj paran iznosi \(P(A|B) = 1/3\). Razlika između \(P(A)\) i \(P(A|B)\) ilustruje kako dodatna informacija o događaju \(B\) menja našu procenu verovatnoće događaja \(A\).
Pogledajmo kako ovo funkcioniše na praktičnom primeru. U CSV datoteci kandidati.csv imamo podatke o glasanju građana jednog grada u Srbiji na izborima za gradonačelnika. U uzorku od 400 građana, pratili smo glasove za tri kandidata: Anu, Bogdana i Veljka. Za svakog ispitanika smo takođe zabeležili da li je mlad (do 35 godina) ili ne. Učitajmo ove podatke u R i analizirajmo ih.
podaci <- read.csv("https://sm.atomasevic.com/data/kandidati.csv")
head(podaci) kandidat mladi
1 Ana 0
2 Bogdan 1
3 Bogdan 0
4 Ana 0
5 Ana 0
6 Ana 0Varijabla podaci$kandidat je tekstualnog tipa, dok je podaci$mladi numerička binarna (ili dummy) varijabla.
Da bismo razumeli ove podatke kroz prizmu teorije verovatnoće, posmatrajmo čin glasanja kao eksperiment. Kada građanin pristupi glasačkom mestu i bira jednog od kandidata, to za nas predstavlja realizaciju slučajnog eksperimenta. Mogući ishodi su tri kandidata, a ostvareni događaj je konkretan izbor glasača.
Prvo ćemo analizirati raspodelu glasova među kandidatima koristeći funkciju table().
table(podaci$kandidat)
Ana Bogdan Veljko
228 152 20 Pogledajmo dobijenu tabelu frekvencija. Ana je osvojila najveći broj glasova u uzorku, zatim sledi Bogdan, dok je Veljko dobio najmanje glasova. Koristeći funkciju nrow(podaci) možemo dobiti ukupan broj opservacija u uzorku. Izračunajmo sada verovatnoću da je nasumično izabrani građanin glasao za Anu.
\[ P(Ana) = \frac{f(Ana)}{n} \]
Ovde je \(P(Ana)\) verovatnoća da je nasumično izabrani građanin glasao za Anu, gde \(f(Ana)\) predstavlja broj građana koji su glasali za Anu, a \(n\) označava ukupan broj građana u uzorku.
n <- nrow(podaci)
tabela <- table(podaci$kandidat)
f_ana <- tabela["Ana"]
p_ana <- f_ana / n
p_anakandidat
Ana
0.57 Verovatnoća da će nasumično izabrani ispitanik glasati za Anu iznosi 0.57, odnosno 57%. Postoji jednostavniji način da dobijemo iste rezultate za sve kandidate. Umesto kreiranja tabele frekvencija, možemo koristiti funkciju prop.table() koja direktno računa proporcije. U ovom kontekstu, te proporcije predstavljaju verovatnoće glasanja za svakog kandidata.
prop.table(table(podaci$kandidat))prop.table() prima tabelu frekvencija i računa proporcije. Ovo je prvi put da imamo da je input funkcije ouput prethodne funkcije. R će prvo napraviti tabelu frekvencija, a zatim ubaciti tu tabelu kao input za prop.table() funckiju.
Ana Bogdan Veljko
0.57 0.38 0.05 Ova funkcija nam daje proporcije za sva tri kandidata. Kada ih saberemo, dobijamo 1, što je logično jer je suma verovatnoća svih mogućih ishoda eksperimenta jednaka 1.
Razmotrimo sada uslovnu verovatnoću u praksi. Pretpostavimo da želimo izračunati verovatnoću da je nasumično izabrani građanin glasao za Anu, uz uslov da znamo da je osoba mlada. Preciznije, ako je poznato da je reč o mladom biraču, kolika je verovatnoća da je glas dat Ani?
Ovo možemo izračunati na dva načina. Prvi pristup je da izdvojimo podskup mladih ispitanika iz uzorka, a zatim izračunamo proporciju glasova za Anu u tom podskupu.
podaci_mladi <- podaci[podaci$mladi == 1, ]
prop.table(table(podaci_mladi$kandidat))podaci_mladi koji sadrži samo one ispitanike iz uzorka koji su mladi.
Ana Bogdan Veljko
0.34375 0.28125 0.37500 Za izračunavanje verovatnoće, potrebno je prebrojati različite načine na koje se događaj može ostvariti. Pogledajmo kako se ovo prebrojavanje izvodi u R-u.
Da bismo ilustrovali ovaj koncept, prebrojićemo mlade ispitanike u našem uzorku. Počnimo od varijable podaci$mladi.
head(podaci$mladi)[1] 0 1 0 0 0 0Kada govorimo o mladim ispitanicima koji su označeni indikatorom podaci$mladi == 1, važno je obratiti pažnju na dvostruki znak jednakosti ==. U R-u je ovo operator za testiranje jednakosti. Kada napišemo podaci$mladi == 1, zapravo tražimo od R-a da za svaku opservaciju u skupu podataka proveri da li je vrednost varijable mladi jednaka 1. Pogledajmo šta dobijamo kada ovo izvršimo:
podaci$mladi == 1== na vektor podaci$mladi, R proverava svaki element vektora i vraća logički vektor iste dužine. Elementi ovog vektora su TRUE za mlade ispitanike i FALSE za ostale.
[1] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[13] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
[25] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[37] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE
[49] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[61] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[73] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
[85] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
[97] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
[109] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[121] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[133] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[145] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE
[157] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
[169] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[181] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[193] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[205] FALSE FALSE TRUE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[217] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[229] FALSE TRUE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE
[241] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[253] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[265] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE
[277] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[289] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE
[301] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
[313] FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE
[325] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[337] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE
[349] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[361] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[373] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[385] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[397] FALSE FALSE FALSE FALSEPodaci otkrivaju zanimljiv obrazac. Dok u celom uzorku Ana ima podršku od 57%, među mladim biračima ta podrška pada na 34%. Istovremeno, Veljkova podrška pokazuje dramatičan rast - sa 5% u celom uzorku na 37.5% među mladima. Ovo je jasan indikator da Veljko uživa značajno veću popularnost među mladom populacijom nego što to opšti podaci sugerišu.
Da bismo bolje razumeli odnos između starosne grupe i izbornih preferencija, kreiraćemo unakrsnu tabelu (kros-tabulaciju) za varijable mladi i kandidat. Ova tabela će nam precizno prikazati kako se glasovi mladih i starijih građana raspodeljuju među kandidatima - Anom, Bogdanom i Veljkom.
table(podaci$mladi, podaci$kandidat)mladi i kandidat. Funkcija table() ovde prima dva argumenta, što nam omogućava da analiziramo odnos između dve varijable. Za razliku od jednostavne tabele frekvencija koja nastaje sa jednim argumentom, dva argumenta generišu matricu koja prikazuje presek ovih varijabli.
Ana Bogdan Veljko
0 217 143 8
1 11 9 12Ova tabela nam daje važan uvid u podatke: u našem uzorku imamo 32 mlada ispitanika. Jasno možemo videti raspodelu glasova starijih ispitanika (prvi red tabele) i mladih (drugi red). Međutim, sama tabela ne govori direktno o verovatnoćama. Da bismo izračunali te verovatnoće, potrebno je da konvertujemo frekvencije iz tabele u proporcije.
prop.table(table(podaci$mladi, podaci$kandidat), margin = 1)prop.table(). Parametar margin=1 određuje da li se proporcije računaju po redovima (1) ili kolonama (2).
Ana Bogdan Veljko
0 0.58967391 0.38858696 0.02173913
1 0.34375000 0.28125000 0.37500000Ovaj pristup daje iste rezultate kao prethodni, ali uz značajnu prednost - omogućava nam direktno poređenje verovatnoća za svakog kandidata u zavisnosti od starosne grupe. Podaci otkrivaju jasan obrazac: Ana dominira među starijim ispitanicima, dok je situacija među mladima bitno drugačija. U mlađoj populaciji, Ana i Veljko imaju gotovo identičnu podršku, što ukazuje na fundamentalno drugačiju strukturu glasačkih preferencija u ovoj demografskoj grupi.
Nejednakosti koje smo uočili u prethodnom primeru pokazuju da nisu svi ishodi jednako verovatni. Veća je verovatnoća da će mlad birač glasati za Veljka nego stariji. Kada smo analizirali bacanje kockice, svaki ishod je bio jednako verovatan - verovatnoća dobijanja broja 1 jednaka je verovatnoći dobijanja brojeva 2, 3, 4, 5 ili 6.
Statistički opis jednakosti ili nejednakosti verovatnoća ishoda eksperimenta predstavljen je distribucijom verovatnoće. Distribucije verovatnoće možemo opisati ili matematičkom formulom koja definiše pravilnost pojavljivanja ishoda, ili grafički, linijama koje prikazuju verovatnoće svakog mogućeg ishoda.
Najjednostavnija distribucija verovatnoće je diskretna uniformna distribucija, koju smo već sreli pri analizi bacanja kockice. Možemo je zapisati kao:
\[ P(x) = \frac{1}{k} \]
gde je \(x\) događaj, a \(k\) broj mogućih ishoda.
Distribucije verovatnoće delimo na diskretne i neprekidne (kontinuirane). Ova podela proističe iz prirode ishoda koje opisuju. Diskretne distribucije opisuju ishode koji se mogu prebrojati, dok neprekidne opisuju ishode koji se ne mogu prebrojati. Razjasnimo ovo kroz primere.
Ključno pitanje koje pomaže u razlikovanju ove dve vrste distribucija je: „Koliko mogućih ishoda postoji između vrednosti a i b?“
Uzmimo bacanje kockice kao primer diskretne distribucije. Između 3 i 6 imamo tačno 2 moguća ishoda (4 i 5). Ili ako posmatramo starost ljudi u godinama, između 25 i 35 godina možemo precizno nabrojati sve vrednosti (26, 27, …, 34).
Nasuprot tome, merenje visine ljudi predstavlja primer neprekidne distribucije. Između 160 cm i 180 cm teoretski postoji beskonačno mnogo mogućih vrednosti. Čak i u najmanjem intervalu, recimo između 160 cm i 160,0000001 cm, matematički gledano postoji beskonačno mnogo mogućih vrednosti.
Hajde da nacrtamo grafikon ove distribucije. Prvo ćemo da definišemo ishode i njihove verovatnoće.
k <- 6
x <- 1:k
y <- rep(1/k, k)Sada možemo grafički predstaviti ove rezultate iscrtavajući vertikalnu liniju iznad svakog ishoda.
par(family = "Jost")
plot(x, y,
type = "h", lwd = 3, col = "#5C88DAFF",
main = "Diskretna uniformna distribucija",
xlab = "Ishod", ylab = "Verovatnoća")
points(x, y, pch = 16, col = "#CC0C00FF", cex = 1.5)x i y predstavljaju vektore ishoda (x-osa) i njihovih verovatnoća (y-osa)
type = "h" kreira vertikalne linije. Parametri lwd=3 i col="#5C88DAFF" definišu debljinu i boju linija
main, xlab i ylab definišu naslov grafikona i oznake osa
points() dodaje tačke na već iscrtani grafikon
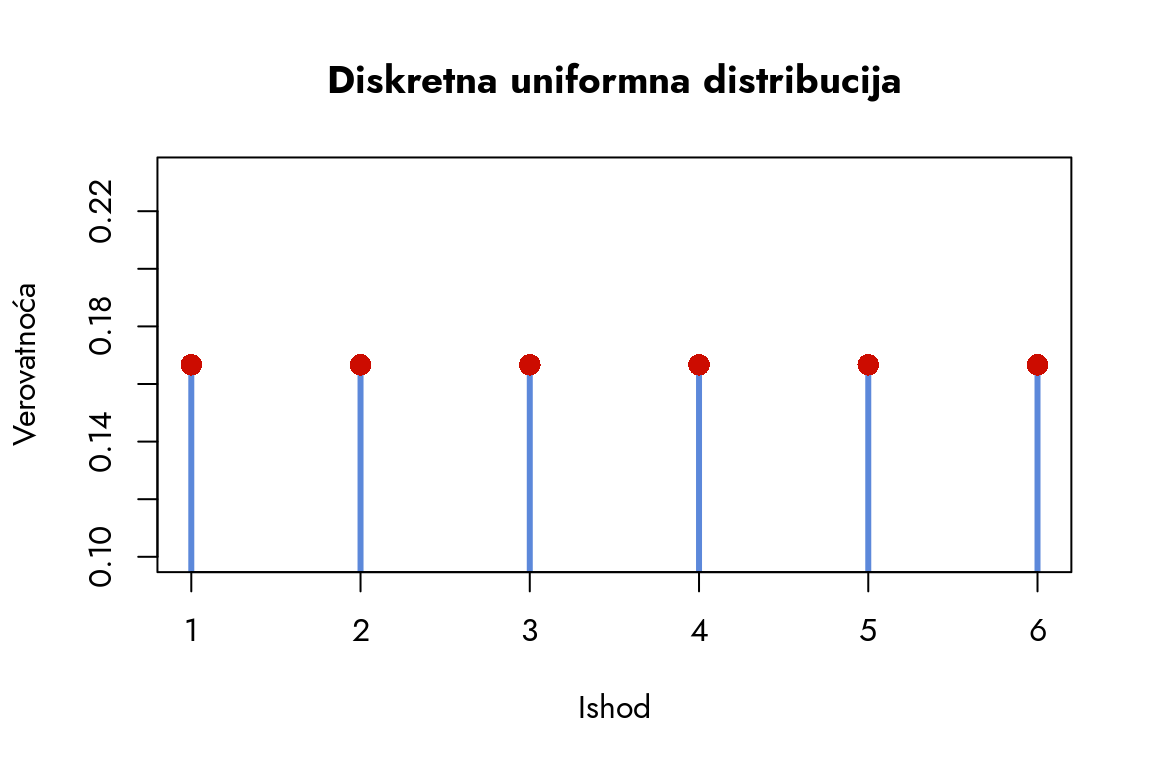
Grafikon precizno prikazuje jednaku raspodelu verovatnoće za sve ishode, gde verovatnoća svakog ishoda iznosi približno 0.17. Kroz ovakav vizuelni prikaz jasno se uočava osnovna karakteristika diskretne uniformne distribucije - svi ishodi imaju identičnu verovatnoću pojavljivanja.
Razmotrimo sada složeniji scenario koji uključuje bacanje dve kockice. Posebno nas zanima distribucija zbira brojeva koji se pojavljuju na kockicama.
Matematički gledano, prva kockica (A) i druga kockica (B) svaka imaju po 6 mogućih ishoda. Ukupan broj mogućih kombinacija je njihov proizvod: \(6 \times 6 = 36\). Ova naizgled jednostavna situacija otvara put ka dubljoj analizi distribucije verovatnoća.
A <- 1:6
B <- 1:6
X <- expand.grid(A, B)
colnames(X) <- c("A", "B")
X$suma <- X$A + X$B
head(X)A i B koji predstavljaju ishode prve i druge kockice.
expand.grid() kreira sve moguce kombinacije vrednosti iz A i B.
suma koja predstavlja zbir brojeva na kockicama u svim kombinacijama.
A B suma
1 1 1 2
2 2 1 3
3 3 1 4
4 4 1 5
5 5 1 6
6 6 1 7U prvih nekoliko redova vidimo kombinacije i njihove zbirove, ali da bismo sagledali celokupnu sliku svih mogućih zbirova i njihovih frekvencija, koristimo funkciju table().
table(X$suma)
2 3 4 5 6 7 8 9 10 11 12
1 2 3 4 5 6 5 4 3 2 1 Ova tabela prikazuje distribuciju koju intuitivno razumemo kroz iskustvo sa bacanjem kockica. Zbir 12 je redak događaj koji zahteva specifičnu kombinaciju bacanja, dok je zbir 2 jednako redak na suprotnom kraju distribucije. Zbir 1 je nemoguć događaj, kao i svaki zbir veći od 12. Zbirovi između 5 i 9 se javljaju najčešće, što je direktna posledica većeg broja mogućih kombinacija koje vode do ovih ishoda.
Da bismo kvantifikovali ove verovatnoće preciznije, koristimo funkciju prop.table().
prop.table(table(X$suma))prop.table() prima tabelu frekvencija i računa proporcije.
2 3 4 5 6 7 8
0.02777778 0.05555556 0.08333333 0.11111111 0.13888889 0.16666667 0.13888889
9 10 11 12
0.11111111 0.08333333 0.05555556 0.02777778 Prikažimo ovo grafički koristeći sličan pristup kao kod uniformne distribucije.
par(family = "Jost")
plot(table(X$suma),
type = "h", lwd = 3, col = "#5C88DAFF",
main = "Distribucija zbirova dve kockice",
xlab = "Zbir", ylab = "Frekvencija")table(X$suma) daje nam tabelu frekvencija za zbirove.
type = "h" govori R-u da nacrta histogram. lwd=3 i col="#5C88DAFF" su opcije koje određuju debljinu i boju linija.
main i xlab i ylab su opcije koje određuju naslov grafikona i imena osa.

Ovaj grafikon ilustruje distribuciju verovatnoća za različite zbirove. Najviši vrh grafikona predstavlja najčešći ishod, dok najniže tačke ukazuju na najmanje verovatne rezultate. Pred nama je primer diskretne distribucije verovatnoće koja odstupa od uniformne, s obzirom na to da se verovatnoće pojedinih zbirova međusobno razlikuju.
Razmotrimo sada kako bi izgledala distribucija kada bacamo četiri kockice. Ovaj primer će nam pomoći da bolje razumemo kako se distribucija menja sa povećanjem broja slučajnih događaja.
A <- 1:6
B <- 1:6
C <- 1:6
D <- 1:6
X <- expand.grid(A, B, C, D)
colnames(X) <- c("A", "B", "C", "D")
X$suma <- X$A + X$B + X$C + X$D
par(family = "Jost")
plot(table(X$suma),
type = "h", lwd = 3, col = "#5C88DAFF",
main = "Distribucija zbirova 4 kockice",
xlab = "Zbir", ylab = "Frekvencija")A, B, C i D koji predstavljaju ishode prve, druge, treće i četvrte kockice.
suma koja predstavlja zbir brojeva na kockicama u svim kombinacijama.
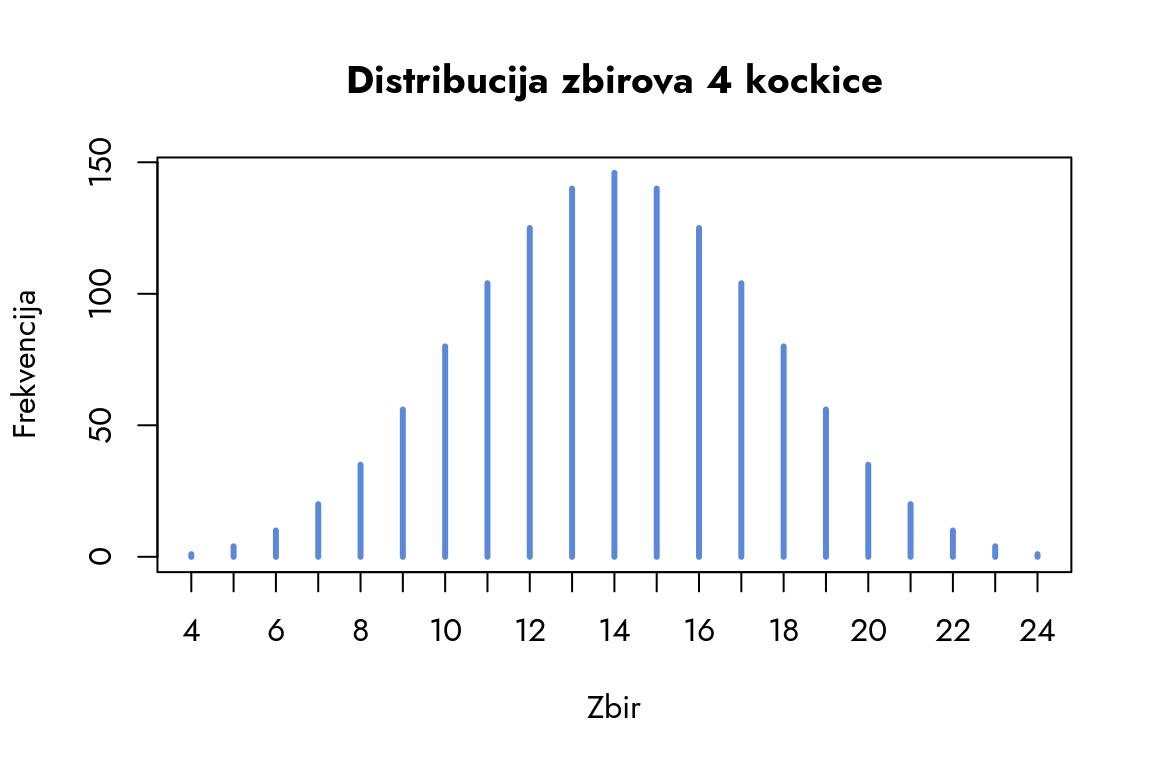
Grafikon koji dobijamo pokazuje značajno drugačiju distribuciju, ali zadržava prepoznatljiv oblik. Dobijanje zbira 24 predstavlja izuzetno redak događaj, dok se najveća verovatnoća koncentrisuje oko zbirova između 11 i 17.
Ova dva grafikona otkrivaju fundamentalni obrazac u teoriji verovatnoće. Ishodi sa najvećom verovatnoćom grupišu se oko centralne vrednosti distribucije, odnosno oko proseka. Sa udaljavanjem od proseka, bilo prema većim ili manjim vrednostima, frekvencija i verovatnoća dosledno opadaju. Ekstremne vrednosti, one najudaljenije od proseka, pojavljuju se sa najmanjom verovatnoćom.
Ovo nas dovodi do ključnog pitanja: koja matematička pravilnost opisuje ovo opadanje verovatnoće? Koliki je tačno odnos između verovatnoće dobijanja zbira 8 i zbira 10? Ovakve pravilnosti u distribuciji verovatnoća opisuju se pomoću složenijih matematičkih modela, među kojima je normalna distribucija najvažnija i najšire primenjena. U sledećem poglavlju detaljno ćemo istražiti osobine i primene ove distribucije.
Koristeći R, izračunajte sledeće uslovne verovatnoće:
Interpretirajte dobijene rezultate i objasnite šta nam oni govore o odnosu između glasačkih preferencija i starosnih grupa.
Izračunajmo sledeće uslovne verovatnoće koristeći R:
Ove verovatnoće će nam dati jasniju sliku o starosnoj strukturi biračkog tela svakog kandidata. Uporedite dobijene rezultate i razmotrite šta nam oni govore o odnosu između kandidata i demografske strukture njihovih birača.
Kreirajte grafikon distribucije verovatnoća za scenario bacanja 10 kockica i analizirajte raspodelu njihovih zbirova.
Analizirajmo podatke primanja.csv. Potrebno je izračunati verovatnoću da mesečna primanja ispitanika iz uzorka padaju u opseg između 1200 i 1300 evra. Ovo je praktičan primer za razumevanje diskretnih distribucija verovatnoće u realnom kontekstu.
Koristeći podatke primanja.csv, odredite verovatnoću da ispitanik ima mesečna primanja koja odstupaju za više od 3 standardne devijacije iznad aritmetičke sredine (odnosno, Z-skor veći od 3).
Ovaj zadatak nam pomaže da razumemo kako identifikovati statističke ekstreme u realnim podacima.