R (R Core Team, 2024) je veoma koristan programski jezik primenljiv u brojnim oblastima. Ovaj svestrani alat služi za razvoj aplikacija, analizu podataka, statističke proračune, vizualizaciju informacija, mašinsko učenje, obradu slika i teksta, kao i za web razvoj. Ključna prednost R-a je njegova dostupnost - besplatan je i otvorenog koda, što znači da ga svako može preuzeti, koristiti, modifikovati i deliti bez ograničenja.
U okviru našeg kursa, R ćemo koristiti na tri osnovna načina:
za izračunavanje vrednosti,
za kreiranje i čuvanje objekata,
za primenu funkcija.
Praktično gledano, naš rad će se sastojati od zadavanja preciznih instrukcija R-u za obradu i analizu podataka. Pisanje R koda je proces kreiranja niza jasnih uputstava koje R treba da izvrši. Kada se povežu na smislen način, ove instrukcije predstavljaju logičku implementaciju statističkih metoda koje želimo da primenimo.
NoteOsnovni R
Mnogi udžbenici statistike koji koriste R oslanjaju se na tidyverse i ggplot2 softverske pakete. Ovi paketi su izuzetno korisni i značajno pojednostavljuju rad sa podacima. Ipak, u ovom udžbeniku fokusiraćemo se isključivo na osnovni (eng. base) R, bez dodatnih paketa. Kroz primenu elementarnih funkcija za obradu i vizualizaciju podataka, savladaćemo sve statističke metode koje su predmet našeg kursa.
Postoji i dodatna prednost ovog pristupa - sintaksa i logika osnovnog R-a je pristupačnija i sličnija drugim programskim jezicima poput Python-a. Kada savladate osnovni R, prelazak na druge programske jezike biće znatno jednostavniji.
R je napredan alat, ali njegov osnovni princip rada nije mnogo drugačiji od digitalnog kalkulatora. Ključna razlika je u tome što R može da obradi značajno veće količine podataka i izvrši kompleksnije operacije, što ga čini izuzetno efikasnim alatom za statističku analizu.
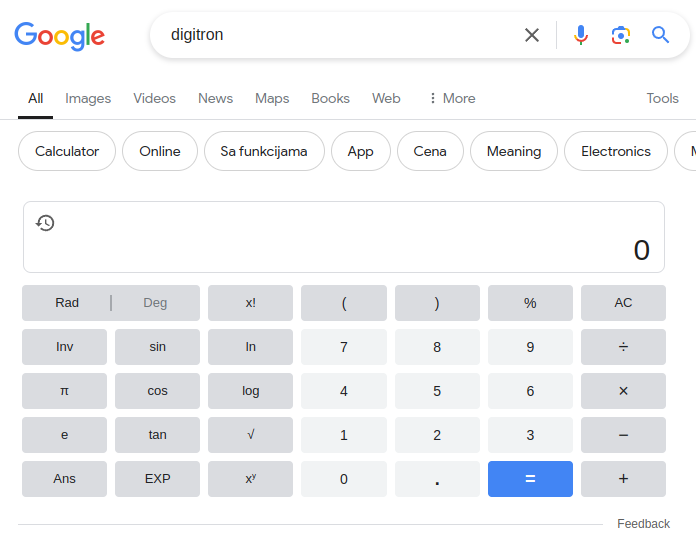
Slika 3.1: Prikaz Google kalkulatora
Na slici vidimo da interfejs osnovnog Google kalkulatora sadrži:
tastere za unos brojeva,
tastere za izbor aritmetičkih operacija,
tastere za izbor matematičkih funkcija.
Rad sa kalkulatorom prati jasan obrazac - unosimo brojeve, biramo operaciju i dobijamo rezultat. Na primer, za izračunavanje kvadratnog korena broja 25, unosimo 25, pritiskamo taster za kvadratni koren i očitavamo rezultat.
R funkcioniše po sličnom principu, ali sa znatno većim mogućnostima. U R-u prvo pripremamo podatke - bilo direktnim unosom ili učitavanjem iz eksternih izvora poput Excel tabela. Nakon toga, primenjujemo odgovarajuće funkcije za obradu tih podataka.
Evo konkretnog primera: recimo da znamo da je varijansa neke varijable 198 i želimo izračunati standardnu devijaciju. U nastavku je prikazan kod koji to radi. Tokom čitanja udžbenika često ćemo analizirati kodove koji se koriste za različite proračune i vizualizacije.
Da biste videli kod i prateća objašnjenja, pritisnite taster Prikaži kod. U kodu ćete primetiti oznake 1, 2 i 3 sa desne strane - one vode do detaljnih objašnjenja svake linije ili grupe linija koda. Tu je takođe i opcija za kopiranje celokupnog koda.
Unosimo vrednost 198. Operator <- dodeljuje ovu vrednost objektu varijansa. Sam izgled ovog operatora ilustruje proces - poput strelice koja „ubacuje“ vrednost u objekat.
2
Izračunavamo standardnu devijaciju. Funkcija sqrt() računa kvadratni koren prosleđene vrednosti. Matematički, to je direktna implementacija formule koju smo ranije videli.
3
Prikazujemo rezultat. R nam daje vrednost čim navedemo ime objekta ili funkcije - jednostavno i efikasno.
[1] 14.07125
Nakon izvršavanja, R prikazuje vrednost standardne devijacije od približno 14.07.
R ima dve značajne prednosti u odnosu na klasični kalkulator:
Transparentnost procesa: Svaki korak je precizno dokumentovan. Imena varijabli jasno označavaju svrhu naših postupaka, što čini ceo proces razumljivijim od običnog računanja.
Strukturiranost: Analiza je podeljena na jasne, logične korake. Možemo pratiti kako se svaki korak nadovezuje na prethodni, gradeći celovitu sliku analize.
Ovaj primer pokazuje tri osnovna načina korišćenja R-a. Prvo, dodeljujemo vrednost objektu varijansa. U R-u, objekti deluju kao virtuelni „kontejneri“ za podatke i vrednosti. Konkretno, objekat varijansa prima vrednost 198.
Opšta sintaksa za dodelu vrednosti objektu u R-u je:
ime_objekta <- vrednost
Objekat u R-u može sadržati različite tipove podataka - od pojedinačnih vrednosti do nizova, drugih objekata ili rezultata funkcija. Dobar primer je linija koda standardna_devijacija <- sqrt(varijansa). Ovde koristimo funkciju sqrt za računanje kvadratnog korena, što nas dovodi do važnog koncepta - funkcija.
Funkcije su osnovni gradivni blokovi R-a. To su predefinisane celine koda koje efikasno izvršavaju specifične operacije. Na primer, funkcija sqrt je dizajnirana sa jednim ciljem - da izračuna kvadratni koren broja. Kada radimo u R-u, funkcije pozivamo koristeći sledeću sintaksu:
ime_funkcije(argument1, argument2, ...)
Argumenti funkcije predstavljaju ulazne podatke koje funkcija koristi za izvršavanje operacija. To su informacije koje funkcija zahteva kako bi obavila svoj zadatak. Na primer, funkcija sqrt() koristi objekat varijansa kao argument za izračunavanje kvadratnog korena. Rezultat funkcije - vrednost koja nastaje nakon obrade ulaznih podataka - nazivamo izlazom. U našem primeru, taj izlaz (rezultat funkcije sqrt()) čuvamo u objektu standardna_devijacija.
Kada niz ovakvih naredbi sačuvamo kao tekstualni fajl, dobijamo ono što u programiranju zovemo skriptom. Skripta je, u suštini, skup preciznih instrukcija koje računar izvršava jednu za drugom. Iako se u ovom udžbeniku nećemo detaljno baviti konceptom skripti, koristićemo ih kao efikasan način za čuvanje i ponovno korišćenje koda. Ovakav pristup nam omogućava da lako ponavljamo analize ili ih prilagođavamo novim podacima.
Svaki korak analize u ovom udžbeniku praćen je R kodom koji možete pregledati. Jedini izuzetak predstavljaju složeni grafikoni, za čije iscrtavanje je potrebno više desetina linija koda. Taj kod namerno izostavljamo kako bismo održali fokus na suštini gradiva. Sve vizualizacije u ovom udžbeniku kreirane su u osnovnom R-u, koristeći isključivo standardne funkcije za iscrtavanje grafičkih elemenata.
Ovakav pristup nam omogućava da jasno vidimo vezu između teorije i prakse, bez nepotrebnih tehničkih detalja koji bi mogli da zamagle suštinu. Ideja je jednostavna - najpre razumemo koncept, zatim vidimo kako se on implementira u kodu, i na kraju posmatramo rezultat. Ovaj metodički pristup pokazao se jako efikasnim u savladavanju statističkih koncepata.
3.2 Kako se koristi R?
R je programski jezik koji najbolje funkcioniše u interaktivnom režimu. Ovo znači da možete unositi naredbe direktno u konzolu i odmah dobiti rezultate - kao da vodite dijalog sa računarom. Ovakav pristup čini R izuzetno praktičnim za statističku analizu i eksperimentisanje sa podacima.
Interakciju sa R-om možete isprobati direktno u ovom udžbeniku kroz sekcije koje sadrže interaktivni kod. U njima ćete naći R konzolu gde možete unositi naredbe i trenutno videti rezultate.
Najbolje ćemo pokazati kako R funkcioniše tako što ćemo zajedno da osvežimo znanje o osnovnim konceptima deskriptivne statistike.
3.3 Deskriptivna statistika
U našem istraživanju učestvovalo je \(n=350\) ispitanika. Od svakog smo prikupili podatak o njihovim mesečnim primanjima. Varijabla \(X\) predstavlja te odgovore, tako da vrednosti \(x_1, x_2, \ldots x_n\) čine naš skup podataka.
Prva mera koju ćemo izračunati je aritmetička sredina uzorka\(\overline{X}\) - jednostavno rečeno, prosek primanja svih ispitanika. Formula za njeno izračunavanje izgleda ovako:
Da vidimo kako ovu formulu možemo implementirati u R-u. Naši podaci su smešteni u CSV fajl koji možemo preuzeti sa interneta.
NoteCSV
CSV format je jedan od najčešće korišćenih formata za skladištenje podataka. Naziv CSV potiče od engleskog izraza Comma Separated Values, što označava vrednosti razdvojene zarezima. Zamislite jednostavnu tabelu gde su podaci u kolonama razdvojeni zarezima umesto vertikalnih linija. Evo primera kako bi izgledali osnovni podaci o starosti i polu ispitanika u CSV formatu:
starost,pol
25,m
30,z
22,m
Format CSV je elegantan u svojoj jednostavnosti - pristupačan je i za računare i za ljude. U suštini, to je običan tekstualni fajl koji organizuje podatke u redove, gde su vrednosti razdvojene zarezima. Uzmimo kao primer fajl sa dve varijable - starost i pol. Svaki red predstavlja jednog ispitanika, a njihovi podaci su razdvojeni zarezima. U našem primeru imamo tri ispitanika: prvi ima 25 godina i muškog je pola, drugi 30 godina i ženskog pola, a treći 22 godine i muškog pola. Ova struktura nam omogućava intuitivno razumevanje podataka, što je ključno za efikasnu analizu.
CSV fajl koji ćemo koristiti u narednom primeru izgleda ovako:
"primanja"
340
1069
522
...
Ovaj fajl je jednostavan, ali efikasan. Sadrži jednu varijablu - primanja. Svaki red nakon zaglavlja predstavlja podatak o primanjima jednog ispitanika. Struktura je precizna i jasna: sa 350 ispitanika, fajl ima tačno 351 red (prvi red sadrži naziv varijable). Ova elegantna organizacija podataka nam omogućava direktnu i preciznu analizu primanja naših ispitanika.
Učitavanje podataka. Na početku definišemo putanju do fajla - ovo je URL adresa koja vodi do našeg fajla sa podacima. Ovaj pristup nam omogućava jednostavan pristup podacima bez lokalne kopije.
2
Podatke učitavamo u objekat podaci. Funkcija read.csv je elegantno rešenje za učitavanje podataka iz CSV fajla. Ona efikasno obrađuje podatke koristeći putanju definisanu u prethodnom koraku.
3
Primenjujemo funkciju head koja prikazuje prvih nekoliko redova učitanih podataka. Ova funkcija je izuzetno praktična kada radimo sa velikim skupovima podataka - umesto pregledanja cele tabele, dobijamo brz uvid u strukturu i sadržaj podataka. To nam omogućava da odmah procenimo da li su podaci ispravno učitani i spremni za analizu.
primanja
1 340
2 1069
3 522
4 356
5 827
6 340
NoteSkupovi ili tabele podataka
U našem radu često ćemo koristiti izraze skup podataka i tabela podataka. Iako deluju slično, između njih postoji suptilna razlika. U R-u podaci se čuvaju u objektima koje nazivamo data frame, što na srpski prevodimo kao tabela podataka. S druge strane, skup podataka (eng. data set) odnosi se na sam fajl sa podacima koji može biti sačuvan na različitim lokacijama - serveru, repozitorijumu, hard disku ili drugde.
Oba pojma dele istu osnovnu strukturu i organizaciju podataka. Zamislite ih kao tablicu sa dve dimenzije: opservacije i varijable. Opservacije predstavljaju redove, a varijable kolone u toj tablici.
Kada govorimo o jednoj opservaciji, mislimo na sve informacije koje smo prikupili o jednom konkretnom „subjektu“ našeg istraživanja. To može biti osoba (ispitanik), ali i nešto sasvim drugo - firma, region, pa čak i država. Jedinica opservacije nam govori šta tačno svaka opservacija predstavlja u našem skupu podataka.
Opservacije označavamo rednim brojevima - prva opservacija nalazi se u prvom redu tabele podataka, druga u drugom, i tako redom. Ovakva struktura nam omogućava precizno praćenje i analizu podataka za svakog pojedinačnog subjekta našeg istraživanja.
Prikaži kod
podaci[1, ]
1
Prikaz prve opservacije iz tabele podataka.
[1] 340
Kolone skupa podataka nazivamo varijablama. Svaka varijabla predstavlja jednu karakteristiku koja se menja između opservacija. Uzmimo za primer varijablu „pol“ - ona beleži ovu karakteristiku za svakog ispitanika u našem skupu. Termin „promenljiva“ nije slučajan - koristi se upravo zato što vrednosti variraju od ispitanika do ispitanika. Razmislite na trenutak: kada bi svi ispitanici bili istog pola, ta varijabla ne bi nosila nikakvu korisnu informaciju.
Ova struktura podataka je temelj našeg rada u R-u, i važno je da je dobro razumemo pre nego što krenemo dalje.
Kada R učita CSV fajl, kreira tabelu podataka (eng. data frame). Naša tabela sadrži jednu kolonu - primanja, koja beleži mesečna primanja svakog ispitanika. Svaki red predstavlja podatak o jednom ispitaniku.
Sa podacima spremnim za analizu, možemo izračunati aritmetičku sredinu uzorka. Pogledajmo matematičku formulaciju:
\[\overline{X} = \frac{\sum_{i=1}^n x_i}{n}\]
Za direktnu primenu ove formule u R-u, potrebna su nam dva osnovna elementa:
Zbir svih vrednosti u uzorku: sum(podaci$primanja)
Broj ispitanika: nrow(podaci)
Ova dva elementa čine srž našeg izračunavanja. Pogledajmo kako ih implementiramo u R-u.
Prikaži kod
AS <-sum(podaci$primanja) /nrow(podaci)round(AS,2)
1
Proračun aritmetičke sredine. Funkcija sum izračunava zbir svih vrednosti u vektoru, dok nrow određuje broj redova u tabeli.
2
Zaokruživanje rezultata na dve decimale korišćenjem funkcije round.
[1] 799.8
Izvršavanjem ovog koda dobijamo aritmetičku sredinu uzorka od približno 800. Vredan je pomena i elegantniji pristup - funkcija mean(). Isprobajte je i uporedite rezultate. Iako je mean() računski efikasnija, naš prvobitni pristup nam omogućava direktan uvid u logiku izračunavanja.
Nastavimo sa dubljom analizom. Pored srednje vrednosti, ključno je razumeti i raspršenost podataka u uzorku. Zamislite dva uzorka koja dele istu aritmetičku sredinu, ali imaju različitu raspršenost - takva situacija nam otkriva suštinske karakteristike podataka koje proučavamo.
Ilustrujmo ovo na konkretnom primeru. Pogledajmo ispitanika broj 42, čija su primanja \(X_{42} = 340\). Možemo precizno izmeriti koliko njegova primanja odstupaju od proseka uzorka. Ovaj proračun nam otkriva individualnu varijaciju unutar našeg skupa podataka.
Izdvajamo primanja ispitanika pod rednim brojem 42.
2
Računamo razliku između njegovih primanja i proseka uzorka.
3
Prikazujemo rezultat.
[1] -459.8
Analiza pokazuje da su primanja ovog ispitanika za približno 460 evra niža od proseka uzorka. Razmotrimo ovo u širem kontekstu. Uzmimo za primer skandinavsku zemlju gde prosečna primanja iznose 5460 evra. Tamo bi ispitanik sa primanjima od 5000 evra takođe bio 460 evra ispod proseka. Međutim, isto odstupanje od proseka ima sasvim različito značenje u društvu gde je prosek 5460 evra, u odnosu na društvo gde je prosek 800 evra.
Ova situacija nam jasno pokazuje zašto ne možemo posmatrati odstupanja od proseka izolovano. Potrebno je da odredimo prosečno odstupanje od proseka, koje će nam poslužiti kao referentna tačka za analizu svih pojedinačnih odstupanja, uključujući i našeg ispitanika broj 42.
Usled jedinstvenih karakteristika aritmetičke sredine, najprecizniji način merenja prosečnog odstupanja je kroz kvadriranje individualnih odstupanja. Ovim pristupom dolazimo do varijanse, čiji kvadratni koren predstavlja standardnu devijaciju.
Tokom kursa primetićete važnu konvenciju - vrednosti koje izračunavamo za uzorak, poput aritmetičke sredine, varijanse, standardne devijacije i relativne frekvencije, označavamo latiničnim slovima (\(\overline{X},s^2,s,p\)). Ove statistike uzorka nisu samo brojevi - one nam služe kao prozor u nepoznate parametre cele populacije. R nam omogućava da izračunamo ove vrednosti i iskoristimo ih za razumevanje šire slike.
Kada govorimo o populaciji, koristimo mala grčka slova (\(\mu, \sigma^2,\sigma, \pi\)) za označavanje parametara. Ovi parametri predstavljaju stvarne vrednosti karakteristika populacije koje ne možemo direktno izmeriti. Ipak, možemo ih proceniti koristeći podatke iz našeg uzorka. Upravo ovaj proces - procena parametara populacije na osnovu uzorka - čini srž statističkog zaključivanja. To je kao da sastavljamo slagalicu cele slike koristeći samo jedan njen deo.
Podelićemo proces izračunavanja varijanse na četiri jasna koraka:
Prvo računamo individualna odstupanja od proseka: R podaci$primanja - AS. Ovo nam pokazuje koliko svaka vrednost odstupa od središta distribucije.
Zatim kvadriramo ta odstupanja: R (podaci$primanja - AS)^2. Ovaj korak je elegantan - eliminišemo negativne vrednosti i naglašavamo veća odstupanja.
Potom sabiramo sve kvadrirane vrednosti: R sum((podaci$primanja - AS)^2). Ova suma nam daje ukupnu meru raspršenosti.
Na kraju, delimo zbir sa n-1: R sum((podaci$primanja - AS)^2) / (nrow(podaci) - 1). Ovim dobijamo prosečno kvadrirano odstupanje.
Svaki korak vodi ka dubljem razumevanju strukture naših podataka. Ova postupnost nije slučajna - ona nam omogućava da vidimo kako se matematički koncepti pretvaraju u konkretne mere varijabilnosti.
NoteVektori u R-u
Pogledajmo detaljnije komandu podaci$primanja - AS. Šta tačno tražimo od R-a? Želimo da za svakog ispitanika izračunamo odstupanje njegovih primanja od proseka uzorka. Objekat AS je aritmetička sredina uzorka - jedan broj. Nasuprot tome, podaci$primanja je vektor, struktura koja sadrži niz brojeva (u našem slučaju, primanja svih ispitanika).
Kada od vektora oduzmemo skalar (pojedinačnu vrednost), R primenjuje tu operaciju na svaki element vektora. Rezultat je nov vektor koji sadrži individualna odstupanja svakog elementa od oduzete vrednosti. Ova operacija nam efikasno pokazuje kako su primanja raspoređena u odnosu na prosek.
Hajde da ove korake pretočimo u R kod. Pogledajte kako to izgleda:
Funkcija var() elegantno računa varijansu - ona obrađuje vektor i vraća nam tačnu vrednost.
2
Funkcija round zaokružuje rezultat na dve decimale, čineći broj preglednijim za analizu.
[1] 158021.6
Šta nam govori dobijeni rezultat? Varijansa, iako matematički precizna, nije intuitivna za tumačenje. Razlog je jednostavan - nije izražena u istim jedinicama kao naši izvorni podaci. Srećom, postoji elegantan način da ovo prevaziđemo. Transformisaćemo je u meru koja je prirodnija za razumevanje - standardnu devijaciju.
Postupak je jednostavan: izračunavamo kvadratni koren varijanse. Ovaj naizgled jednostavan matematički korak nam otvara put ka jasnijem razumevanju raspršenosti podataka. Standardna devijacija, za razliku od varijanse, izražena je u istim jedinicama kao i originalni podaci, što nam omogućava direktniju interpretaciju rezultata.
Izračunavanje standardne devijacije koristeći funkciju sqrt koja računa kvadratni koren argumenta.
2
Zaokruživanje rezultata na dve decimale.
[1] 397.52
Dobijeni rezultat od približno 400 evra predstavlja standardnu devijaciju uzorka. Šta nam ova vrednost govori? U osnovi, ona ukazuje da primanja tipičnog ispitanika variraju oko 400 evra u odnosu na prosečnu vrednost. Ova mera raspršenosti daje nam precizniju sliku o tome kako su primanja distribuirana oko prosečne vrednosti od 800 evra.
Standardna devijacija nam omogućava sledeći logičan korak - standardizaciju odstupanja od proseka. Kroz ovaj postupak pretvaramo pojedinačna odstupanja iz originalnih jedinica mere u univerzalne, uporedive vrednosti. Tako dobijamo mogućnost da tumačimo odstupanja nezavisno od proseka uzorka ili korišćenih mernih jedinica.
Razmotrimo konkretan primer: ispitanik 42 ima primanja koja su 460 evra ispod proseka. Umesto da ovu razliku posmatramo u apsolutnim vrednostima, možemo je standardizovati i izraziti kroz broj standardnih devijacija. Rezultat ovog postupka nazivamo Z-skor.
\[
Z = \frac{X - \overline{X}}{s}
\]
U R-u to izgleda ovako:
Prikaži kod
Z <- (ispitanik - AS) / standardna_devijacijaround(Z,2)
1
Izračunavanje Z-skora prati preciznu formulu.
[1] -1.16
Dobijeni rezultat od -1,16 pokazuje da se ispitanik nalazi 1,16 standardnih devijacija ispod proseka. Ovaj broj ima značenje samo u okviru šire statističke distribucije. Detaljniju interpretaciju Z-skorova i elegantno pravilo tri sigme obradićemo u poglavlju o normalnoj distribuciji.
Prirodan sledeći korak je standardizacija celokupnog uzorka. Kroz ovu transformaciju stvaramo novu varijablu koja ima aritmetičku sredinu 0 i standardnu devijaciju 1.
Da bismo potvrdili ovu transformaciju, kreiraćemo varijablu Zi koja sadrži standardizovane vrednosti primanja. Ova vektorska operacija transformiše svaku vrednost varijable primanja u standardizovanu vrednost. Proces je jednostavan ali moćan - od svake vrednosti oduzimamo prosečnu vrednost i delimo rezultat standardnom devijacijom. Time dobijamo novi vektor Zi sa standardizovanim vrednostima koje nam omogućavaju direktno poređenje različitih opservacija.
Prikaži kod
Zi <- (podaci$primanja - AS) / standardna_devijacijahead(Zi)
1
Kreiramo vektor standardizovanih vrednosti primanja.
2
Prikazujemo nekoliko prvih vrednosti radi ilustracije.
Prirodan sledeći korak je provera ispravnosti naše standardizacije. Teorijski očekujemo da standardizovane vrednosti imaju aritmetičku sredinu 0 i standardnu devijaciju 1. Proverimo da li je to zaista tako. Za jasan i pregledan prikaz rezultata koristićemo funkciju cat.
Z-skorovi nam daju moćan alat za interpretaciju vrednosti, nezavisno od jedinice mere ili apsolutne veličine. Njihova ključna prednost je mogućnost direktnog poređenja vrednosti iz različitih uzoraka. Bilo da analiziramo visinu ispitanika ili primanja u različitim valutama, Z-skorovi nam omogućavaju precizno određivanje relativne pozicije svake vrednosti. Vrednost Z-skora blizu 0 ukazuje na malu udaljenost od proseka, dok pozitivan Z-skor jasno označava vrednost iznad proseka uzorka.
Ovim završavamo uvod u R i osnovne koncepte deskriptivne statistike. Do sada smo se fokusirali na kvantitativne varijable, ali u narednim poglavljima detaljno obrađujemo i kvalitativne varijable, kao i njihovu praktičnu primenu u R-u. Pre nego što nastavite dalje, preporučujem da ponovite ključne koncepte deskriptivne statistike sažete u 10 tačaka iznad. Za efikasno utvrđivanje znanja, najbolje je da rešite zadatke na kraju poglavlja - oni će vam pomoći da izgradite čvrste temelje za dalji rad u R-u.
NoteTipovi varijabli
U prethodnom poglavlju upoznali ste se sa konceptom mernih skala (nominalna, ordinalna, intervalna i racio). Merna skala je koncept koji se prvenstveno odnosi na dizajn istraživanja i psihometrijske karakteristike mernog instrumenta. Za naše potrebe, napravićemo jednostavnu ali efikasnu podelu na numeričke i tekstualne varijable.
Ova podela je istovremeno intuitivna i praktična - tekstualne varijable sadrže vrednosti zapisane kao niz alfanumeričkih znakova (slova „A“-„Ž“, cifre „0“-„9“, kao i specijalne znakove poput „!“, „#“, „?“), dok numeričke varijable sadrže vrednosti koje R direktno prepoznaje i obrađuje kao brojeve.
Logično pitanje koje se nameće je: „Zar nisu i brojevi alfanumerički znakovi?“ Suština je u načinu na koji R interpretira te vrednosti. Na primer, 999 R tumači kao broj s kojim može da vrši matematičke operacije, dok "999" tretira kao običan tekst. Sve što se nalazi između navodnika (") R interpretira kao tekst, bez obzira na sadržaj.
U okviru obe kategorije varijabli postoji posebna i izuzetno korisna podgrupa - binarne varijable. One su specifične jer imaju tačno dve moguće vrednosti.
Kod tekstualnih varijabli, klasičan primer je varijabla pol sa dve opcije: "Muški" ili "Ženski".
Kada govorimo o numeričkim varijablama, posebnu pažnju zaslužuju binarne ili „dummy“ varijable. Ove indikatorske varijable tipično uzimaju vrednosti 0 ili 1. Uzmimo za primer varijablu zaposlen: vrednost 1 označava zaposlenu osobu, dok 0 označava nezaposlenu. Ovakva varijabla elegantno ukazuje na prisustvo ili odsustvo određene karakteristike kod svakog ispitanika u studiji.
Savremena istraživanja često zahtevaju širi spektar opcija, ali to prevazilazi okvire našeg trenutnog razmatranja.
3.4 Pregled deskriptivne statistike
Suština deskriptivne statistike, koja je ključna za razumevanje ostatka knjige, može se svesti na 10 osnovnih tačaka:
Analiza pojedinačne varijable obuhvata dve ključne komponente: centralnu tendenciju i varijabilitet - odnosno kako se vrednosti grupišu oko centralne mere.
Tri fundamentalne centralne mere koje koristimo su modus, medijana i aritmetička sredina.
Modus predstavlja vrednost koja se najčešće pojavljuje u skupu podataka.
Medijana je vrednost koja deli uređeni niz podataka na dva jednaka dela - elegantno rešenje za pronalaženje sredine skupa.
Aritmetička sredina je računski izvedena mera centralne tendencije i predstavlja prvi centralni moment varijable - preciznije, prosek svih vrednosti.
Za merenje varijabiliteta koristimo dva moćna alata: varijansu i standardnu devijaciju.
Varijansa, kao drugi centralni moment varijable, predstavlja prosečno kvadrirano odstupanje od aritmetičke sredine.
Standardna devijacija, kao kvadratni koren varijanse, daje nam intuitivniju meru raspršenosti u originalnim jedinicama mere.
Standardizacija transformiše originalnu varijablu X u Z-skor kroz formulu \(Z_i = \frac{X_i - \overline{X}}{s}\). Na primer, u situaciji gde je prosek ispita 10 poena sa standardnom devijacijom 3, student koji je osvojio 16 poena ima Z-skor 2, što znači da je njegov rezultat dve standardne devijacije iznad proseka.
Standardizovana varijabla ima dve karakteristične osobine: aritmetičku sredinu 0 i standardnu devijaciju 1, što matematički zapisujemo kao \(\overline{Z}=0\), \(s_Z=1\).
Ovi koncepti predstavljaju temelj za razumevanje složenijih statističkih analiza koje slede.
3.5 Interaktivni kod
Nakon što pročitate ovo poglavlje, preporučujem da sistematično prođete kroz kod koji smo obradili u primerima.
Ekspementišite sa kodom - menjajte vrednosti, dodajte nove redove i istražite različite funkcije. Kroz direktnu interakciju sa kodom najbrže ćete savladati gradivo i steći samopouzdanje potrebno za rešavanje zadataka.
Linije koda koje počinju sa # su komentari - običan tekst koji pojašnjava funkcionalnost koda. Slobodno dodajte svoje komentare kako biste označili izmene ili pojasnili logiku iza vaših eksperimenata.
Za povratak na početnu verziju koda, koristite prvo dugme sa desne strane („Vrati originalni kod“). Drugo dugme vam omogućava kopiranje koda.
U desnom navigacionom meniju, ispod sadržaja poglavlja, naći ćete opciju „Pogledaj istoriju naredbi“. Tu možete pregledati sve izvršene naredbe i preuzeti ih kao R skriptu - koristan alat za dokumentovanje vašeg rada.
3.6 Zadaci
CautionZadatak 1
Uporedite ispitanike 42 i 100 iz našeg skupa podataka. Analizirajte kako se njihova primanja odnose prema proseku uzorka. Fokusirajte se na dve ključne dimenzije - intenzitet i smer odstupanja od prosečne vrednosti. Na ovaj način ćete direktno primeniti koncepte deskriptivne statistike koje smo obradili.
CautionZadatak 2
Razmotrimo ponovo primer skandinavske zemlje. U toj zemlji prosečna plata iznosi 5460 evra, sa standardnom devijacijom od 870 evra. Naš zadatak je da odredimo poziciju osobe čija primanja iznose 5000 evra u odnosu na prosek - preciznije, koliko standardnih devijacija je ta osoba udaljena od proseka? Nakon toga, uporedite relativnu poziciju ovog hipotetičkog ispitanika sa pozicijama ispitanika 42 i 100 iz našeg uzorka. Obratite pažnju na način na koji se svako od njih pozicionira u odnosu na prosek svog uzorka i razmislite šta nam to govori o distribuciji primanja u ove dve različite populacije.
CautionZadatak 3 *
Koristeći isključivo funkcije koje smo obradili u ovom poglavlju, dokažite da je rezultat izraza podaci$primanja - AS zaista vektor. Za rešenje razmotrite osnovne karakteristike vektora i načine na koje ih možemo proveriti programski.
CautionZadatak 4 **
Pronađite u našem uzorku ispitanika čija je pozicija u odnosu na prosek najbliža poziciji hipotetičkog ispitanika iz skandinavske zemlje (iz Zadatka 2).
Za pretragu vektora podaci$primanja i izdvajanje rednih brojeva opservacija koje se nalaze između vrednosti \(a\) i \(b\), možete koristiti sledeću funkciju:
Prikaži kod
which(podaci$primanja > a & podaci$primanja < b)
Iskoristite ovu funkciju da rešite zadatak.
Konzola za rešavanje zadataka
Ukoliko želite da rešite zadatke, konzola ispod je na vašem raspolaganju. U njoj možete pisati i izvršavati R kod, te odmah videti rezultate. Ovo je odličan način da testirate svoje razumevanje materije kroz praktičan rad.
R Core Team. (2024). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. https://www.R-project.org/