Analiza prethodnog poglavlja otkriva da smo malo pažnje posvetili veličini uzorka. Ona se pojavila samo u formuli za standardnu grešku, gde smo videli da se greška smanjuje s povećanjem uzorka.
Z-test iz prethodnog poglavlja propustio je da uvaži ključnu činjenicu: neizvesnost u donošenju zaključaka se smanjuje s rastom uzorka. Statističko zaključivanje je u suštini borba s neizvesnošću koja proizilazi iz ograničenih informacija o populaciji dobijenih iz uzorka. Jednostavno rečeno: veći uzorak znači manju neizvesnost zaključaka, dok mali uzorak donosi veliku neizvesnost.
Kada govorimo o neizvesnosti, mislimo na verovatnoću grešaka tipa I ili tipa II. Kod malog uzorka, verovatnoća greške raste. Kod velikog uzorka, ona opada. Ovo je fundamentalna istina statističkog zaključivanja: veličina uzorka direktno određuje pouzdanost naših zaključaka.
NoteVeliki i mali uzorci
U statistici postoji važan kriterijum za razlikovanje malih i velikih uzoraka. Uzorci s više od 30 jedinica smatraju se velikim. Jednostavnije rečeno - u društvenim istraživanjima, dovoljno je 30 ispitanika za „veliki“ uzorak. Sve manje od toga smatra se malim uzorkom.
Broj 30 može delovati mali. Često čujemo o istraživanjima sa 300, 600 ili čak 1000 ispitanika. Zašto onda baš 30? Razlog je matematički elegantan.
Ova granica nije proizvoljna, već direktno proizlazi iz ponašanja standardne greške aritmetičke sredine. Hajde da istražimo zašto je broj 30 poseban.
Zamislite praktičan primer - merimo prosečna primanja ljudi. Pretpostavimo da standardna devijacija primanja u populaciji iznosi 100 evra. Koristeći formulu za standardnu grešku (Formula 6.1), možemo ispitati šta se dešava kada menjamo veličinu uzorka od 2 do 100 ispitanika.
Prikaži kod
n <-seq(2, 100, by =1)se <-100/sqrt(n)round(head(se),2)
1
Pravimo sekvencu brojeva od 2 do 100.
2
Računamo standardnu grešku za svaku veličinu uzorka.
3
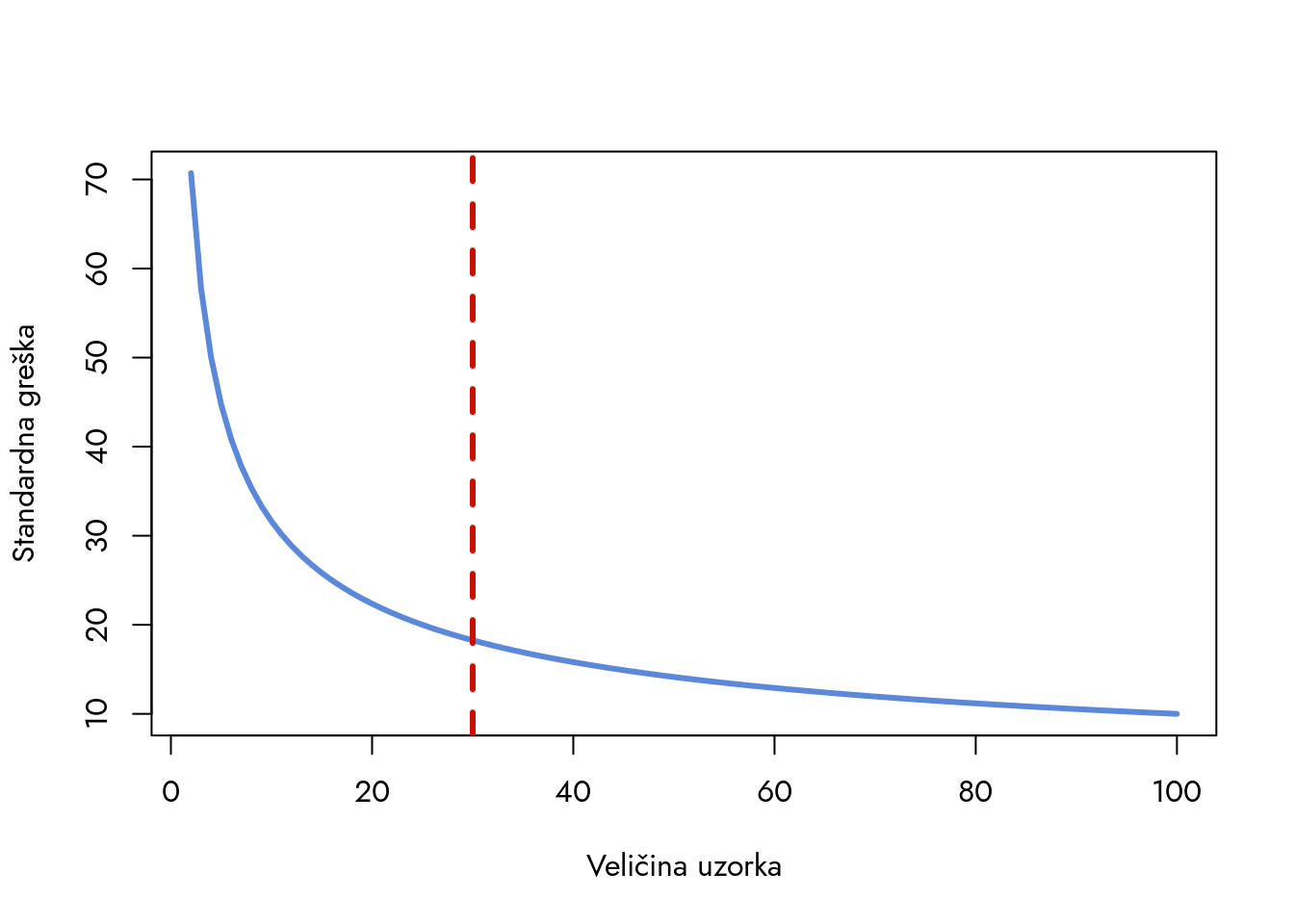
Prikazujemo prvih nekoliko vrednosti standardne greške. Vidite da standardna greška opada kako uzorak raste. Za 2 ispitanika, ona je oko 70 EUR, ali brzo pada na 40 EUR za 5 ispitanika. Dramatično smanjenje, ali šta se dešava dalje? Istražimo.
[1] 70.71 57.74 50.00 44.72 40.82 37.80
Prikaži kod
par(family ="Jost")plot(n, se, type ="l", col ="#5C88DAFF", lwd =3, xlab ="Veličina uzorka", ylab ="Standardna greška")abline(v =30, col ="#CC0C00FF", lty =2, lwd=3)
1
Crtamo grafikon koji pokazuje kako se standardna greška menja s veličinom uzorka.
2
Dodajemo crvenu liniju na 30 ispitanika.
Slika 8.1: Standardna greška za različite veličine uzorka
Grafik otkriva jasan obrazac. U opsegu od 2 do 30 ispitanika, kriva standardne greške pokazuje oštar pad. Nakon 30 ispitanika, kriva postaje gotovo horizontalna. Ovo je matematički razlog zašto broj 30 predstavlja granicu između malih i velikih uzoraka - nakon ove tačke, standardna greška opada toliko postepeno da dodatni ispitanici donose minimalno poboljšanje preciznosti. Zbog toga uzorke veće od 30 jedinica klasifikujemo kao velike.
Da bismo preciznije razumeli ovu dinamiku, uporedimo standardnu grešku za 10, 30 i 90 ispitanika:
Prikaži kod
cat("Standardna greška za 10 ispitanika:", se[9], "\n")cat("Standardna greška za 30 ispitanika:", se[29], "\n")cat("Standardna greška za 90 ispitanika:", se[89], "\n")
Standardna greška za 10 ispitanika: 31.62278
Standardna greška za 30 ispitanika: 18.25742
Standardna greška za 90 ispitanika: 10.54093
Pogledajmo kako se greška menja s povećanjem uzorka. Kada povećamo uzorak s 10 na 30 ispitanika (samo 20 više), greška se smanjuje za oko 13 EUR. Značajan napredak. Ali šta se dešava kad nastavimo? Kada dodamo još tri puta više ispitanika (s 30 na 90), greška opada za samo 8 EUR. Iz ovoga izvlačimo važan zaključak: nakon određene tačke, dodavanje novih ispitanika donosi sve manje poboljšanja. To je glavni razlog zašto uzorke preko 30 jedinica smatramo „velikim“ - potrebno je mnogo dodatnih ispitanika za relativno malo smanjenje greške. Kod malih uzoraka situacija je drugačija - svaki novi ispitanik značajno doprinosi smanjenju greške.
Z-test koji smo ranije koristili nije obuhvatio ovu dinamiku. On primenjuje standardizovani normalni raspored sa fiksnim parametrima - aritmetičkom sredinom 0 i standardnom devijacijom 1. Ne postoji direktna veza između veličine uzorka i neizvesnosti zaključaka, osim kroz Z-statistiku koja zavisi od veličine uzorka. Drugim rečima, rezultat testa se menja sa veličinom uzorka, ali distribucija za zaključivanje ostaje nepromenjena. Ovo je fundamentalna razlika: Z-test ne prilagođava parametre veličini uzorka, što ga čini nepreciznim za male uzorke.
Kao odgovor na ovaj problem, razvijena je modifikacija normalne distribucije koja uzima u obzir veličinu uzorka. Reč je o Studentovoj t-distribuciji koja predstavlja osnovu za t-test. Ova distribucija nam omogućava da preciznije modelujemo neizvesnost kada radimo s malim uzorcima.
8.2 Studentova t-distribucija
T-distribucija je adaptivna verzija normalne distribucije koja se prilagođava veličini uzorka. S porastom veličine uzorka, t-distribucija konvergira ka normalnoj distribuciji. Kada radimo s velikim uzorcima, ona postaje gotovo identična normalnoj - simetrična je i ima tanke repove. Međutim, kod malih uzoraka t-distribucija pokazuje svoje prave karakteristike: postaje šira i ima teže repove, što precizno odražava veću neizvesnost koja proizilazi iz ograničenog broja podataka.
TipStudent i Ginis pivo
Ime „Studentova t-distribucija“ ima zanimljivu pozadinu. Sve je počelo sa Vilijamom Sejmourom Gosetom, koji je 1908. godine objavio značajan rad pod pseudonimom „Student“ (Student, 1908).
Goset je radio kao hemičar u pivari „Guinness“, gde se bavio unapređenjem kvaliteta piva. Kompanija je u to vreme primenjivala naučne metode za optimizaciju proizvodnje. Gosetov zadatak je bio analiza hemijskih svojstava ječma, ključnog sastojka u proizvodnji. Zbog ekonomskih ograničenja, radio je sa izuzetno malim uzorcima - testirao je samo 3-4 džaka ječma koji su predstavljali celokupnu proizvodnju.
Kroz rad je uočio fundamentalni problem - Z-test nije davao pouzdane rezultate na ovako malim uzorcima. Test jednostavno nije mogao da obuhvati velike varijacije koje su prirodne kada radite sa malim brojem opservacija. Motivisan ovim izazovom, Goset je razvio novu distribuciju koja je eksplicitno uzimala u obzir veličinu uzorka. Rezultat njegovog rada je t-distribucija, koja je postala osnova za t-test.
Zašto je izabrao pseudonim „Student“? Najverovatnije zato što Guinness nije dozvoljavao svojim zaposlenima da objavljuju naučne radove pod pravim imenom. Možda su se plašili da će konkurencija iskoristiti njihove inovacije. Ili su želeli da prikriju činjenicu da rade sa malim uzorcima. Bez obzira na pravi razlog, pseudonim je postao neraskidivo povezan sa jednom od najvažnijih distribucija u statistici.
Da bismo bolje razumeli ovo ponašanje, hajde da ga vizualizujemo.
Definišemo gustinu t-distribucije funkcijom dt(). Argument df je broj stepeni slobode.
4
Crtamo gustinu normalne distribucije.
5
Crtamo gustinu t-distribucije za tri različita broja stepeni slobode.
6
Dodajemo legendu.
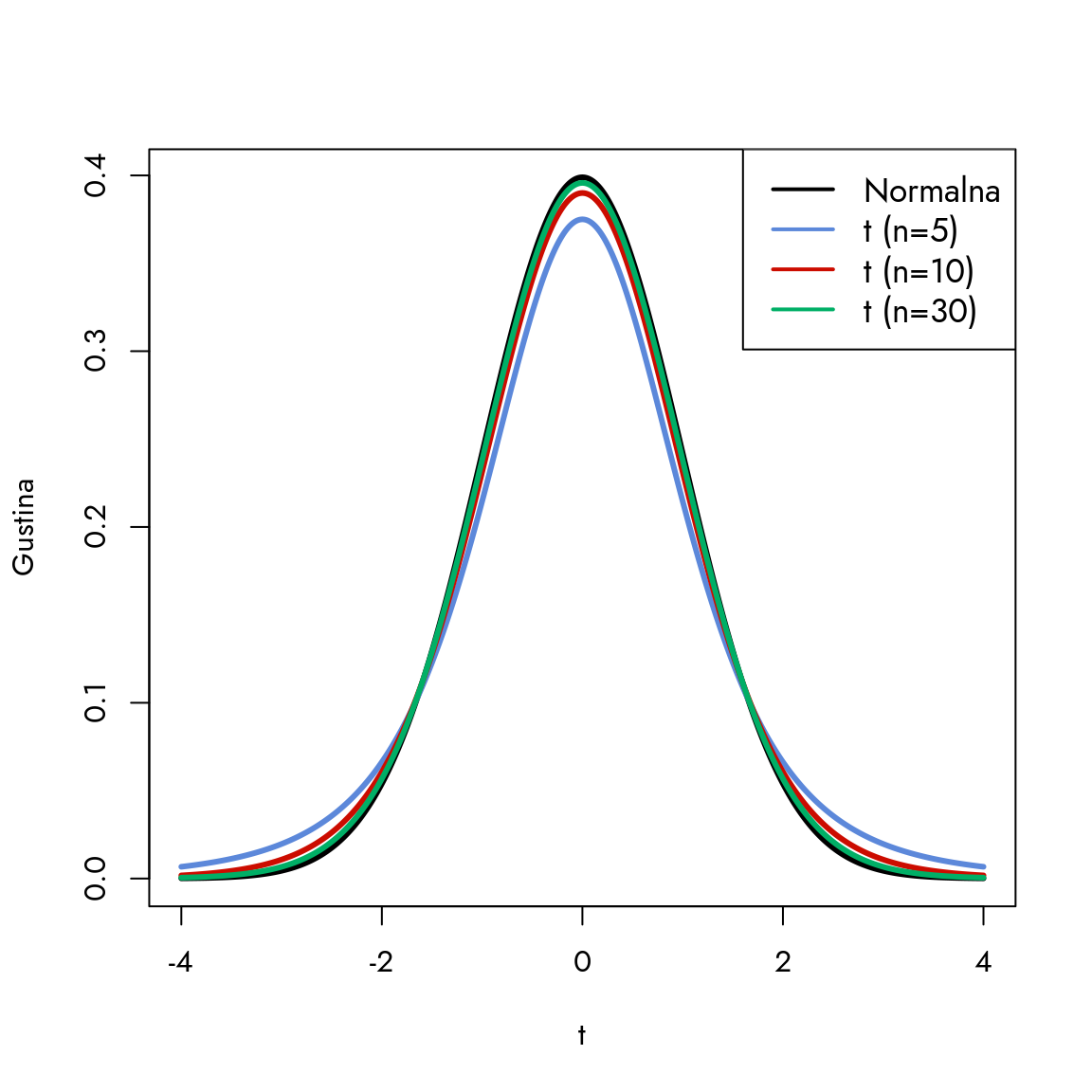
Slika 8.2: Studentova t-distribucija za različite veličine uzorka
Na grafikonu vidimo ponašanje t-distribucije u poređenju s normalnom distribucijom. Kada imamo mali broj stepeni slobode, t-distribucija pokazuje šire „repove“ i veću varijabilnost - to je ilustrovano plavom linijom. Ona je niža od ostalih, što ukazuje na manju koncentraciju verovatnoće oko centra, uz „deblje“ repove koji odražavaju veću neizvesnost u oceni i povećanu verovatnoću ekstremnih vrednosti. T-distribucija zadržava simetriju oko nule, baš kao i standardizovana normalna distribucija.
Kako raste broj stepeni slobode, t-distribucija konvergira ka normalnoj. Zelena i crna linija se praktično preklapaju, pokazujući da već pri \(n=30\) t-distribucija postaje gotovo identična standardizovanoj normalnoj distribuciji. Ipak, nastavljamo da je koristimo jer ona precizno modeluje neizvesnost koja proizilazi iz veličine uzorka - ključna prednost kada radimo s uzorcima različitih veličina.
Pre nego što nastavimo dalje, neophodno je uvesti novi koncept - stepene slobode. Iako ih je intuitivno teško razumeti, oni predstavljaju fundamentalan pojam za t-distribuciju i mnoge druge statističke koncepte. Pogledajmo detaljnije šta oni predstavljaju.
8.2.1 Stepeni slobode
Pre formalne definicije, razmotrite jednostavan primer koji će vam pomoći da intuitivno shvatite koncept. Zamislimo: cimerka se vraća iz kupovine s dve kese. Kaže da je potrošila 1000 dinara i traži da pogodite koliko je platila sadržaj svake kese. Šta možete proceniti? U suštini, samo vrednost jedne kese, jer je vrednost druge automatski određena prvom procenom. Ako procenite da prva kesa vredi 700 dinara, druga mora vredeti 300. Nemate „slobodu“ da nezavisno procenite vrednost druge - ona je već definisana. U ovom slučaju imate jedan stepen slobode.
Sada zamislimo da je došla s tri kese, a ukupna kupovina je i dalje 1000 dinara. Šta se menja? Sada možete proceniti vrednost prve (recimo 500 dinara) i druge kese (300 dinara), a vrednost treće je automatski određena (200 dinara). U ovom slučaju imate dva stepena slobode.
Generalizujući ovaj princip, stepeni slobode su jednaki broju kesa umanjenom za 1. S jednim stepenom slobode, situacija je deterministička - kada znate vrednost jedne kese, znate i vrednost druge. S više stepeni slobode, otvara se prostor za varijacije u procenama vrednosti pojedinačnih kesa.
U formalnom smislu, stepeni slobode predstavljaju broj nezavisnih vrednosti koje mogu slobodno varirati u izračunavanju neke statistike. U primeru s kesama, ako imate \(n\) kesa i znate ukupnu cenu, imate \(n-1\) stepeni slobode. Zašto? Zato što kada odredite cene \(n-1\) kesa, cena poslednje je fiksirana kako bi se održala ukupna suma. U statistici, stepeni slobode se označavaju kao \(df\) (degrees of freedom) i izražavaju formulom:
\[
df = n - k
\]
gde je \(n\) broj opservacija (vrednosti u uzorku), a \(k\) broj ograničenja ili procenjenih parametara. U primeru s tri kese čija je ukupna vrednost ograničena na 1000 dinara, imamo jedno ograničenje (\(k=1\)), što nam daje dva stepena slobode (\(df=3-1=2\)).
A kako stepeni slobode funkcionišu u t-distribuciji? Ovo je ključno pitanje za razumevanje. Hajde da pogledamo konkretan primer koji će nam pokazati kako t-test koristi stepene slobode za testiranje hipoteza o aritmetičkoj sredini. Na ovaj način ćemo videti direktnu primenu teorije koju smo obradili.
8.3 t-test za aritmetičku sredinu
Započnimo s praktičnim primerom t-testa, koji strukturalno nalikuje z-testu.
Posmatrajmo uzorak od 10 studenata kojima smo merili prosečan broj sati utrošenih na pripremu ispita. Pretpostavka je da student može spremiti ispit za minimalno 30 sati. Formulišemo nultu hipotezu:
\[
H_0: \mu \geq 30
\]
Alternativna hipoteza je:
\[
H_1: \mu < 30
\]
U jednom ispitnom roku, profesor je od 10 studenata saznao da je njihov prosek učenja bio 25 sati uz standardnu devijaciju od 5 sati. Pretvorimo to u R kod.
Prikaži kod
n <-10as <-25sd <-5
1
Broj studenata.
2
Prosečan broj sati učenja u uzorku.
3
Standardna devijacija uzorka.
Za razliku od Z-testa gde smo koristili pretpostavljenu vrednost standardne devijacije populacije, kod t-testa koristimo standardnu devijaciju uzorka. Razlog je jednostavan - kada ne koristimo stvarnu vrednost populacijske standardne devijacije (\(\sigma\)), uvodimo dodatnu neizvesnost jer se greška zasniva na proceni standardne devijacije iz uzorka. Međutim, ovu dodatnu neizvesnost obuhvatamo kroz t-distribuciju koja se prilagođava veličini uzorka.
Nakon toga, izračunavamo standardnu grešku i t-statistiku. T-statistika je standardizovana mera koja pokazuje koliko je aritmetička sredina uzorka udaljena od vrednosti iz nulte hipoteze, izražena u jedinicama standardne greške.
Standardizujemo razliku između uzorka i nulte hipoteze, dobijamo t-statistiku.
Standardna greška: 1.58
t-statistika: -3.16
Na ovako malom uzorku, greška procene prosečnog vremena učenja je 1.58. Apsolutna razlika između uzorka i nulte hipoteze iznosi 5 sati (studenti prosečno uče 25 sati, dok je pretpostavka 30). Standardizovanjem te razlike dobijamo t-statistiku -3.16.
Hajde da vizualizujemo ovu t-statistiku na t-distribuciji. Za to nam je prvo potrebno da izračunamo stepene slobode t-distribucije. Stepeni slobode predstavljaju razliku između broja opservacija i broja procenjenih parametara. U našem slučaju imamo 10 opservacija (10 studenata) i jedan procenjeni parametar - aritmetičku sredinu uzorka (jedan ukupan zbir), što nam daje 9 stepeni slobode. Zašto je aritmetička sredina ekvivalentna zbiru? Jednostavno - kada kažete da je 10 studenata učilo prosečno 25 sati, to je identično tvrdnji da je ukupan broj sati učenja za 10 studenata 250. Prema tome, radimo sa 9 stepeni slobode.
Prikaži kod
par(family ="Jost")df <- n -1x <-seq(-4, 4, 0.01)y <-dt(x, df)plot(x, y, type ="l", col ="#5C88DAFF", lwd =3, xlab ="t-skor", ylab ="Gustina", xaxt ="n")axis(1, at=seq(-4, 4, 1), labels=seq(-4, 4, 1))abline(v = t, col ="#CC0C00FF", lwd =3, lty =1)text(-2.3, 0.15, "t = -3.16 ", col ="red", cex =1.2, font =2)
1
Računamo stepene slobode t-distribucije.
2
Definišemo opseg x vrednosti.
3
Računamo gustinu t-distribucije.
4
Crtamo gustinu t-distribucije.
5
Dodajemo oznake na x osu i crvenu liniju za t-skor.
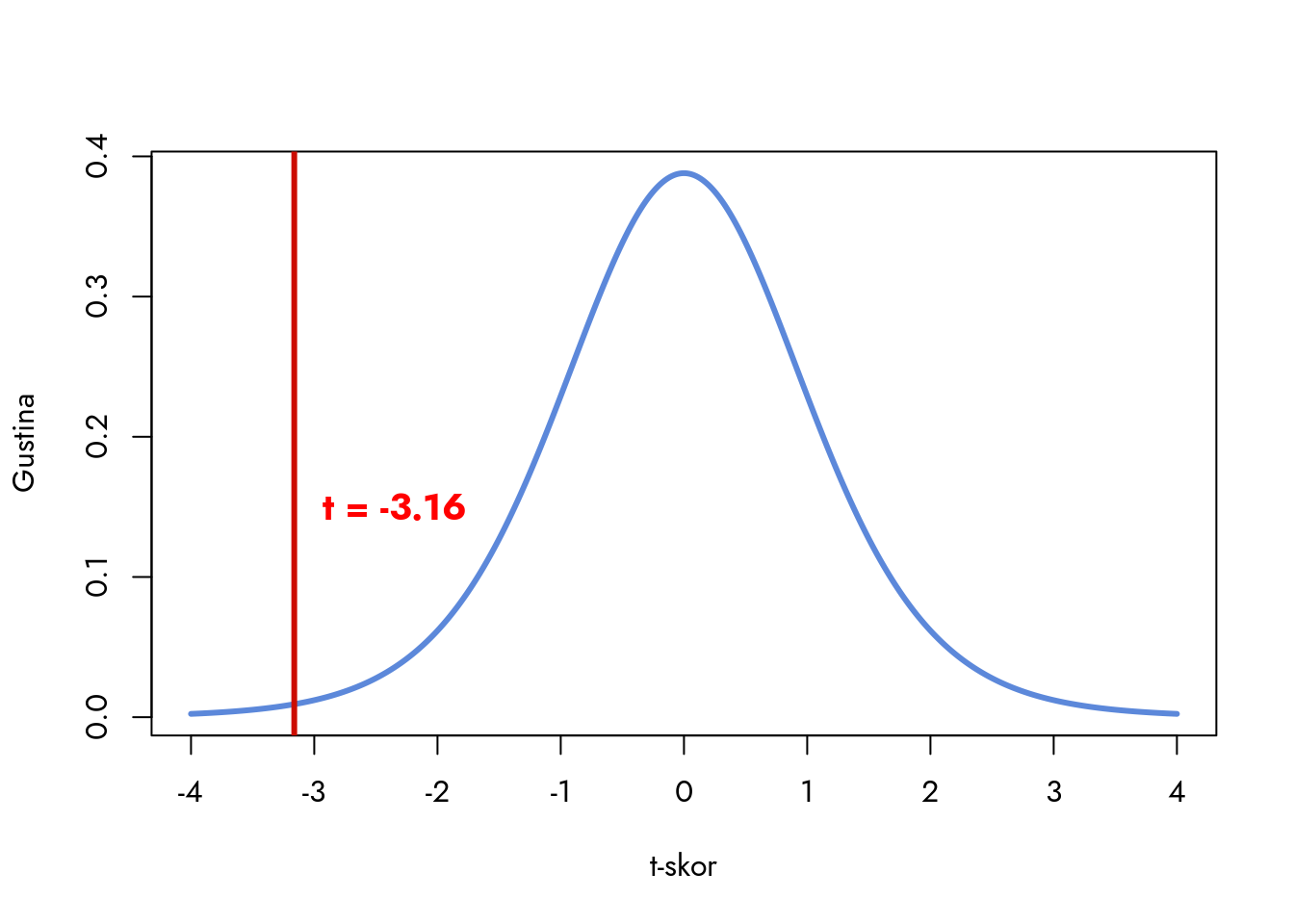
Slika 8.3: t-distribucija za t-statistiku
T-statistika od -3.16 nalazi se na levoj strani distribucije. Da bismo odredili p-vrednost, računamo površinu ispod krive t-distribucije. P-vrednost predstavlja površinu ispod krive levo od t-skora. U R-u ovo računamo koristeći funkciju pt() koja daje kumulativnu verovatnoću za zadati t-skor i stepene slobode.
Ovo je suštinska razlika u odnosu na Z-distribuciju - ovde eksplicitno uvažavamo veličinu uzorka pri računanju p-vrednosti. Za male uzorke, repovi distribucije postaju širi, a p-vrednost se povećava (Slika 10.5). Ova osobina nam omogućava preciznije modelovanje neizvesnosti zaključaka kada radimo sa malim uzorcima.
Da vidimo konkretnu p-vrednost za naš uzorak.
Prikaži kod
p <-pt(t, df)cat("p-vrednost:", round(p, 4), "\n")
1
Računamo p-vrednost za našu t-statistiku. Parametri su t-skor i stepeni slobode.
p-vrednost: 0.0058
Naš test daje p-vrednost od 0.006, što je značajno manje od standardnih pragova 0.05 i 0.01. Ovako niska p-vrednost pruža snažan dokaz za odbacivanje nulte hipoteze na nivou značajnosti 0.05. Šta nam to konkretno govori? Ako pretpostavimo da studenti u populaciji zaista uče 30 sati, verovatnoća da dobijemo ovakav uzorak je izuzetno mala. Logično je, dakle, da odbacimo tu pretpostavku. Zaključak je jasan: studenti u proseku provode manje od 30 sati pripremajući ovaj ispit.
Da bismo preciznije kvantifikovali ovaj zaključak, konstruišemo interval poverenja za aritmetičku sredinu populacije. Slično Z-testu, interval poverenja ima oblik:
\[
\overline{X} - t \cdot \frac{s}{\sqrt{n}} \leq \mu \leq \overline{X} + t \cdot \frac{s}{\sqrt{n}}
\]
gde je \(t\) granična t-distribucije sa \(n-1\) stepeni slobode i nivoom značajnosti \(\alpha\). Izračunajmo 95% interval poverenja za naš uzorak.
Prikaži kod
alpha <-0.05t <-qt(1- alpha/2, df)donja_granica <- as - t * sggornja_granica <- as + t * sgcat("Interval poverenja:", "\n")cat("(", round(donja_granica, 2), ",", round(gornja_granica, 2), ")")
1
Nivo značajnosti 0.05. Naš prag za odbacivanje nulte hipoteze.
2
Računamo graničnu vrednost t-distribucije za 95% interval poverenja. Zašto delimo alfa na dva? T-distribucija je simetrična, pa „odsecamo“ 2.5% sa svake strane.
3
Donja granica intervala poverenja. Naša „pesimistična“ procena.
4
Gornja granica. „Optimistična“ procena. Šta nam govori 95% interval poverenja (21.42, 28.58)? Kada bismo ponovili istraživanje mnogo puta, u 95% slučajeva bi stvarni prosek vremena učenja bio između 21.42 i 28.58 sati.
Interval poverenja:
( 21.42 , 28.58 )
Ključno: ovaj zaključak jasno odražava ograničenja malog uzorka - samo 10 studenata. To smo precizno obuhvatili kroz graničnu vrednost t-distribucije, koja se prilagođava veličini uzorka. Razmislite o sledećem: šta bi se desilo da smo anketirali 100 ili 1000 studenata? Uz istu standardnu devijaciju, interval poverenja bi se značajno suzio, dajući nam mnogo precizniju procenu stvarne vrednosti u populaciji.
Primetićete da su rezultati t-testa i intervala poverenja uporedivi sa onima iz Z-testa. Međutim, t-test otvara vrata ka složenijim istraživačkim problemima - njegova puna snaga dolazi do izražaja pri poređenju dve aritmetičke sredine.
8.4 t-test razlike dve aritmetičke sredine
Istraživanja u društvenim naukama najčešće imaju komparativnu prirodu. Osnovni primer je analiza razlika između dve populacije. Populacije uglavnom predstavljaju različite društvene grupe, a cilj je otkriti razlike između njih po određenom obeležju.
Ovakve populacije zovemo nezavisnim jer ne postoji preklapanje između grupa. Fokusiraćemo se upravo na nezavisne populacije i uzorke, budući da oni predstavljaju okosnicu većine socioloških istraživanja.
U psihologiji i medicini češće srećemo zavisne populacije i uzorke, što je karakteristično za eksperimentalna istraživanja. Uzmimo primer medicinskog istraživanja efikasnosti tablete za snižavanje krvnog pritiska: dva uzorka čine isti ispitanici, a merimo njihov pritisak pre i posle terapije. Pošto su jedinice uzorka identične osobe, nazivamo ih zavisnim. U širem smislu govorimo o zavisnim populacijama, jer to obuhvata sve potencijalne pacijente pre i posle terapije.
Kod nezavisnih uzoraka, definišemo dve odvojene grupe već pri konstrukciji uzorka. Ispitanike raspoređujemo u jedan ili drugi uzorak prema jasno definisanim kriterijumima grupa koje istražujemo. Primer koji ćemo analizirati koristi klasičnu podelu u sociologiji: uzorke prema polu, odnosno uzorak muškaraca i žena.
Vratimo se na konkretan primer studije o prosečnim zaradama u Srbiji. Naši podaci su organizovani tako da je uzorak podeljen na muškarce i žene, a cilj nam je da utvrdimo postoji li značajna razlika u prosečnim zaradama između ove dve grupe. Pogledajmo kako izgledaju podaci:
Prikaži kod
podaci <-"https://gist.githubusercontent.com/atomashevic/8c30bc0a11ba93ec934a12d0e08a6d17/raw/4924fc12814787602001e5058ec774f3487fad64/primanja-pol.csv"podaci <-read.csv(podaci)head(podaci)
1
Učitavamo podatke s URL-a.
2
Prikazujemo prvih nekoliko redova tabele.
primanja pol
1 902 Z
2 986 M
3 890 Z
4 456 Z
5 831 Z
6 1091 M
Analizirajmo podatke sistematično. Naš problem sadrži dve varijable. Varijabla pol je kategorijalna i ima dve vrednosti: M i Z. Ovo je jasan primer nezavisnih uzoraka, jer muškarci i žene predstavljaju dve različite grupe. Jednostavnije rečeno - jedan ispitanik ne može istovremeno biti i muškarac i žena u varijabli pol.
Naša početna pretpostavka glasi: prosečne zarade muškaraca i žena u Srbiji su jednake. Drugim rečima, pol nema efekta na prosečnu zaradu. Ovo je nulta hipoteza koju ćemo testirati. Ona pretpostavlja da je razlika između proseka u populaciji nula, odnosno da ne postoji efekat. Upravo zbog toga je i zovemo nultom hipotezom. U matematičkoj notaciji to zapisujemo:
\[H_0: \mu_{M} = \mu_{\text{Z}}\]
ili
\[H_0: \mu_{M} - \mu_{\text{Z}} = 0\]
gde je \(\mu_{M}\) prosečna zarada muškaraca, a \(\mu_{\text{Z}}\) prosečna zarada žena u populaciji, odnosno među svim radno sposobnim građanima Srbije.
Alternativna hipoteza tvrdi suprotno - da postoji razlika između prosečnih zarada muškaraca i žena u Srbiji. Drugim rečima, prosečne zarade nisu jednake.
\[H_1: \mu_{M} \neq \mu_{\text{Z}}\]
Hipoteza podrazumeva postojanje efekta - pol utiče na prosečnu zaradu. To znači da postoji veza između pola osobe i njene zarade. U uzorku će se ovo manifestovati kroz različite prosečne zarade muškaraca i žena. Naravno, ovo ne znači da svaka žena zarađuje manje ili više od svakog muškarca, već da se prosečne vrednosti razlikuju. To ukazuje na činjenicu da u populaciji, odnosno u našem društvu, postoji mehanizam koji dovodi do toga da jedna grupa prosečno zarađuje više od druge. Koji je to mehanizam? Možemo izneti neke pretpostavke - možda je reč o diskriminaciji, društvenim normama, razlikama u obrazovanju ili nekim drugim faktorima. Međutim, na ovom nivou statističke analize ne možemo dati konačan odgovor; za to je potrebno dublje istraživanje i teorijski okvir.
Kako testirati ove hipoteze? Prvo moramo detaljno pogledati podatke. Potrebno je izračunati broj muškaraca i žena u uzorku, a zatim i prosečne zarade za svaku grupu. Krenimo s tim:
Prikaži kod
muskarci <- podaci[podaci$pol =="M", ]zene <- podaci[podaci$pol =="Z", ]n_m <-nrow(muskarci)n_z <-nrow(zene)cat("Broj muškaraca u uzorku:", n_m, "\n")cat("Broj žena u uzorku:", n_z, "\n")
1
Izdvajamo podatke o muškarcima. Pravimo novu varijablu muskarci koja sadrži sve redove gde je vrednost varijable pol jednaka "M". Uzimamo sve kolone.
2
Izdvajamo podatke o ženama. Pravimo novu varijablu zene koja sadrži sve redove gde je vrednost varijable pol jednaka "Z". Uzimamo sve kolone.
3
Računamo broj muškaraca i broj žena u uzorku koristeći funkciju nrow koja broji redove u tabeli podataka.
Broj muškaraca u uzorku: 80
Broj žena u uzorku: 40
Vidimo da uzorak nije balansiran - broj muškaraca je dvostruko veći od broja žena. Ovo može biti rezultat načina uzorkovanja ili jednostavno slučajnost. Za trenutnu analizu taj disbalans nije kritičan, pa nastavljamo dalje. Fokusirajmo se na ono što je bitno - računanje prosečnih zarada za muškarce i žene:
Računamo prosečnu zaradu muškaraca. Funkcija mean će izračunati aritmetičku sredinu zarada za sve muškarce.
2
Računamo prosečnu zaradu žena. Funkcija mean će izračunati aritmetičku sredinu zarada za sve žene.
3
Računamo standardnu devijaciju zarada muškaraca. Funkcija sd će izračunati standardnu devijaciju zarada za sve muškarce.
4
Računamo standardnu devijaciju zarada žena. Funkcija sd će izračunati standardnu devijaciju zarada za sve žene.
Prosečna zarada muškaraca: 844.78
Prosečna zarada žena: 781.58
Standardna devijacija zarada muškaraca: 230.93
Standardna devijacija zarada žena: 168.86
Rezultati pokazuju da žene u našem uzorku imaju prosečno za nešto više od 60 EUR manja primanja u odnosu na muškarce. Ovo je prvi signal da postoji razlika između prosečnih primanja muškaraca i žena. Međutim, ključno je pitanje: da li je ta razlika dovoljno izražena da bismo mogli zaključiti da postoji stvarni efekat pola na prosečna primanja? Da li je razlika statistički značajna? Za odgovore na ova pitanja moramo primeniti statističke testove.
Pre nego što to uradimo, vizualizujmo naše podatke pomoću dva histograma.
Funkcija hist prikazuje distribuciju zarada za sve ispitanike sa vrednošću pol jednakom "M". Histogram je plave boje.
2
Funkcija hist prikazuje distribuciju zarada za sve ispitanike sa vrednošću pol jednakom "Z". Histogram je crvene boje.
3
Linija plave boje označava prosečne zarade muškaraca, dok crvena linija označava prosečne zarade žena.
4
Strelica pokazuje razliku od 60 EUR između muškaraca i žena.
5
Tekst prikazuje konkretnu vrednost razlike zarada.
6
Legenda pomaže u razlikovanju histograma muškaraca i žena.
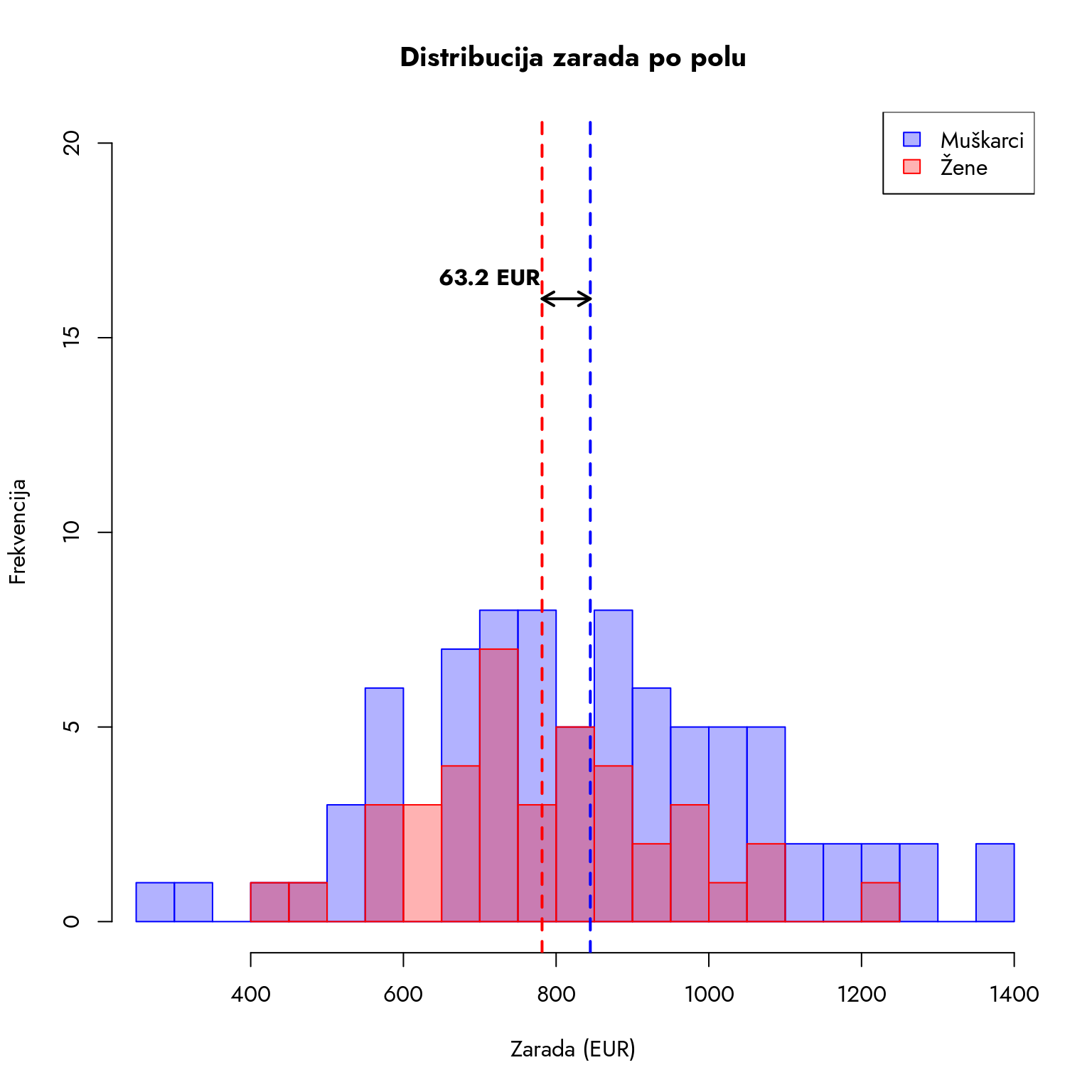
Slika 8.4: Distribucija zarada po polu
Na grafikonu vidimo da se aritmetičke sredine (prikazane isprekidanim linijama) nalaze sa različitih strana podeoka od 800 EUR. Iako zarade žena izgledaju pomerene ulevo u odnosu na muškarce, distribucija otkriva složeniju sliku. Crveni histogram je uži, što ukazuje da su zarade žena koncentrisanije u nižem delu distribucije, dok plavi histogram pokazuje širi raspon zarada muškaraca.
Centralno pitanje je sledeće: da li je ova uočena razlika između prosečnih zarada dovoljno izražena da bismo mogli zaključiti da postoji stvaran efekat pola na primanja? Za odgovor na ovo pitanje koristićemo t-test za dva nezavisna uzorka.
Za t-test nam je potrebna statistika testa. U prethodnim primerima, statistika testa merila je odstupanje uzorka od vrednosti nulte hipoteze. Sada ćemo se usmeriti na razliku između dve aritmetičke sredine.
Trenutno, razlika između prosečnih zarada iznosi -63.2 EUR. Šta predviđa nulta hipoteza? Kao što sam naziv sugeriše - nulu. Dakle, statistiku testa računamo prema formuli:
\[
t = \frac{(\overline{X}_M - \overline{X}_Z) - 0}{SG_{M-Z}}
\]
Ovde uzimamo razliku između dve aritmetičke sredine i delimo je sa standardnom greškom razlike (\(SG_{M-Z}\)). Standardnu grešku razlike između dve aritmetičke sredine računamo na sledeći način:
\[
SG_{M-Z} = \sqrt{SG_M^2 + SG_Z^2}
\tag{8.1}\]
Zašto računamo standardnu grešku na ovaj način? Ova formula proizilazi iz činjenice da imamo dva izvora neizvesnosti jer proučavamo dve različite grupe. Svaka grupa donosi svoju aritmetičku sredinu i standardnu devijaciju iz zasebnih uzoraka. Kada analiziramo razliku između ovih sredina, moramo obuhvatiti sve izvore neizvesnosti, što znači da se standardne greške moraju kombinovati.
Matematički elegantno rešenje je sabiranje kvadrata standardnih grešaka i izračunavanje kvadratnog korena, čime dobijamo jedinstvenu, kombinovanu standardnu grešku koja precizno odražava ukupnu neizvesnost naše procene.
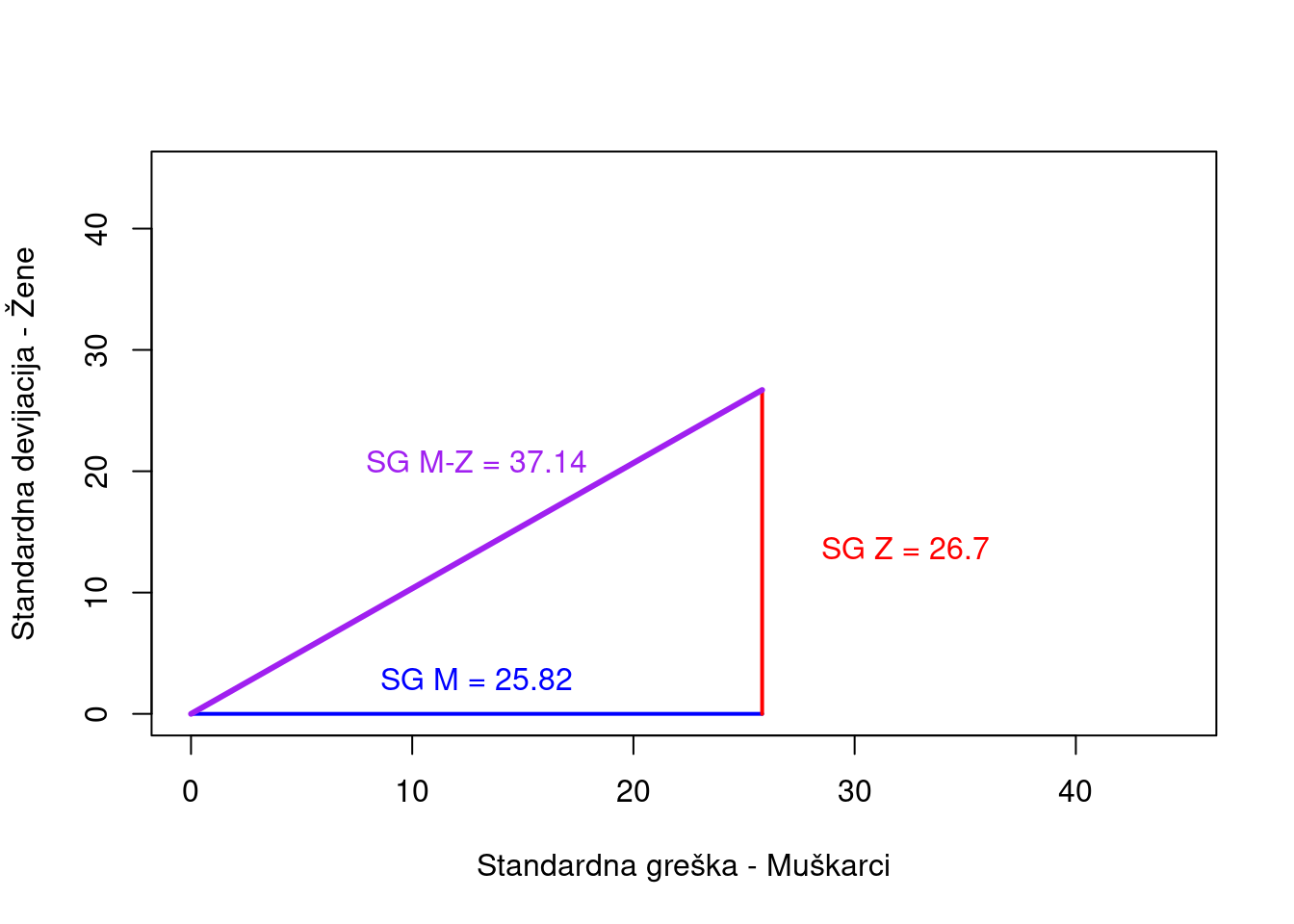
TipGeometrijska interpretacija
Da li vam je izraz \(\sqrt{SG_M^2 + SG_Z^2}\) poznat? Ako se sećate Pitagorine teoreme, prepoznaćete da on predstavlja dužinu hipotenuze pravouglog trougla čije su katete \(SG_M\) i \(SG_Z\). Ovo je elegantna geometrijska interpretacija standardne greške razlike između dve aritmetičke sredine.
Slika 8.5: Geometrijska interpretacija standardne greške razlike
Obe standardne greške aritmetičkih sredina iznose približno 26 EUR. Kada ih kombinujemo, dobijamo standardnu grešku razlike između dve aritmetičke sredine koja prelazi 36 EUR. Ovo jasno pokazuje zašto moramo uzeti u obzir sve izvore neizvesnosti kada analiziramo razlike između grupa. Matematički gledano, hipotenuza pravouglog trougla je uvek duža od kateta - analogno tome, standardna greška razlike između dve aritmetičke sredine je nužno veća od pojedinačnih standardnih grešaka.
Standardna greška razlike je uvek veća od pojedinačnih standardnih grešaka aritmetičkih sredina. Kad god poredimo dve grupe, moramo uzeti u obzir sve izvore neizvesnosti koji se kombinuju i povećavaju ukupnu grešku merenja. Iz ovoga sledi važna pouka: iako je standardna greška aritmetičke sredine jednog uzorka (oko 800 EUR) manja od standardne greške razlike dve sredine (oko 60 EUR), procena pojedinačne sredine je preciznija. Praktična posledica je sledeća - teže je statistički dokazati postojanje razlike između dve grupe nego proceniti pojedinačnu sredinu, jer je standardna greška razlike veća od standardnih grešaka pojedinačnih sredina.
TipJednake i nejednake varijanse
Način na koji dolazimo do informacije o standardnoj greški razlike zavisi od pretpostavke o varijansama u populacijama. U našem slučaju, pretpostavljamo da je varijansa, odnosno varijabilitet zarada, različit u obe populacije. Razlike u varijabilitetu unutar populacije žena i muškaraca mogu biti posledica različitih faktora, kao što su obrazovna i starosna struktura, kao i razlike u zaposlenju. Ovakav pristup se naziva pretpostavka o nejednakim varijansama. Ovo je složeniji slučaj i zbog toga imamo „inflaciju“ standardne greške razlike, što je direktna posledica dodatne neizvesnosti.
Postoji i jednostavniji pristup - možemo pretpostaviti da su varijanse u obe populacije jednake. Ovo je pretpostavka o jednakim varijansama. U tom slučaju, standardna greška razlike između dve aritmetičke sredine se računa na elegantniji način.
Ova formula izgleda kompleksnije, ali zapravo predstavlja ponderisanu varijansu. Ona kombinuje veličinu uzorka i standardne greške pojedinačnih grupa, dajući veći značaj većem uzorku.
Zašto je to važno? Pod pretpostavkom jednakih varijansi, standardne devijacije iz uzoraka služe kao procenitelji jedne populacijske varijanse. Logično je da veći uzorak daje precizniju procenu te varijanse, pa mu dodeljujemo veću težinu. Ova ponderacija je ključna jer minimizuje pristrasnost u proceni varijanse.
Na kraju, standardnu grešku razlike izračunavamo koristeći ovu varijansu:
Uzimamo u obzir veličinu i jednog i drugog uzorka. Razlika u veličini uzoraka (duplo više muškaraca nego žena) nije problem jer oba poduzorka doprinose našem razumevanju varijabiliteta u populaciji.
Kad je pretpostavka o jednakoj varijansi opravdana? Najčešće je primenjujemo kada koristimo standardizovane merne instrumente ili kada su grupe koje poredimo vrlo slične po svim karakteristikama osim one koju proučavamo. Zamislite, na primer, merenje IQ-a na studentskim uzorcima iz dve države. Nema teorijskog razloga zašto bi varijabilitet IQ-a studenata iz Švajcarske bio drugačiji od varijabiliteta studenata iz Indije. U takvom slučaju, pretpostavka o jednakim varijansama je logična.
U našem slučaju znamo vrlo malo o tome kako zarade variraju između muškaraca i žena. Stoga je metodološki ispravnije krenuti od pretpostavke o nejednakim varijansama.
Hajde da vidimo kako izgleda ova razlika u praksi na našem primeru.
Prikaži kod
SG_M <- sd_m /sqrt(n_m)SG_Z <- sd_z /sqrt(n_z)SG_MZ <-sqrt(SG_M^2+ SG_Z^2)cat("Standardna greška razlike između dve aritmetičke sredine: ", round(SG_MZ, 2), "\n")
Standardna greška razlike između dve aritmetičke sredine: 37.14
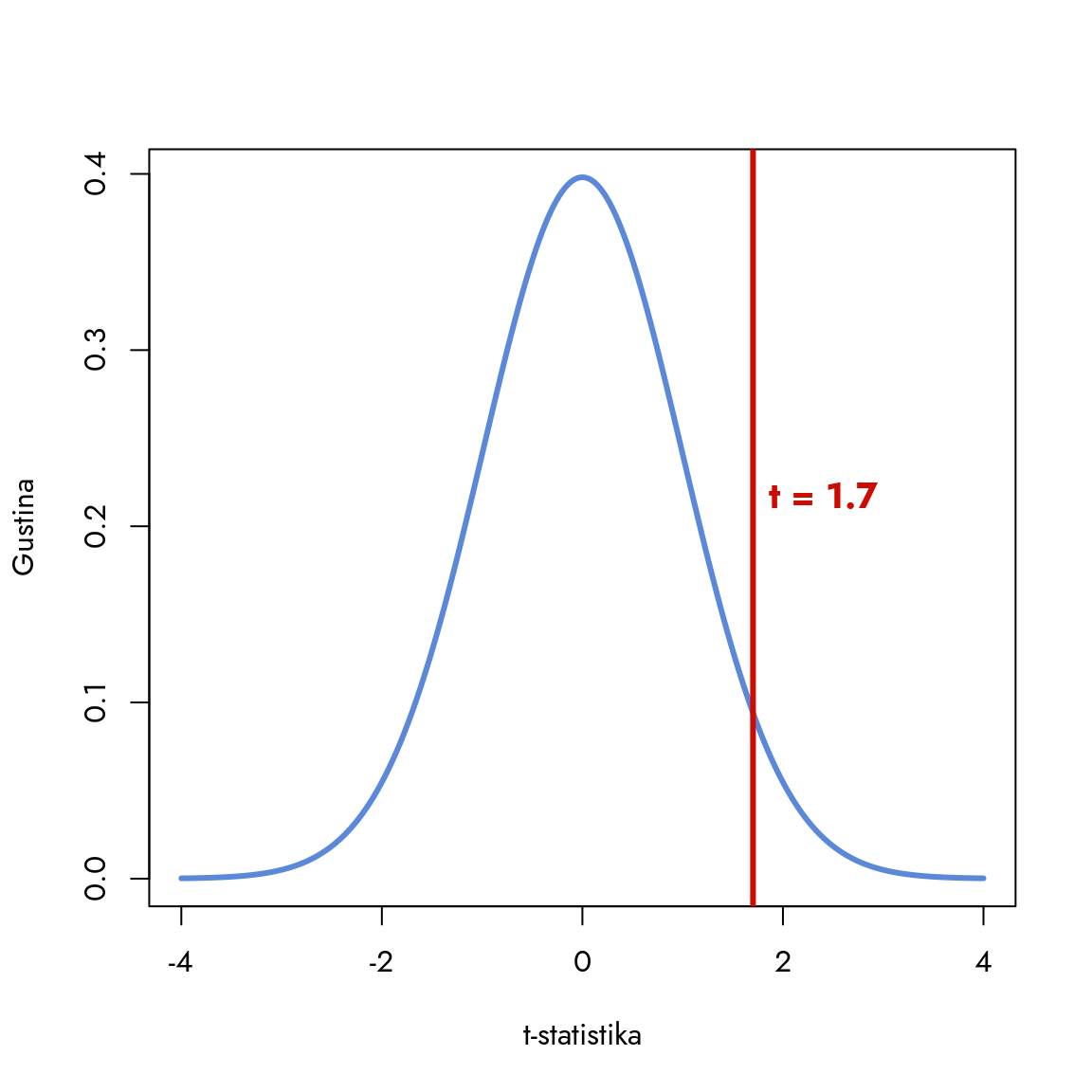
Statistika našeg testa iznosi 1.7. Šta nam ova vrednost govori o nultoj hipotezi? Odgovor pronalazimo kroz konstrukciju t-distribucije. Za to nam je prvo potreban broj stepeni slobode. Naš uzorak ima ukupno \(n_M + n_Z = 80 + 40 = 120\) opservacija. Međutim, broj stepeni slobode je manji jer procenjujemo dve aritmetičke sredine. Konkretno, imamo \(n_M + n_Z - 2 = 118\) stepeni slobode.
Sa ovom informacijom možemo vizuelno predstaviti t-distribuciju i locirati našu test statistiku na njoj.
Prikaži kod
par(family ="Jost")x <-seq(-4, 4, 0.01)y <-dt(x, df =118)plot(x, y, type ="l", col ="#5C88DAFF", lwd =3, xlab ="t-statistika", ylab ="Gustina")abline(v = t, col ="#CC0C00FF", lwd =3, lty =1)text(t +0.7, 0.2, paste("t =",round(t, 2)), col ="#CC0C00FF", pos =3, cex =1.2, font =2)
1
Funkcija dt računa gustinu t-distribucije za datu vrednost t i broj stepeni slobode. U našem slučaju, broj stepeni slobode je 118.
Slika 8.6: t-distribucija i t-statistika
Naša statistika se nalazi u desnom delu distribucije, što ukazuje da je dobijena razlika veća od one koju bismo očekivali pod nultom hipotezom. Za donošenje konačnog zaključka moramo izračunati p-vrednost. Ova vrednost će nam precizno reći da li je signal koji smo dobili iz uzorka dovoljno jak (statistički značajan) da bismo mogli odbaciti nultu hipotezu.
Vizualizujmo p-vrednost na t-distribuciji.
Prikaži kod
par(family ="Jost", mar =c(5, 4, 2, 2) +0.1)x <-seq(-4, 4, 0.01)y <-dt(x, df =118)plot(x, y, type ="l", col ="#5C88DAFF", lwd =3, xlab ="t-statistika", ylab ="Gustina", ylim =c(0, 0.4), yaxs ="i")segments(t, 0, t, dt(t, df =118), col ="#CC0C00FF", lwd =2)polygon(c(x[x > t], rev(x[x > t])), c(y[x > t], rep(0, sum(x > t))), col =rgb(1, 0, 0, 0.3), border =NA)segments(-t, 0, -t, dt(-t, df =118), col ="#CC0C00FF", lwd =2)polygon(c(x[x <-t], rev(x[x <-t])), c(y[x <-t], rep(0, sum(x <-t))), col =rgb(1, 0, 0, 0.3), border =NA)p_vrednost <-2*pt(-t, df =118)text(0, 0.05, paste("p =", round(p_vrednost, 4)), col ="red", pos =3, cex =1.2, font =2)
1
Definišemo opseg x-ose.
2
Crtamo t-distribuciju i označavamo t-statistiku.
3
Računamo p-vrednost za t-test. Vrednost funkcije pt množimo sa dva jer računamo površinu u oba repa distribucije.
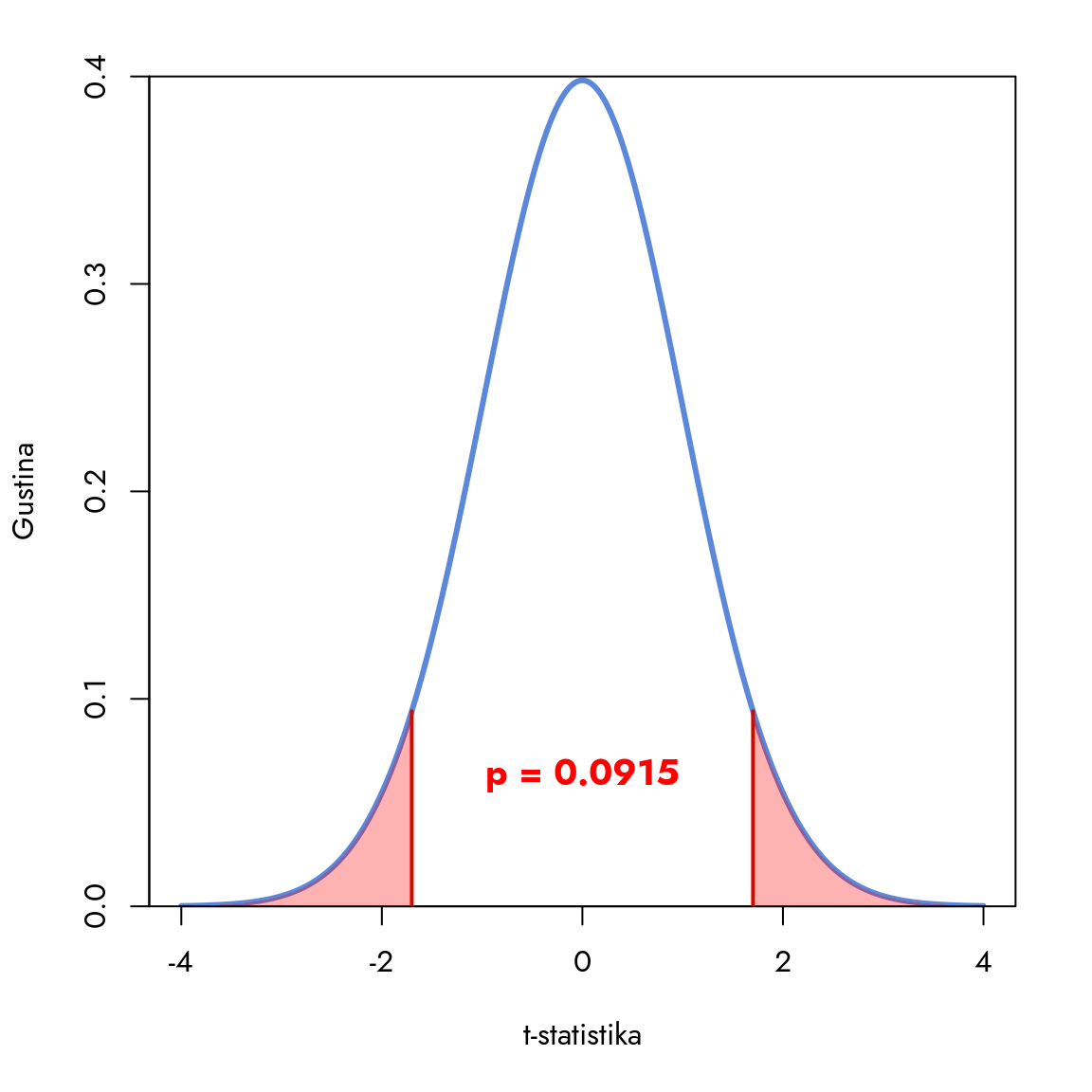
Slika 8.7: t-distribucija i p-vrednost
Budući da koristimo dvostrani test, razmatramo ukupnu površinu u oba repa distribucije: levo i desno od naše t-statistike (-1.7 i 1.7). P-vrednost za t-test računamo u R-u pomoću funkcije pt. Ova funkcija izračunava površinu ispod t-distribucije do date t-statistike, uzimajući u obzir stepene slobode. Dobijeni rezultat množimo sa dva jer, kao što je prikazano na grafikonu, posmatramo oba ekstremna dela t-distribucije.
Računamo p-vrednost za t-test. Vrednost funkcije pt množimo sa dva. Koristimo -t zato što ova funkcija računa površinu ispod krive sa leva na desno.
2
Zaokružujemo p-vrednost na četiri decimale i prikazujemo je.
P-vrednost: 0.0915
P-vrednost je približno 0.09 i veća je od standardnih nivoa značajnosti 0.05 i 0.01. To nam ukazuje da naš rezultat nije dovoljno ekstreman u odnosu na ono što predviđa nulta hipoteza. Preciznije, razlika od 63 EUR koju smo izmerili u uzorku nije dovoljno snažan signal da bismo zaključili da postoji stvarna razlika između prosečnih zarada muškaraca i žena u populaciji. Ovo je suštinska informacija koju dobijamo iz našeg statističkog testa.
Prema tome, nemamo dovoljno dokaza da odbacimo nultu hipotezu i zaključujemo da ne postoje razlike u prosečnim zaradama muškaraca i žena u Srbiji.
NoteLična karta metoda: t-test za dva nezavisna uzorka
Šta radi? Proverava da li je razlika između prosečnih vrednosti dva nezavisna uzorka statistički značajno različita od nule.
Kada se koristi? Kada želimo da uporedimo dve grupe ispitanika i utvrdimo postojanje statistički značajne razlike između njih.
Koliko varijabli imamo? Dve: jednu binarnu kategorijalnu (npr. pol) merenu nominalnom ili ordinalnom skalom i jednu kvantitativnu (npr. zarada) merenu intervalnom ili racio skalom, u posebnim slučajevima i ordinalnom skalom. Grupe ispitanika formiraju se na osnovu binarne kategorijalne varijable.
Kako izgleda statistika testa? Statistika t-testa računa se kao količnik između razlike aritmetičkih sredina uzoraka i standardne greške razlike.
\[
t = \frac{(\overline{X}_1 - \overline{X}_2) - 0}{SG_{1-2}}
\]
gde je \(SG_{1-2}\) standardna greška razlike između dve aritmetičke sredine.
Kako računamo p-vrednost? Za dvosmerni test, p-vrednost se računa kao dvostruka površina ispod t-distribucije do vrednosti t-statistike sa leve strane distribucije. Za jednosmerni test, p-vrednost se računa kao površina ispod t-distribucije do vrednosti t-statistike.
8.5 Interval poverenja za razliku aritmetičkih sredina
Sada možemo primeniti drugi oblik statističkog zaključivanja - interval poverenja za razliku dve aritmetičke sredine. Ovaj pristup nam daje drugačiju perspektivu o razlici između prosečnih zarada muškaraca i žena.
Konstrukcija intervala poverenja počinje od osnovne tačke - razlike aritmetičkih sredina uzoraka: \(\overline{X}_M - \overline{X}_Z\). Nakon toga dodajemo i oduzimamo kritičnu vrednost \(t_{\alpha/2; df}\), koja je određena željenim nivoom poverenja i brojem stepeni slobode.
Kritične vrednosti definišu granice u kojima očekujemo da se nalazi naša statistika testa, uz pretpostavku da obuhvata 95% ili 99% svih mogućih vrednosti.
Pri konstrukciji intervala poverenja od 95%, granične slučajeve postavljamo tako da „odsecamo“ po 2.5% vrednosti sa obe strane distribucije. Za dobijanje kritične vrednosti potrebni su nam granična vrednost t-statistike i standardna greška razlike aritmetičkih sredina.
Kritičnu vrednost izračunavamo pomoću R funkcije qt().
Računamo kritičnu vrednost t-statistike za nivo poverenja od 95%.
Kritična vrednost t-statistike: 1.98
Konkretno, proširujemo interval od \(\overline{X}_M - \overline{X}_Z\) za \(t_{\alpha/2; df} \cdot SG_{1-2}\), gde je \(SG_{1-2}\) standardna greška razlike između dve aritmetičke sredine. S obzirom da je t-statistika približno 2, interval efektivno proširujemo za \(2 \cdot SG_{1-2}\).
Prikaži kod
razlika <- X_m - X_zdonja_granica <- razlika - t * SG_MZgornja_granica <- razlika + t * SG_MZcat("Interval poverenja: (", round(donja_granica, 2), ", ", round(gornja_granica, 2), ")\n")
1
Računamo razliku aritmetičkih sredina.
2
Računamo donju i gornju granicu intervala poverenja.
Interval poverenja: ( -10.35 , 136.75 )
Ovaj interval obuhvata vrednosti od -10 do +136 EUR, što ukazuje na značajnu neizvesnost u proceni razlike. Interval pokriva tri moguća scenarija:
Negativna razlika do -10 EUR - žene imaju veća prosečna primanja od muškaraca.
Nulta razlika - ne postoji razlika u prosečnim primanjima između muškaraca i žena.
Pozitivna razlika do 136 EUR - muškarci imaju veća prosečna primanja od žena.
Činjenica da interval obuhvata sva tri scenarija jasno pokazuje ograničenja našeg uzorka. Na osnovu ovih podataka ne možemo pouzdano utvrditi ni postojanje ni nepostojanje razlike u primanjima između polova. Drugim rečima, neizvesnost u našim procenama je toliko velika da ne možemo isključiti mogućnost da razlike između ove dve populacije zapravo ne postoje.
Na osnovu intervala poverenja, naš zaključak je jasan: Sa nivoom pouzdanosti od 95%, razlika između prosečnih zarada muškaraca i žena kreće se u intervalu od -10 do 136 EUR. U praksi to znači: ako bismo ponavljali ovo istraživanje i izvlačili nove uzorke, u 95% slučajeva razlika između prosečnih zarada bi se našla unutar ovog intervala.
Šta nam ovaj širok interval govori? U matematičkom smislu, on obuhvata sve moguće scenarije. Posebno je zanimljiva asimetrija intervala - proteže se dalje u pozitivnom smeru, što ukazuje da ćemo u ponovljenim uzorcima verovatnije dobiti pozitivnu razliku između prosečnih zarada muškaraca i žena. Ipak, jasno je da naši podaci nisu dovoljno precizni da bismo mogli tvrditi kako je ova razlika sistematska na nivou cele populacije.
Ova situacija je kao kada u nekom kriminalističkom slučaju, ubica biva uhvaćen, svima je očigledno da je on kriv, ali prosto nema materijalnih dokaza koji bi to potvrdili na sudu. Isto, tako mi imamo teorijske razloge da verujemo da su prosečna primanja muškaraca veća, imamo rezultate prethodnih istraživanja koja to potvrđuju, imamo rezultat iz uzorka koji to sugeriše, ali nedovoljno dobro za standarde statističkog testa.
8.6 Veličina efekta
Postoji još jedan način da izmerimo jačinu dokaza koje imamo u korist postojanja efekta, odnosno uticaja jedne varijable na drugu. Reč je o indikatoru koji nazivamo jačina ili veličina efekta, a dobijamo ga pomoću Koenove d statistike.
Logika iza ove statistike je gotovo identična statistici t-testa. Jedina razlika je u tome što u formuli ne koristimo standardnu grešku, već združenu ili kombinovanu standardnu devijaciju. Kao rezultat dobijamo vrednost koja se direktno i jednostavno može interpretirati. Formula glasi:
\[
d = \frac{\overline{X}_M - \overline{X}_Z}{SD_{M-Z}}
\]
gde je \(SD_{M-Z}\) združena standardna devijacija, koja se računa na sledeći način:
Formula je složena, ali njena složenost nam trenutno nije bitna. Pošto se ova kombinovana standardna devijacija često koristi u različitim analizama, napisaćemo R funkciju koja će nam olakšati izračunavanje kad god nam zatreba.
Primenjujemo formulu iznad i vraćamo izračunatu vrednost putem funkcije return()
Sada jednostavno možemo da izračunamo veličinu efekta za naš primer.
Prikaži kod
d <- (X_m - X_z) /sd_komb(muskarci$primanja, zene$primanja)cat("Koenova d statistika: ", round(d, 2), "\n")
1
Primenjujemo formulu za Koenovu d statistiku.
Koenova d statistika: 0.3
Rekli smo da je vrednost Koenove d statistike lako interpretirati. Ove vrednosti nam služe kao referentne tačke za interpretaciju:
0.2: mali efekat
0.5: srednji efekat
0.8: veliki efekat
Odakle dolaze ove referentne vrednosti? One su postavljene po konvenciji, na osnovu empirijskih rezultata primene Koenove d statistike u slučajevima gde imamo jasnu potvrdu postojanja ili nepostojanja efekta.
Evo konkretnijeg načina interpretacije ovih vrednosti. Znamo da je aritmetička sredina muškaraca u uzorku veća od aritmetičke sredine žena. Postavimo ključno pitanje: koji procenat žena ima zaradu manju od prosečne zarade muškaraca?
Teorijski maksimalni efekat bi postojao kada bi sve žene imale zaradu manju od prosečne zarade muškaraca. Takve ekstremne razlike su retke u realnim podacima. U praksi su razlike suptilnije, ali koliko suptilnije? Koenova d statistika nam daje precizan odgovor na ovo pitanje. U tabeli ispod možete videti procente koji odgovaraju
Odnos veličine efekta i procenta opservacija i jedne grupe koji se nalaze ispod proseka druge grupe.
Veličina efekta
%
0.2
58
0.5
69
0.8
79
Kada bismo dobili Koenov d od 0.2, to bi značilo da otprilike 60% žena ima zaradu manju od prosečne zarade muškaraca. Sa druge strane, ako bismo dobili Koenov d od 0.8, to bi značilo da 80% žena ima zaradu manju od prosečne zarade muškaraca.Imajte u vidu da, ako su podaci približno normalno raspoređeni ili približno simetrični, 50% muškaraca takođe ima zaradu manju od prosečne zarade muškaraca. Zato se 60% uzima kao prvi korak, odnosno prva granica za veličinu efekta.
8.6.1 Više od dve grupe?
Primer koji smo obradili u ovom poglavlju je primer jednostavnog statističkog modela koji opisuje uticaj jedne nezavisne kategorijale binarne varijable na zavisnu kvantitativnu varijablu. Ovaj uticaj smo istraživali tako što smo uporedili prosečne vrednosti zavisne varijable između dve grupe. Imamo samo dve grupe zbog toga što smo kao nezavisnu varijablu izabrali biološki pol ispitanika, koji može da ima samo dve vrednosti.
TipNezavisne i zavisne varijable
Kada definišemo statistički model, vrlo često pravimo razliku između nezavisnih i zavisnih varijabli. Nezavisne varijable su one koje koristimo da bismo objasnili varijabilnost zavisne varijable. U našem slučaju, nezavisna varijabla je pol ispitanika, a zavisna varijabla su prosečna primanja.
Šta znači opisati varijabilinost? To znači da hoćemo da identifikujemo pravilnosti ili obrasce u razlikama koje postoje u zavisnoj varijabli. Konkretno, pokušali smo da objasnimo razlike u primanjima, tako što bismo podelili uzorak na dve grupe, muškarce i žene, i uporedili prosečne vrednosti primanja između njih. Da smo uspeli u tome, saznali bismo nešto novo o obrascu koji postoji u našim podacima – u proseku žene imaju niža primanja od muškaraca.
Da je to slučaj, to bi imalo važne implikacije. Na primer, značilo bi da kada bismo nasumično izabrali jednog muškarca i jednu ženu iz populacije, postoji veća verovatnoća da će muškarac imati veća primanja. To nam omogućava da predvidimo vrednost zavisne varijable (prosečna primanja) na osnovu nezavisne varijable (pol ispitanika). Naravno, ovo predviđanje nije savršeno precizno, ali nam pruža korisnu informaciju o primanjima ispitanika samo na osnovu njihovog pola.
Upravo zbog ove prediktivne moći, nezavisne varijable se često nazivaju prediktorima, a zavisne varijable kriterijumima. U našem primeru, pol ispitanika je prediktor, a prosečna primanja su kriterijum.
Šta ako želimo da analiziramo kompleksniju nezavisnu varijablu? Uzmimo logičan primer: očekujemo da zarada zaposlenog raste sa godinama iskustva u određenoj delatnosti. Teško je zamisliti da apsolutni početnik ima istu platu kao neko sa 10, 20 ili 30 godina iskustva.
Kako konstruisati statistički model koji može objasniti ove razlike? Naš trenutni alat zahteva grubu podelu ispitanika na „početnike“ i „iskusne“, nakon čega bismo uporedili prosečne zarade između grupa. Međutim, ova podela je previše pojednostavljena jer ignoriše činjenicu da je iskustvo kontinualna, a ne kategorička varijabla.
Idealno, trebalo bi da izračunamo prosečna primanja za svaku godinu iskustva - od 0 godina, preko 1 godine, 2 godine, i tako dalje. Ali šta sa osobama koje imaju 1.5 ili 2.25 godina iskustva? Kako uporediti prosečna primanja između ovih preciznih vrednosti?
Odgovor leži u jednom od najmoćnijih alata statističke analize - regresionoj analizi.
8.7 Zadaci
CautionZadatak 1 *
U zanimljivom pedagoškom eksperimentu, studenti su slušali isti jednosemestralni kurs. Kontrolna grupa je brojala 120 studenata koji su pratili nastavu i radili predispitne zadatke na klasičan način. Eksperimentalna grupa od 30 studenata imala je mogućnost korišćenja AI alata pri rešavanju predispitnih zadataka.
Obe grupe studenata polagale su identičan završni ispit. U kontrolnoj grupi, prosečna ocena iznosila je 7.80 sa standardnom devijacijom od 1.5. Studenti iz eksperimentalne grupe ostvarili su prosečnu ocenu 7.35 uz standardnu devijaciju od 1.2.
Istraživačka hipoteza pretpostavlja da će studenti koji su koristili AI alate postići niže prosečne ocene na završnom ispitu u poređenju sa studentima iz kontrolne grupe. Testirajte ovu hipotezu primenom t-testa za dva nezavisna uzorka, uz nivo značajnosti 0.05.
CautionZadatak 2 *
Da bismo bolje razumeli rezultate eksperimenta, potrebno je da proširimo analizu.
Izračunajte interval poverenja od 95% za razliku u prosečnim ocenama između kontrolne i eksperimentalne grupe. Šta nam dobijeni interval govori o efektima primene AI alata?
Izračunajte i interpretirajte veličinu efekta (Koenov d). Koliko je snažan uticaj AI alata na ocene studenata?
Na osnovu dobijenih rezultata, koje konkretne preporuke biste dali za dizajn budućih istraživanja koja bi preciznije merila efekte AI alata na akademski uspeh?
CautionZadatak 3 **
U narednoj fazi istraživanja o uticaju AI alata na akademski uspeh, istraživački dizajn je proširen. Kontrolna grupa je zadržana, ali su uvedene dve eksperimentalne grupe. Prva eksperimentalna grupa od 50 studenata koristila je AI alate tokom pripreme ispita, dok je druga eksperimentalna grupa od 30 studenata dobila mogućnost korišćenja AI alata i tokom samog ispita.
Rezultati studije prikazani su u tabeli:
Grupa
Prosečna ocena
Standardna devijacija
Kontrolna grupa
7.80
1.5
Eksperimentalna grupa 1
7.35
1.2
Eksperimentalna grupa 2
7.95
0.3
Pretpostavka je da će studenti iz eksperimentalne grupe 2 imati više prosečne ocene na završnom ispitu od studenata iz kontrolne grupe, kao i od studenata iz eksperimentalne grupe 1.
Testirajte ove dve hipoteze koristeći t-test za dva nezavisna uzorka na nivou značajnosti od 0.05. Pri analizi obratite posebnu pažnju na pretpostavke o (ne)jednakim varijansama.
Interpretirajte oba rezultata i formulišite celovit zaključak o uticaju AI alata na akademski uspeh studenata.
Ako biste želeli da uporedite sve grupe studenata međusobno, koliko bi statističkih testova bilo potrebno? Razmislite o nedostacima ovakvog pristupa.