Za razliku od prethodnog poglavlja, ovde ćemo se baviti neprekidnim, odnosno kontinuiranim varijablama. Kao primer uzećemo visinu izraženu u centrimetrima, koja može uzeti bilo koju vrednost iz određenog intervala.
Kod ovakvih varijabli, verovatnoća pojedinačne vrednosti je praktično nula. Zašto? Zbog prirode neprekidnog intervala - verovatnoća da ćemo u populaciji pronaći osobu visoku tačno 183,9088005321cm je zanemarljiva. Umesto toga, kod neprekidnih varijabli postavljamo praktičnija pitanja, poput „kolika je verovatnoća da će nasumično odabrani ispitanik biti visok između 180cm i 185cm?“.
Hajde da vidimo kako ovo funkcioniše na stvarnim podacima o visini ispitanika.
Prikaži kod
podaci <-read.csv("https://gist.githubusercontent.com/atomashevic/5f08daba08a4de48265c6ebf6da693dd/raw/be4b8f8c14a0acb57357a0f40e3b883419f80755/visine.csv")head(podaci)cat("Broj ispitanika je: ", nrow(podaci), "\n")
1
Učitavanje podataka o visinama ispitanika
2
Prikaz prvih nekoliko redova tabele
3
Ispis broja ispitanika u tabeli
pol visina
1 M 176.7964
2 M 179.2737
3 M 192.6903
4 M 181.5288
5 M 181.9697
6 M 193.8630
Broj ispitanika je: 400
U skupu podataka imamo 400 ispitanika sa precizno izmerenim visinama (do četiri decimale). Uz visinu, za svakog ispitanika imamo i podatak o polu.
Izračunajmo verovatnoću pronalaska osobe visine između 180cm i 185cm u našem uzorku.
Prikaži kod
podskup <- podaci[podaci$visina >180& podaci$visina <185,]cat("Broj ispitanika visine između 180cm i 185cm je: ", nrow(podskup), "\n")verovatnoca <-nrow(podskup) /nrow(podaci)cat("Verovatnoća da ćemo u uzorku pronaći neku osobu visine između 180cm i 185cm je: ", verovatnoca, "\n")
1
Izdvajanje podskupa ispitanika visine između 180cm i 185cm
2
Izračunavanje verovatnoće kao odnos broja ispitanika u podskupu i ukupnog broja ispitanika
Broj ispitanika visine između 180cm i 185cm je: 45
Verovatnoća da ćemo u uzorku pronaći neku osobu visine između 180cm i 185cm je: 0.1125
Vidimo da ta verovatnoća iznosi oko 11%. Za razliku od diskretnih varijabli, kod kontinuiranih varijabli nemamo mogućnost da jednostavno izračunamo verovatnoću za sve moguće ishode. Potrebno je da ih grupišemo u intervale (na primer, između 180cm i 185cm) i izračunamo frekvencije tih intervala.
Za vizuelni prikaz frekvencija intervala koristimo histogram, koji možemo kreirati pomoću funkcije hist u R-u.
podaci$visina je vektor podataka o visinama, osnovni argument funkcije hist
2
breaks argument govori R-u na koliko malih intervala treba podeliti sve vrednosti varijable podaci$visina
Slika 6.1: Histogram visina
Na histogramu uočavamo raspored visina u populaciji koji podseća na distribuciju zbirova bacanja kockica iz prethodnog poglavlja. Za jasniju interpretaciju histograma, pogledajmo osnovne mere deskriptivne statistike.
Histogram otkriva važan obrazac: većina visina grupiše se oko proseka (približno 172cm), a verovatnoća pojave ekstremnih vrednosti, poput 150cm ili 200cm, značajno je manja. Jasno je vidljivo da verovatnoća pronalaska osobe čija visina odstupa od proseka opada proporcionalno sa tim odstupanjem.
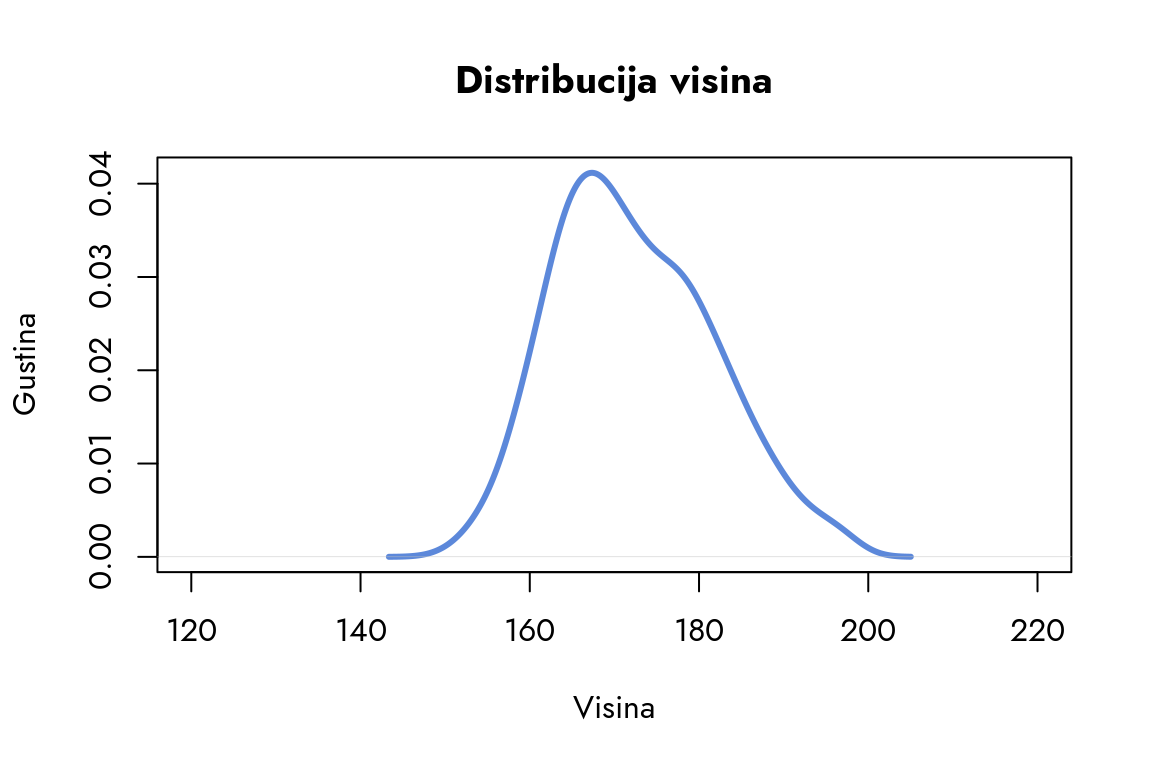
Ovakva pravilnost u opadanju verovatnoće nije proizvoljna. Da bismo preciznije analizirali ovaj obrazac i bolje razumeli njegovu prirodu, korisno je predstaviti distribuciju visina kontinuiranom linijom.
density funkcija računa gustinu verovatnoće za svaku vrednost u našem skupu podataka
2
lwd argument određuje debljinu iscrtane linije
3
xlim argument određuje granice grafikona na x-osi
Slika 6.2: Distribucija visina
Na grafikonu vidimo liniju (krivu) distribucije gustine koja pokazuje verovatnoću pojave različitih visina. Ne ulazeći duboko u matematičku definiciju gustine, možemo je posmatrati kao meru verovatnoće pojave određene visine, normalizovanu tako da je ukupna površina ispod krive jednaka 1. Grafikon ilustruje kako je verovatnoća najveća oko prosečne vrednosti (približno 172cm) i postepeno opada sa udaljavanjem od nje. Nagib krive precizno opisuje brzinu opadanja verovatnoće s odstupanjem od proseka.
Ova kriva pokazuje karakterističan oblik koji odgovara najvažnijoj teorijskoj distribuciji verovatnoće – normalnoj distribuciji. Poznata je i kao Gausova kriva, po Karlu Fridrihu Gausu, koji je do nje došao proučavajući obrasce grešaka u astronomskim merenjima (Gauss, 1823).
Pokušajmo da razumemo kako je Gaus otkrio normalnu distribuciju. Dok je noć za noći merio pozicije zvezda na nebu, uočio je nešto neočekivano: većina merenja se grupisala oko jedne centralne vrednosti, a greške su se javljale simetrično sa obe strane. Drugim rečima, verovatnoća da će izmerena pozicija zvezde odstupati za određenu vrednost iznad stvarne pozicije bila je jednaka verovatnoći da će odstupati za istu vrednost ispod.
Ova simetrična priroda grešaka imala je značajne praktične implikacije. Ponavljanjem merenja, pozitivne i negativne greške su se međusobno potirale, što je vodilo ka sve preciznijoj proceni stvarne pozicije zvezde. Naravno, drastične greške u merenju bile su retke i obično su bile posledica tehničkih problema ili nepovoljnih atmosferskih uslova. Upravo ovakav obrazac merenja i grešaka postavio je temelje onome što danas poznajemo kao normalnu distribuciju.
Da bismo konstruisali krivu normalne distribucije za naše podatke o visini, potrebna su nam dva ključna parametra: aritmetička sredina i standardna devijacija. Aritmetička sredina definiše centar distribucije - tačku maksimalne verovatnoće koja predstavlja vrh krive. Ona služi kao referentna tačka koja pozicionira distribuciju na x-osi.
Standardna devijacija ima ključnu ulogu u oblikovanju normalne distribucije. Ona definiše koliko su podaci koncentrisani oko aritmetičke sredine, odnosno koliko brzo opada verovatnoća sa udaljavanjem od centra distribucije. Kada je standardna devijacija manja, distribucija je uža i više zašiljena - podaci su zbijeniji oko proseka. Nasuprot tome, veća standardna devijacija rezultira širom, razvučenijom distribucijom gde su podaci raspoređeni na većem intervalu vrednosti.
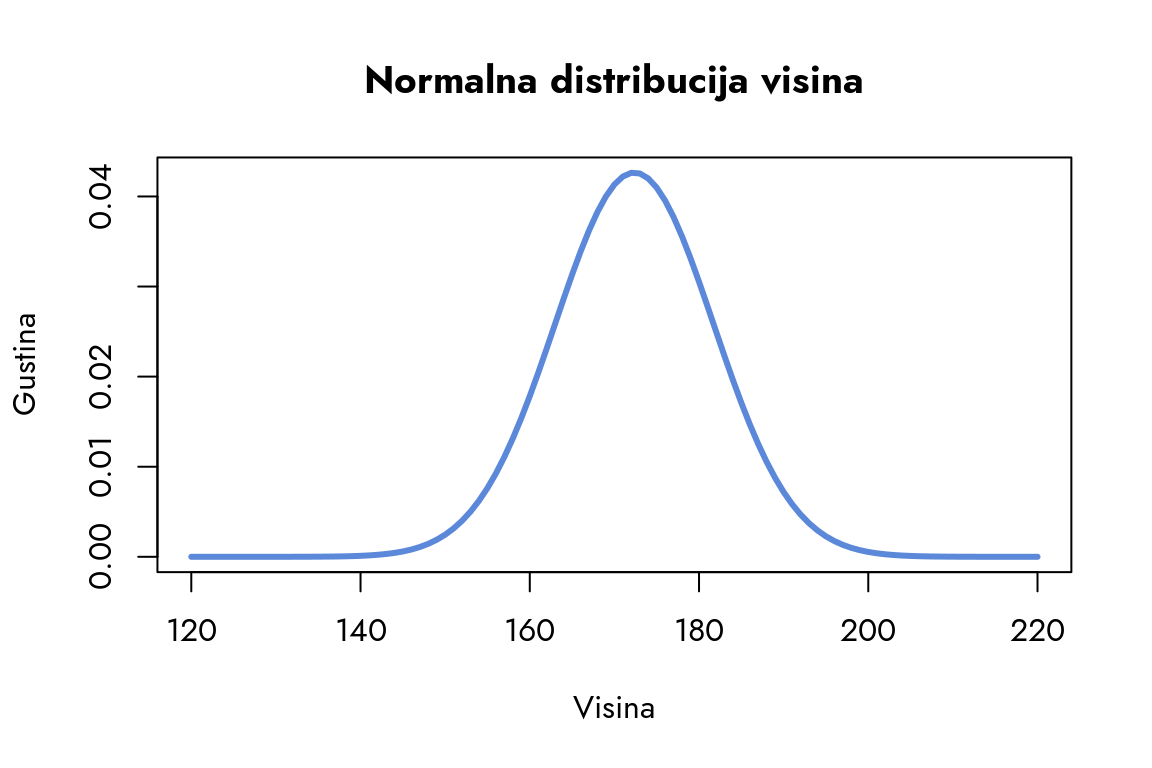
Da bismo bolje razumeli kako ova dva parametra oblikuju normalnu distribuciju naših podataka o visini, prikažimo je grafički.
dnorm (density-normal) je funkcija koja računa vrednost gustine normalne distribucije za datu vrednost AS i SD
2
from i to argumenti su granice grafikona na x-osi
Slika 6.3: Normalna distribucija visina
Funkcija density računa gustinu distribucije na osnovu empirijskih podataka. Ona procenjuje verovatnoću ishoda koristeći stvarne opservacije. Nasuprot tome, dnorm izračunava gustinu normalne distribucije pomoću teorijskih parametara, pokazujući nam idealan raspored podataka prema zadatim vrednostima.
Kada uporedimo krivu normalne distribucije sa našim histogramom, vidimo da ona ima sličan, ali pravilniji oblik i izraženiju strmost. Ova strmost nam govori da verovatnoća pronalaska ekstremnih vrednosti (recimo, visina ispod 140cm ili iznad 210cm) brzo opada kako se udaljavamo od centra distribucije. Oblik i širina normalne distribucije direktno zavise od njene standardne devijacije.
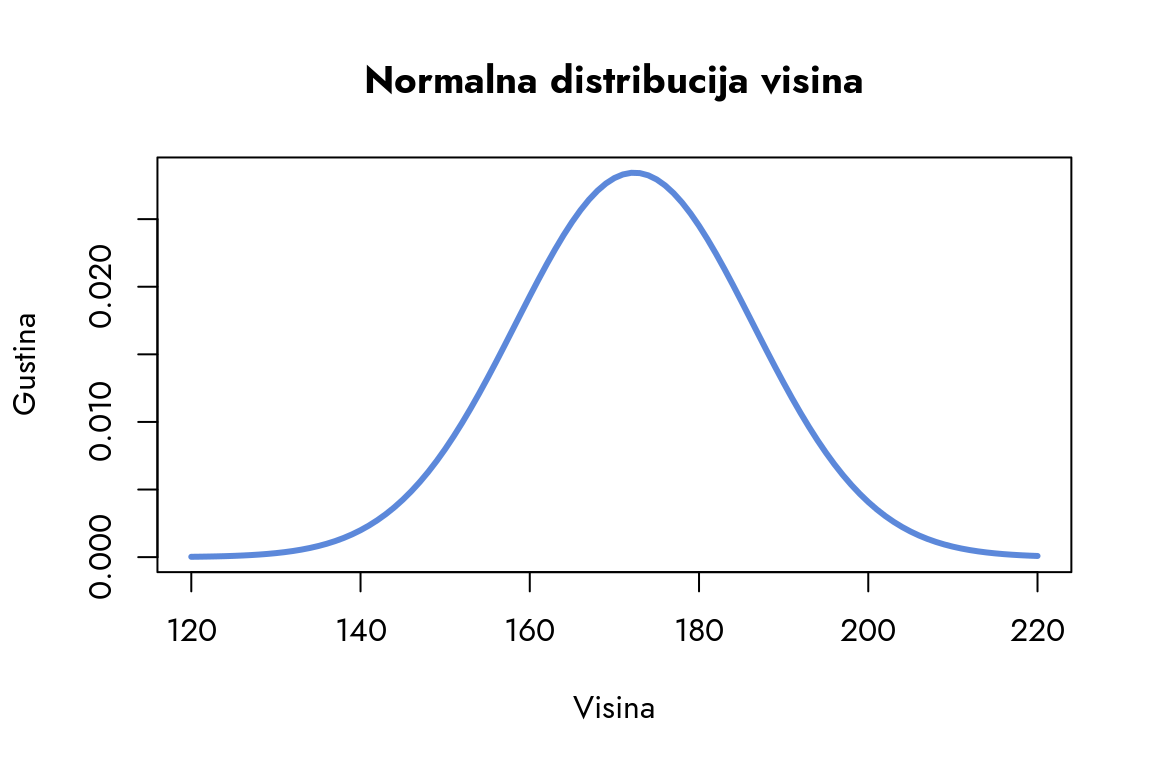
Da bismo jasnije videli kako standardna devijacija oblikuje distribuciju, pogledajmo kako bi izgledala kada bismo je udvostručili.
1.5*sd_visina - povećava standardnu devijaciju za 50%
2
from i to argumenti su granice grafikona na x-osi
Slika 6.4: Normalna distribucija visina sa povećanom standardnom devijacijom
Sada uočavamo da je distribucija manje strma i šira. Kao posledica toga, ekstremnije vrednosti, poput visine od 140cm, postaju verovatnije nego na prethodnom grafikonu. Ova promena ilustruje kako povećanje standardne devijacije utiče na oblik normalne distribucije, čineći je „razvučenijom“ i manje koncentrisanom oko srednje vrednosti.
NoteStandardna devijacija i preciznost
Od svih koncepata deskriptivne statistike, standardna devijacija je često najteža za intuitivno razumevanje. Interesantno je da Gaus, prilikom formulisanja matematičkog modela normalne distribucije, nije koristio standardnu devijaciju. Umesto toga, uveo je koncept preciznosti.
Razmislimo o tome: Gaus je svoj rad fokusirao na analizu grešaka merenja. U tom okviru, veća preciznost znači strmiju i užu normalnu distribuciju, jer je manja verovatnoća značajnog odstupanja od tačne vrednosti. Suprotno tome, manja preciznost daje širu distribuciju, što odražava veću verovatnoću različitih grešaka merenja.
U matematičkom smislu, preciznost je definisana kao \(p = \frac{1}{\sigma^2}\), što direktno pokazuje inverzni odnos sa varijansom.
Hajde da izračunamo preciznost za oba prethodna primera i vidimo šta nam brojevi govore.
Prikaži kod
preciznost1 =1/(sd_visina^2)preciznost2 =1/(1.5*sd_visina)^2cat("Preciznost u prvom primeru je: ", preciznost1, "\n")
Preciznost u prvom primeru je: 0.01143237
Prikaži kod
cat("Preciznost u drugom primeru je:", preciznost2, "\n")
Preciznost u drugom primeru je: 0.005081055
Vidimo da je preciznost u prvom slučaju 0.01, a u drugom 0.005, što pokazuje da se preciznost dvostruko smanjila u drugom primeru.
Iako nećemo dalje koristiti koncept preciznosti u ovom kursu, bitno je razumeti da standardna devijacija predstavlja recipročnu vrednost preciznosti. Ovaj odnos nam pruža jasan uvid - povećanje standardne devijacije direktno znači smanjenje preciznosti merenja, i obrnuto.
6.1 Zašto je normalna distribucija bitna?
Vratimo se na Gausov primer merenja greške pri posmatranju astronomskih objekata. Ako znamo da greška ima normalnu distribuciju, možemo izračunati verovatnoću pojave značajne greške. Šta to konkretno znači? To znači da možemo precizno odrediti verovatnoću da će se tokom istraživanja pojaviti greška koja može bitno uticati na naše zaključke. Drugim rečima, možemo kvantifikovati rizik da naši rezultati budu pogrešni.
Zar ne bismo želeli da taj rizik eliminišemo? U nauci to nije moguće zbog inherentnih ograničenja mernih instrumenata i činjenice da radimo sa uzorcima, a ne sa celom populacijom. Rizik greške je neizbežan, ali normalna distribucija nam pruža moćan alat za njegovu preciznu kvantifikaciju i opis.
Matematički gledano, normalna distribucija (kao i svaka druga distribucija verovatnoće) je funkcija. Kada u nju uvrstimo neku vrednost (u našem slučaju aritmetičku sredinu uzorka), ona nam vraća verovatnoću pojavljivanja te vrednosti u populaciji koja je definisana parametrima - aritmetičkom sredinom i varijansom.
Konkretnije, normalna distribucija nam daje \(p(\overline{X}|\mu, \sigma)\) - verovatnoću da ćemo iz populacije sa aritmetičkom sredinom \(\mu\) i standardnom devijacijom \(\sigma\) dobiti uzorak čija je aritmetička sredina \(\overline{X}\). Elegantno i precizno, zar ne?
Pažnja, uznemirujući sadržaj!
Normalna distribucija je vizuelno jednostavna, ali matematički složena funkcija.
Međutim, njen suštinski važan aspekt, koji joj daje prepoznatljivi oblik zvona je:
\[\frac{(\overline{X}-\mu)^2}{\sigma}\]
Što je opservacija dalja od aritmetičke sredine u odnosu na standardnu devijaciju, to je manja verovatnoća njenog pojavljivanja. Ovaj odnos nije linearan - grafikon normalne distribucije nije nacrtan pravim linijama već eksponencijalnom krivom, gde pad verovatnoće određuje kvadrat odstupanja i standardna devijacija.
Ovo merenje odstupanja od aritmetičke sredine pomoću standardne devijacije nije nam nepoznato. Sreli smo ga već kod normalizacije podataka i formiranja Z-skorova.
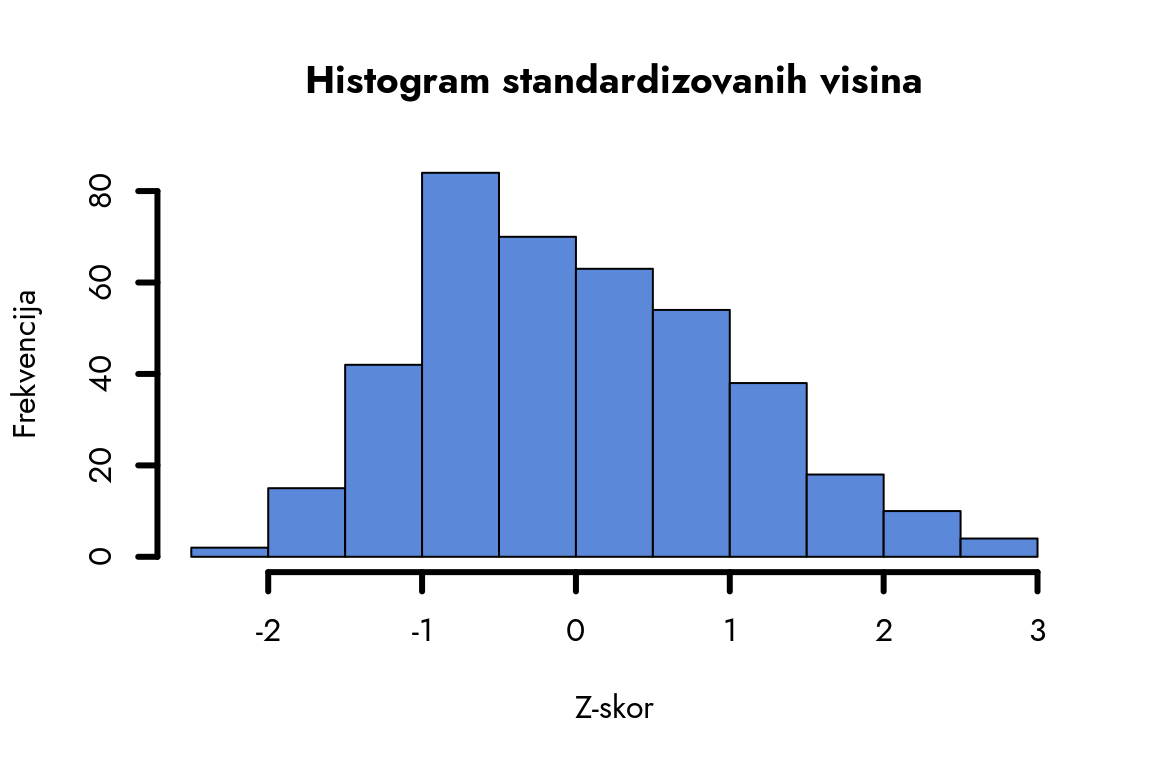
Primenimo sada naše prethodno znanje i pogledajmo kako izgleda normalna distribucija standardizovanih visina.
Slika 6.5: Normalna distribucija standardizovanih visina
Aritmetička sredina standardizovanih visina je 0, a standardna devijacija 1. Ovo nije slučajnost - to je direktna posledica matematičke definicije standardizacije, gde od svake vrednosti oduzimamo aritmetičku sredinu i delimo je standardnom devijacijom. Kada pogledamo detaljnije, uočavamo da raspored podataka nije savršeno simetričan i da je blago pomeren ulevo, sa centrom između 0 i -1. Ovo je sasvim očekivano - empirijske distribucije retko kada pokazuju matematički savršen normalan oblik, ali normalna distribucija i dalje ostaje izvanredan model za opisivanje prirodne tendencije podataka da se grupišu oko centralne vrednosti, sa postepenim opadanjem verovatnoće prema krajevima distribucije.
Izračunajmo sada konkretnu verovatnoću da se ispitanik nalazi u intervalu od jedne standardne devijacije oko aritmetičke sredine. To možemo uraditi na sledeći način:
Prikaži kod
mean(Z >-1& Z <1)
1
Izračunavanje verovatnoće da je Z-skor između -1 i 1
[1] 0.6775
Ovaj izraz u R-u može delovati kompleksno: tražimo verovatnoću, a koristimo aritmetičku sredinu? Šta se zapravo dešava? R prolazi kroz sve Z-skorove i proverava koji su između -1 i 1. Svaki skor koji zadovoljava ovaj uslov označava sa 1, a ostale sa 0. Zatim deli zbir jedinica sa ukupnim brojem opservacija. Rezultat je upravo ono što nam treba - verovatnoća da opservacija pripada zadatom intervalu, izračunata kao relativna frekvencija.
Dakle, verovatnoća da visina nekog ispitanika odstupa najviše jednu standardnu devijaciju od aritmetičke sredine iznosi 67.7%. To znači da se oko dve trećine svih ispitanika nalazi unutar jedne standardne devijacije od proseka. Ovaj raspon definiše tipične visine u našem uzorku.
Šta se dešava kada proširimo „komšiluk“ na 2 standardne devijacije?
[1] 0.96
Izračunavanje verovatnoće da je Z-skor između -2 i 2
Vidimo da je to približno 96% svih vrednosti. Samo 4% opservacija je izvan tog intervala.
Šta se dešava kada proširimo „komšiluk“ na 3 standardne devijacije?
[1] 1
Izračunavanje verovatnoće da je Z-skor između -3 i 3
Sve vrednosti (100%) nalaze se unutar 3 standardne devijacije od aritmetičke sredine. Nema opservacija koje bi bile udaljenije od tog intervala.
Standardizovana udaljenost od aritmetičke sredine nam omogućava da precizno odredimo šta je tipično za uzorak, a šta možemo smatrati retkim ili ekstremnim.
Kada se vratimo na Gausov rad o greškama merenja, ovo ima praktičnu primenu - 96% svih izvršenih merenja imaće grešku manju od 2 standardne devijacije. Poznavanjem standardne devijacije merenja procenjujemo da li je prihvatljivo da 96% grešaka bude u tom rasponu. Pri tome prihvatamo činjenicu da će 4% grešaka biti veće od 2 standardne devijacije, što je podsetnik da su retke, ali značajne greške neizbežne.
Jedna od elegantnih karakteristika normalne distribucije je da kod podataka koji je prate, raspored Z-skorova sledi jednostavno numeričko pravilo: 68-95-99.7.
68% svih Z-skorova nalazi se u intervalu od -1 do 1
95% svih Z-skorova je u rasponu od -2 do 2
99.7% svih Z-skorova obuhvaćeno je intervalom od -3 do 3
seq(-4, 4, length=1000) generiše 1000 vrednosti između -4 i 4
2
Kreiranje normalne distribucije vrednosti između -4 i 4
3
Crtannje krive normalne distribucije
4
Dodajemo osenčenje/obojene oblasti koje odgovaraju intervalima od -1 do 1, -2 do 2 i -3 do 3
5
Dodajemo vertikalne linije koje označavaju granice intervala
6
Dodajemo legendu koja objašnjava boje i linije na grafikonu
Slika 6.6: Pravilo 3 sigme
Ovo pravilo poznaje se kao empirijsko pravilo ili pravilo tri sigme. Iako nije univerzalno primenljivo, daje nam moćan alat za procenu verovatnoće odstupanja opservacija od aritmetičke sredine.
Distribucija Z-skorova koju ovde opisujemo naziva se Z-distribucija ili standardizovana normalna distribucija. Njena široka primena dolazi iz činjenice da x-osa nije vezana za konkretne jedinice mere ili veličine opservacija sa kojima radimo. Ovo svojstvo omogućava nam da direktno poredimo različite skupove podataka.
No, pravi potencijal Z-distribucije u statističkom zaključivanju otkriva se kada umesto distribucije podataka razmotrimo distribuciju aritmetičkih sredina uzoraka. Ovo je složen koncept, ali možemo ga ilustrovati kroz jedan hipotetički primer.
6.2 Šta bi bilo kada bi bilo?
Vratimo se na primer sa primanjima građana. Radili smo sa podacima o primanjima ispitanika, ali hajde da se vratimo u domen malog sveta i razmotrimo kakva bi mogla biti primanja građana Srbije. Nemamo konkretne podatke pred sobom i krećemo se u domenu pretpostavki. Recimo da smo optimistični i pretpostavljamo da su prosečna primanja građana Srbije 1000€. Ne govorimo o uzorku, već o populaciji - celokupnom radno aktivnom stanovništvu.
Kako formalno zapisujemo ovu pretpostavku?
\[
\mu_X = 1000
\]
Na levoj strani je nepoznati parametar populacije, odnosno aritmetička sredina varijable \(X\) na nivou populacije (prosečna primanja građana Srbije). Na desnoj strani je naša optimistična pretpostavka. Budući da su parametri uvek nepoznati, ovaj znak jednakosti izražava pretpostavku o mogućoj vrednosti parametra \(\mu_X\).
U takvom scenariju, šta možemo očekivati ako sprovedemo anketno istraživanje na uzorku i pitamo ispitanike o njihovim primanjima? Slično Gausovom iskustvu, ne možemo očekivati da će aritmetička sredina uzorka biti precizno 1000€. Razlog je jednostavan - svaki uzorak, bez obzira na njegov kvalitet, predstavlja samo segment populacije i nosi nepotpune informacije o njoj.
Preciznije, govorimo o varijabilitetu uzorka. Zamislite uzorak kao rezultat izvlačenja loto loptica - možda nam se u uzorku nađu pretežno siromašniji građani, ili nam se nekoliko milionera slučajno pojavi u podacima. Nemamo kontrolu nad ovim procesom, i sasvim je normalno očekivati da prosek našeg uzorka neće biti identičan stvarnom proseku populacije. Ako bismo ovo preveli na jezik prirodnih nauka, rekli bismo da prosečna primanja koja dobijemo u uzorku sadrže grešku merenja u odnosu na prosek populacije.
Kako analizirati ove greške? Kako proceniti da li smo u uzorku pronašli mala ili velika odstupanja od proseka populacije? Odgovor leži u specifičnoj vrsti Z-distribucije koja se zove distribucija aritmetičkih sredina uzoraka.
6.3 Distribucija aritmetičkih sredina uzoraka
Sagledajmo situaciju: zamislili smo populaciju sa aritmetičkom sredinom od 1000€, odnosno \(\mu_X = 1000\). Kada iz te populacije (npr. radno stanovništvo Srbije) uzmemo uzorak od 60 ispitanika i pitamo ih o njihovim primanjima, izračunavamo aritmetičku sredinu uzorka \(\overline{X}\).
Simulirajmo ovaj proces. U ovom primeru, pretpostavićemo da je standardna devijacija populacije \(\sigma=600\). U realnim istraživanjima ova vrednost nam nije poznata, ali nam je potrebna za simulaciju.
set.seed(12345) - omogućava nam da reprodukujemo isti rezultat u slučaju da želimo da ponovimo eksperiment.
2
rnorm(N,mi,sigma) - generiše nam 100 slučajnih brojeva iz normalne distribucije sa aritmetičkom sredinom 1000 i standardnom devijacijom 400.
Aritmetička sredina uzorka je: 1117.109
Dobijamo \(\overline{X}=1117.109\), aritmetičku sredinu uzorka koja je veća od aritmetičke sredine populacije. Zbog čega? Zbog greške merenja aritmetičke sredine na osnovu uzorka. Budući da uzorak ne sadrži sve informacije o populaciji, broj koji dobijemo ne može potpuno tačno opisati aritmetičku sredinu populacije, već neminovno dolazi do odstupanja.
Hajde da izračunamo to odstupanje:
Prikaži kod
odstupanje = AS - micat("Odstupanje je: ", odstupanje)
Odstupanje je: 117.1094
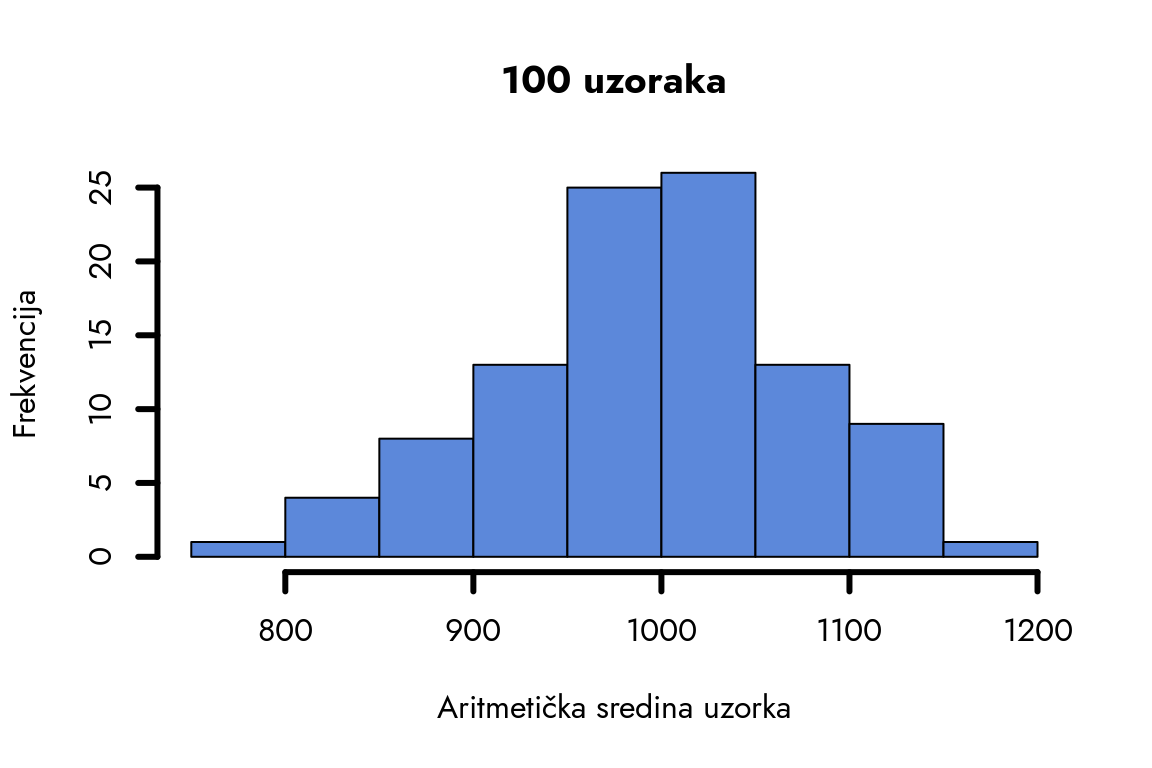
Da li je ovo odstupanje značajno? U ovom trenutku ne možemo dati precizan odgovor. Simulirajmo ovaj proces 100 puta da bismo razumeli distribuciju mogućih aritmetičkih sredina uzoraka koje bismo mogli dobiti u realnom istraživanju sa istim parametrima populacije.
k = 100 - broj uzoraka koje želimo da simuliramo
sredine_uzoraka = c() - pravimo prazan vektor koji će sadržati sredine uzoraka
for (i in 1:k) - petlja koja će se izvršiti 100 puta. U programiranju, petlje sadrže niz instrukcija koje se izvršavaju više put. U ovom slučaju izvršićemo tri naredbe 100 puta.
uzorak = rnorm(N,mi,sigma) - pravimo uzorak od 100 slučajnih brojeva iz normalne distribucije sa aritmetičkom sredinom 1000 i standardnom devijacijom 400. Potom računamo aritmetičku sredinu tog uzorka.
sredine_uzoraka = c(sredine_uzoraka,AS) - pridružujemo sredinu uzorka vektoru sredine_uzoraka. Funkcija c() spaja dve vrednosti u jednu.
Hajde da vidimo nekoliko vrednosti sredine_uzoraka.
Histogram jasno pokazuje približno normalnu distribuciju. Najveća koncentracija aritmetičkih sredina uzoraka nalazi se oko vrednosti 1000, dok njihova učestalost postepeno opada ka krajevima distribucije. Tipičan uzorak će dati rezultat blizak aritmetičkoj sredini populacije, mada su moguća i značajnija odstupanja.
Važno je naglasiti da je ovo neprekidna (kontinuirana) distribucija, što znači da posmatramo intervale vrednosti, jer je verovatnoća pojave bilo koje pojedinačne vrednosti jednaka nuli.
Otkriće da aritmetičke sredine uzoraka formiraju normalnu distribuciju predstavlja temelj statističkog zaključivanja. U teoriji verovatnoće, ovo fundamentalno svojstvo poznato je kao centralna granična teorema.
TipŠta je centralna granična teorema?
Ova teorema je kamen temeljac matematičke statistike. Iako nećemo ulaziti u njen formalni matematički zapis, možemo je objasniti jednostavno i direktno.
Počnimo ovako: imamo \(X_1, X_2, \ldots, X_k\) nezavisnih slučajnih uzoraka veličine \(n\) iz iste populacije. Ta populacija ima aritmetičku sredinu \(\mu\) i konačnu varijansu \(\sigma^2\). Sa \(\overline{X}_k\) označavamo aritmetičku sredinu bilo kog od tih uzoraka.
Centralna granična teorema je jednostavna ali moćna: kad \(n\) raste, distribucija aritmetičkih sredina \(\overline{X}_k\) teži ka standardizovanoj normalnoj raspodeli. Matematički to znači da standardizovana vrednost svake aritmetičke sredine \(Z = \frac{\overline{X}_k - \mu}{\sigma / \sqrt{n}}\) prati normalnu distribuciju kada \(n\) teži beskonačnosti.
Šta ovo znači u praksi? Na velikim uzorcima ne vidimo ekstremna odstupanja aritmetičkih sredina. Odstupanja se grupišu oko nule i prate predvidljiv obrazac koji definišu zakoni verovatnoće. To nam omogućava da preciznije procenimo parametre populacije i radimo pouzdanije statističke analize.
Praktična primena ove teoreme je direktna i suštinska. Ona nam pruža matematički okvir za razumevanje veze između našeg uzorka i populacije koju istražujemo. To je osnovni alat statističkog zaključivanja koji nam omogućava da precizno kvantifikujemo neizvesnost naših procena.
Zahvaljujući ovoj teoremi možemo izračunati teorijsku distribuciju aritmetičkih sredina uzoraka iz određene populacije. Za to nam je neophodna informacija o aritmetičkoj sredini populacije, ali i još jedan ključni element. Taj element koji nedostaje naziva se standardna greška aritmetičke sredine uzorka.
ImportantZakon velikih brojeva
Zakon velikih brojeva je jedan od najčešće pogrešno interpretiranih koncepata u statistici. Kada čujete da će se nešto „sigurno desiti“ ili da nešto možemo „100% očekivati“ na veoma velikom uzorku „jer važi zakon velikih brojeva“, znajte da je to potpuno pogrešno tumačenje i da osoba koja to govori ne razume osnovne principe statistike.
Zakon velikih brojeva je direktna posledica centralne granične teoreme. On nam govori da se na velikom uzorku aritmetička sredina distribucije približava aritmetičkoj sredini populacije. Preciznije, ako uzmemo sve više i više uzoraka, aritmetička sredina aritmetičkih sredina tih uzoraka će konvergirati ka aritmetičkoj sredini populacije.
Zašto je to tako? Mehanizam je jednostavan - kada izvlačimo veliki broj uzoraka iz populacije, individualna odstupanja aritmetičkih sredina od prave vrednosti se međusobno poništavaju. Konačan prosek tih aritmetičkih sredina prirodno teži ka aritmetičkoj sredini populacije.
Ključno je razumeti da to ne znači da će bilo koji pojedinačni uzorak biti savršeno tačan ili imati nulto odstupanje od prave vrednosti. To je matematički nemoguće - nijedan uzorak, bez obzira na broj opservacija i veličinu, ne može dati apsolutno preciznu vrednost aritmetičke sredine populacije. Imajte ovo na umu kada se susretnete sa pozivanjem na zakon velikih brojeva.
6.4 Standardna greška
Standardna greška je standardna devijacija distribucije aritmetičkih sredina uzoraka. Ona pokazuje koliko varijacija u proseku možemo očekivati kada računamo aritmetičke sredine na uzorcima jednake veličine koje uzimamo iz iste populacije.
Drugim rečima, ona predstavlja grešku merenja kada procenjujemo aritmetičku sredinu uzorka. Standardna greška nam otkriva preciznost našeg izračunavanja aritmetičke sredine uzorka. Ovaj pojam smo sreli kod centralne granične teoreme i izražava se sledećom formulom:
Kao što vidite standardna greška zavisi od dva faktora:
Standardne devijacije varijable na nivou populacije
Veličine uzorka
Standardnu devijaciju populacije ne možemo kontrolisati - ona je deo velikog sveta. Na primer, da li su zarade u društvu relativno ujednačene (mali varijabilitet) ili postoje ekstremne razlike (veliki varijabilitet), to ne zavisi od nas već od karakteristika društva koje proučavamo. Slično tome, raspon visina u populaciji je biološka činjenica na koju ne možemo uticati.
Ono što je pod našom kontrolom jeste veličina uzorka. Veći uzorak znači manju standardnu grešku. Međutim, važno je razumeti da ovaj odnos nije linearan - ne možete jednostavnim udvostručavanjem uzorka prepoloviti grešku merenja. Matematički gledano, standardna greška teži nuli tek kada veličina uzorka dostigne veličinu populacije. Ovo je logično jer u tom slučaju ne bismo više radili sa uzorkom, već bismo imali potpune informacije o celoj populaciji.
Standardna greška definiše oblik distribucije aritmetičkih sredina uzoraka. Što je manja standardna greška, to je distribucija sredina uzoraka uža i viša, što direktno ukazuje na veću preciznost u proceni aritmetičke sredine uzorka.
Međutim, postavlja se praktično pitanje: kako izračunati standardnu grešku kada ne znamo standardnu devijaciju (tj. varijansu) populacije? U odsustvu informacija o populaciji, logičan pristup je da koristimo standardnu devijaciju uzorka kao najbolju dostupnu ocenu standardne devijacije populacije.
\[
s_{\overline{X}} = \frac{s}{\sqrt{n}}
\]
Ova formula je u stvari ocena standardne devijacije populacije i ona je u skladu sa centralnom graničnom teoremom.
NoteZašto grešimo?
U statistici pojam greške nije indikator neispravnosti ili propusta. Greška predstavlja prirodne varijacije koje proizilaze iz procesa slučajnog uzorkovanja. Svi oblici neizvesnosti i nepotpunih informacija inherentnih uzorku čine statističku grešku. Možemo je posmatrati kao meru nepreciznosti koja neizbežno prati svako istraživanje zasnovano na uzorcima.
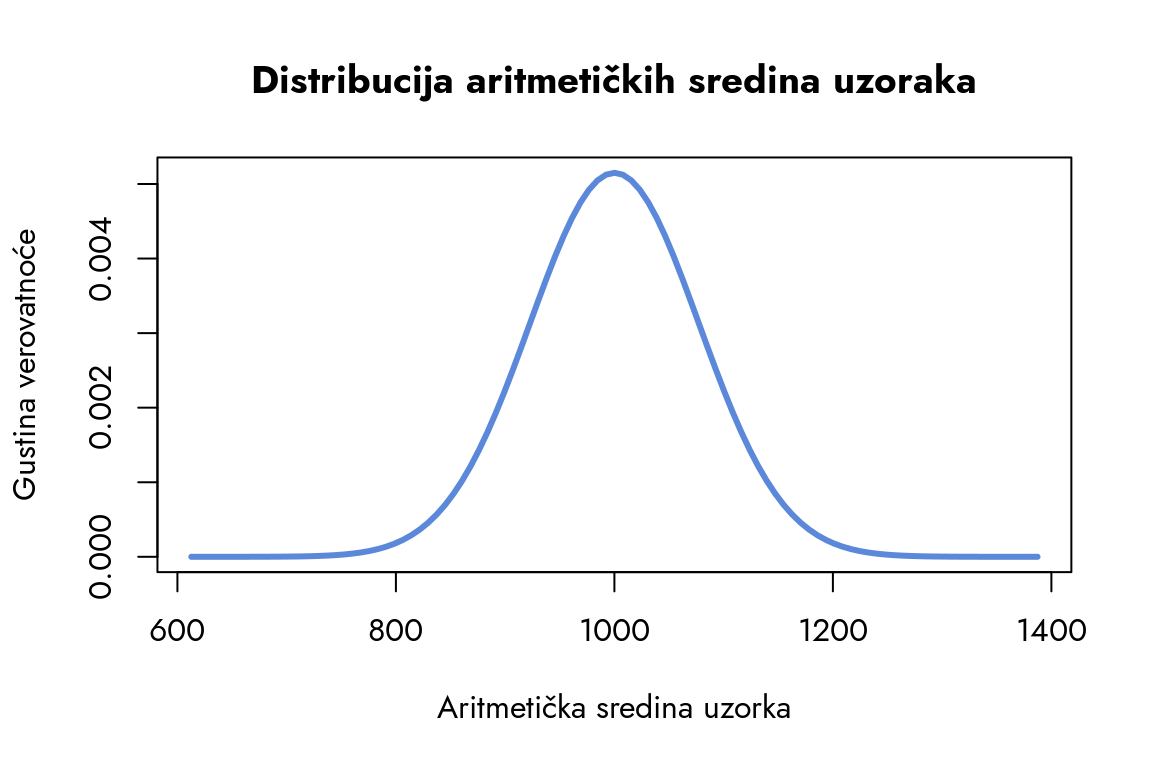
Vratimo se na konkretan primer sa primanjima građana. Definisali smo da je aritmetička sredina populacije 1000€, a standardna devijacija 600€. Radimo sa uzorkom od 60 ispitanika. Potrebno je da vizuelno predstavimo distribuciju aritmetičkih sredina uzoraka. Centar ove distribucije je na 1000€, a njena standardna devijacija je zapravo standardna greška. Prvi korak je izračunavanje te standardne greške.
sigma / sqrt(n) - izračunava se kao količnik standardne devijacije populacije i kvadratnog korena veličine uzorka.
Dakle, preciznost sa kojom možemo utvrditi koliko iznosi aritmetička sredina uzorka je 77.46€. Sada ćemo da iskoristimo ovu vrednost da nacrtamo liniju distribucije aritmetičkih sredina uzoraka.
Teorijska normalna distribucija čija je aritmetička sredina 1000 i standardna devijacija 40.
Slika 6.8: Distribucija aritmetičkih sredina uzoraka
Ova normalna distribucija pokazuje šta možemo očekivati kada sprovodimo istraživanje na uzorku iz populacije gde građani u proseku zarađuju 1000 evra, uz standardnu devijaciju od 600 evra. Na većini uzoraka iz ove populacije, prosečna zarada će se kretati između 800 i 1200 evra. Ovaj interval nam daje jasan matematički okvir za interpretaciju rezultata i pomaže nam da razumemo prirodnu varijabilnost koju srećemo u praksi.
Vratimo se sada na konkretne podatke koje smo analizirali u prvom poglavlju. Evo šta smo dobili:
Prikaži kod
podaci <-read.csv("https://gist.githubusercontent.com/atomashevic/492eaf9250b68a35557f224b20e8b310/raw/94329ddd24964e6a9fe0d392a6482d556aa2b54b/primanja.csv")AS <-mean(podaci$primanja)cat("Aritmetička sredina uzorka je: ", AS)
Aritmetička sredina uzorka je: 799.8
Aritmetička sredina našeg uzorka iznosi 799.8 evra. Pretpostavimo da je ovaj uzorak izvučen iz populacije čija je aritmetička sredina 1000 evra. Ova pretpostavka nam omogućava da izračunamo odstupanje i precizno kvantifikujemo grešku merenja.
Odstupanje je: -200.2
Aritmetička sredina uzorka je 200.2 evra manja od aritmetičke sredine populacije. Da bismo procenili značajnost ovog odstupanja, uporedićemo ga sa standardnom greškom koju smo već izračunali. Ovakvo odstupanje, izraženo u jedinicama standardne greške, predstavlja Z-skor aritmetičke sredine. Ovaj pristup nam omogućava da precizno kvantifikujemo odstupanje našeg uzorka od očekivane vrednosti.
Odnos odstupanja i standardne greške je: -2.584571
Naša aritmetička sredina uzorka odstupa 2.58 standardnih grešaka od aritmetičke sredine populacije. Setimo se pravila 3 sigme koje nam kaže da će 95% svih aritmetičkih sredina uzoraka iz date populacije biti unutar 2 standardne devijacije od aritmetičke sredine populacije. Naš rezultat od -2.58 standardnih devijacija je, dakle, veoma redak događaj koji zahteva pažljivu analizu.
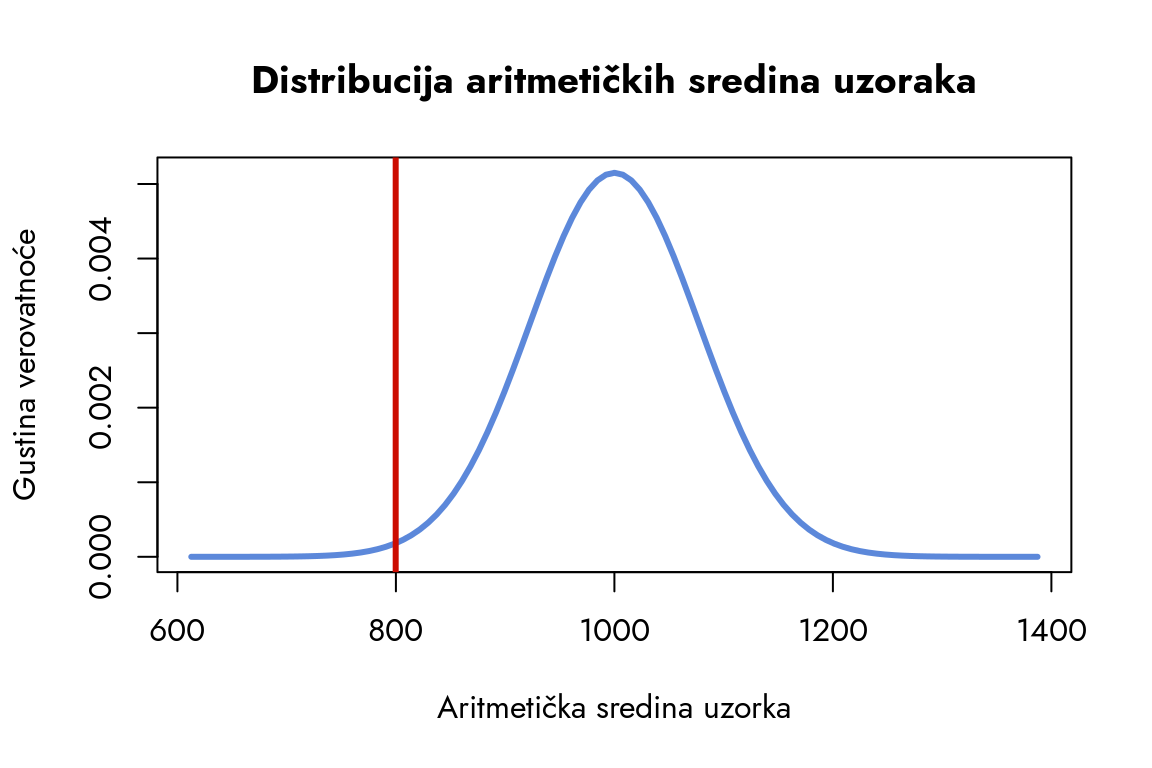
Da bismo bolje razumeli ovo odstupanje, prikažimo ga grafički. Na krivu distribucije aritmetičkih sredina dodaćemo vertikalnu liniju koja označava aritmetičku sredinu našeg uzorka. Ovakav prikaz nam omogućava da jasno vidimo koliko naš uzorak zaista odstupa od očekivane vrednosti i pruža nam jednostavan način da intuitivno shvatimo njegovu poziciju u odnosu na teorijsku distribuciju.
Ovo je teorijska normalna distribucija sa aritmetičkom sredinom 1000 i standardnom devijacijom 40. Ona predstavlja očekivanu raspodelu aritmetičkih sredina uzoraka.
2
Funkcija abline dodaje vertikalnu liniju na grafikon. Parametar v=AS postavlja liniju vertikalno na poziciju koja odgovara aritmetičkoj sredini našeg uzorka. Argument col="red" boji liniju u crveno, što je čini jasno vidljivom.
Slika 6.9: Distribucija aritmetičkih sredina uzoraka
Grafikon pokazuje da se aritmetička sredina našeg uzorka nalazi na samom kraju leve strane distribucije, u području gde gustina verovatnoće teži nuli. Ovo otvara zanimljivo pitanje - kako smo dobili uzorak koji je, prema teoriji, toliko malo verovatan da bi trebalo da bude praktično nemoguć? Ovaj neočekivani rezultat ukazuje na ozbiljan problem koji zahteva detaljnu analizu. U narednom poglavlju ćemo istražiti kako je moguće da naš uzorak toliko dramatično odstupa od teorijskih očekivanja.
6.5 Zadaci
CautionZadatak 1
Izračunajte uslovnu verovatnoću da je ispitanik viši od 180cm ako je muškarac i ako je žena. Šta nam razlike u tim verovatnoćama govore o odnosu visina muškaraca i žena?
CautionZadatak 2
Preuzmite podatke o primanjima iz datoteke primanja.csv. Iskoristite ove podatke da konstruišete teorijsku distribuciju aritmetičkih sredina uzoraka. Neka distribucija ima identičnu aritmetičku sredinu kao originalni podaci, a standardna greška neka bude jednaka standardnoj grešci uzorka iz podataka.
CautionZadatak 3 *
Nacrtajte grafikon koji prikazuje krive gustine visine za muškarce i žene. Za prvi grafikon koristite funkciju plot(density(...), col="#CC0C00FF"), a za drugi dodajte krivu koristeći lines(density(...), col="#5C88DAFF"). Dodajte legendu koja objašnjava koju liniju predstavlja koja grupa.
CautionZadatak 4 **
Ispitajte kako zakon velikih brojeva deluje u praksi. Napravite simulaciju sa 50 uzoraka veličine 100 iz normalne distribucije sa aritmetičkom sredinom 1000 i standardnom devijacijom 400. Za svaki uzorak izračunajte aritmetičku sredinu i prikažite njihov raspored histogramom. Ponovite postupak za 100, 500 i 1000 uzoraka.
Objasnite kako se menja aritmetička sredina svih uzoraka sa povećanjem broja uzoraka. Stavite rezultate u kontekst zakona velikih brojeva.
Konzola za rešavanje zadataka
Gauss, C.-F. (1823). Theoria combinationis observationum erroribus minimis obnoxiae. Henricus Dieterich.