U prethodnom poglavlju detaljno smo se upoznali sa regresionom analizom i opisali uticaj nezavisne varijable na zavisnu. Međutim, u mnogim istraživačkim situacijama nije uvek jasno koja varijabla treba da bude nezavisna, a koja zavisna. Za takve slučajeve postoji efikasan alat za istraživanje međusobnog odnosa dve kvantitativne varijable.
Krenimo od poznatog - proste linearne regresije. Razmotrimo jednostavan primer sa dve kvantitativne varijable. Istraživanje se fokusiralo na svakodnevne navike adolescenata koristeći podatke iz mobilnih uređaja. Prikupljanje ovakvih podataka zahteva metodološki precizan pristup. Da bi se izbegla narušavanja privatnosti, istraživači ispitanicima daju nove mobilne telefone sa instaliranim samo onim aplikacijama koje su predmet istraživanja. Ispitanici ne koriste svoje lične naloge. Uređaje koriste 10-30 dana, nakon čega ih vraćaju istraživačima.
Analiziraćemo podatke o korišćenju telefona tokom jednog dana od strane 80 ispitanika. Varijable su:
netflix: broj sati dnevno koje ispitanici provedu gledajući Netflix
koraci: broj koraka koje ispitanici pređu dnevno
Logično je pretpostaviti da su ove dve aktivnosti negativno povezane - teško je istovremeno gledati seriju i šetati. No, postavlja se suštinsko pitanje: koja aktivnost utiče na koju? Da li više vremena na Netflix-u rezultira manjom fizičkom aktivnošću, ili manja fizička aktivnost vodi ka dužem gledanju serija? Ovo je klasičan primer problema uzročnosti u statistici.
Pitanje uzroka i posledice ovde nije trivijalno. Možemo razmišljati u oba smera: vreme provedeno na Netflix-u moglo bi uticati na broj koraka - više gledanja znači manje vremena za kretanje. Istovremeno, niska fizička aktivnost može voditi ka većoj konzumaciji streaming sadržaja - kada smo neaktivni, verovatnije je da ćemo slobodno vreme ispuniti gledanjem serija.
Kako pristupiti ovom problemu? Kao i u prethodnom poglavlju, počećemo od vizuelne analize podataka.
Prikaži kod
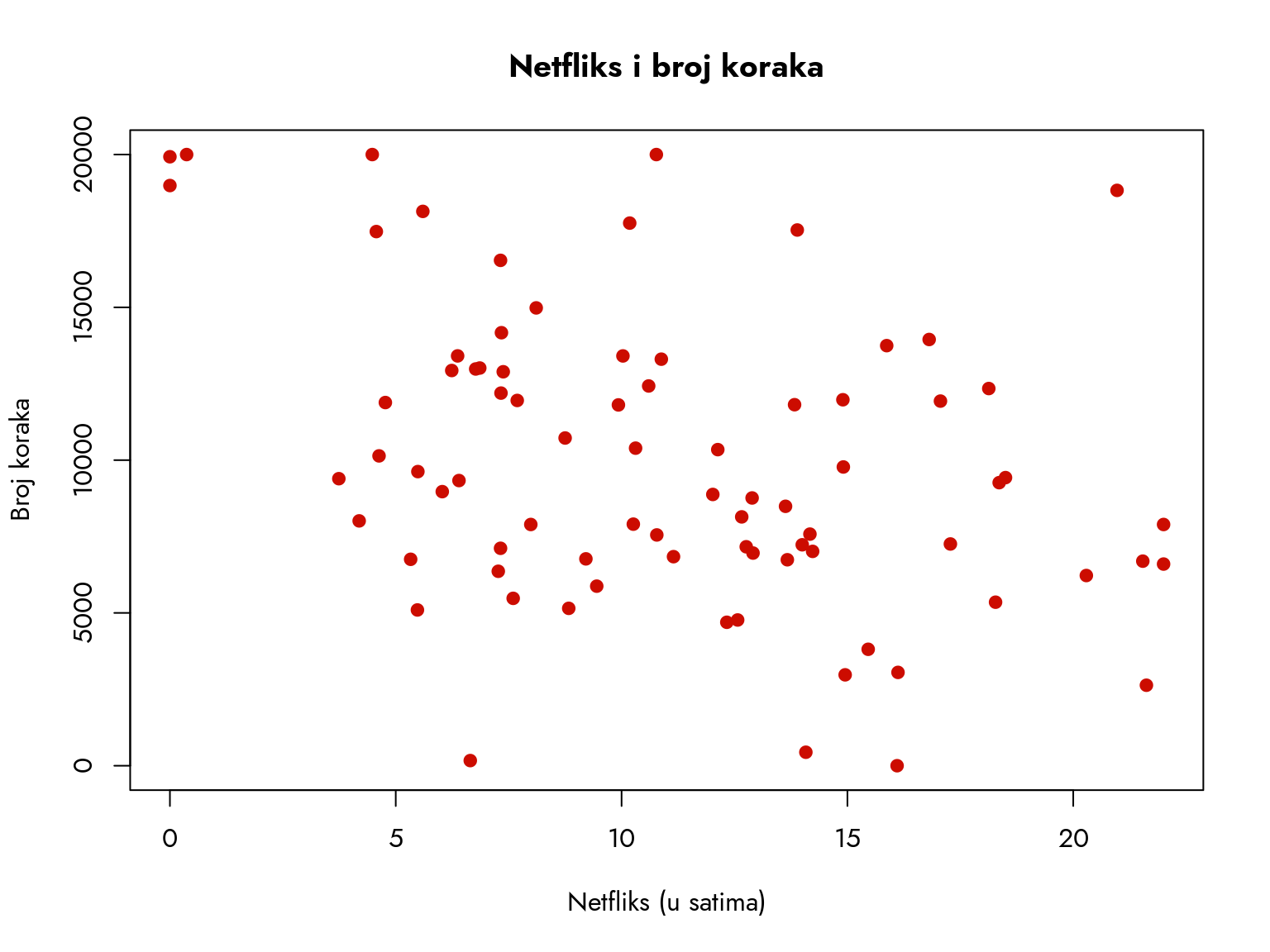
podaci <-read.csv("https://gist.githubusercontent.com/atomashevic/a08682e874ac33291538aa57091b5dac/raw/a62d76f267481158a49964c6736668a5feec5aa4/netflix-koraci.csv")par(family ="Jost")plot(podaci$netflix, podaci$koraci,xlab ="Netfliks (u satima)",ylab ="Broj koraka",main ="Netfliks i broj koraka",col ="#CC0C00FF",pch =19)
1
Učitavanje podataka iz CSV fajla
2
Kreiranje dijagrama raspršenosti
Slika 10.1: Dijagram raspršenosti. Netflix je na x-osi, a broj koraka na y-osi.
Dijagram raspršenosti nam pruža početni uvid u odnos između ove dve varijable. Jasno je vidljiva tendencija opadajuće linije trenda, što ukazuje na negativnu povezanost između vremena provedenog uz Netflix i broja pređenih koraka.
Za precizniju analizu ove veze, primenićemo regresionu analizu. Ispitaćemo kako vreme provedeno uz Netflix utiče na broj pređenih koraka. U R-u, ovu regresiju zapisujemo formulom: koraci ~ netflix.
Prikaži kod
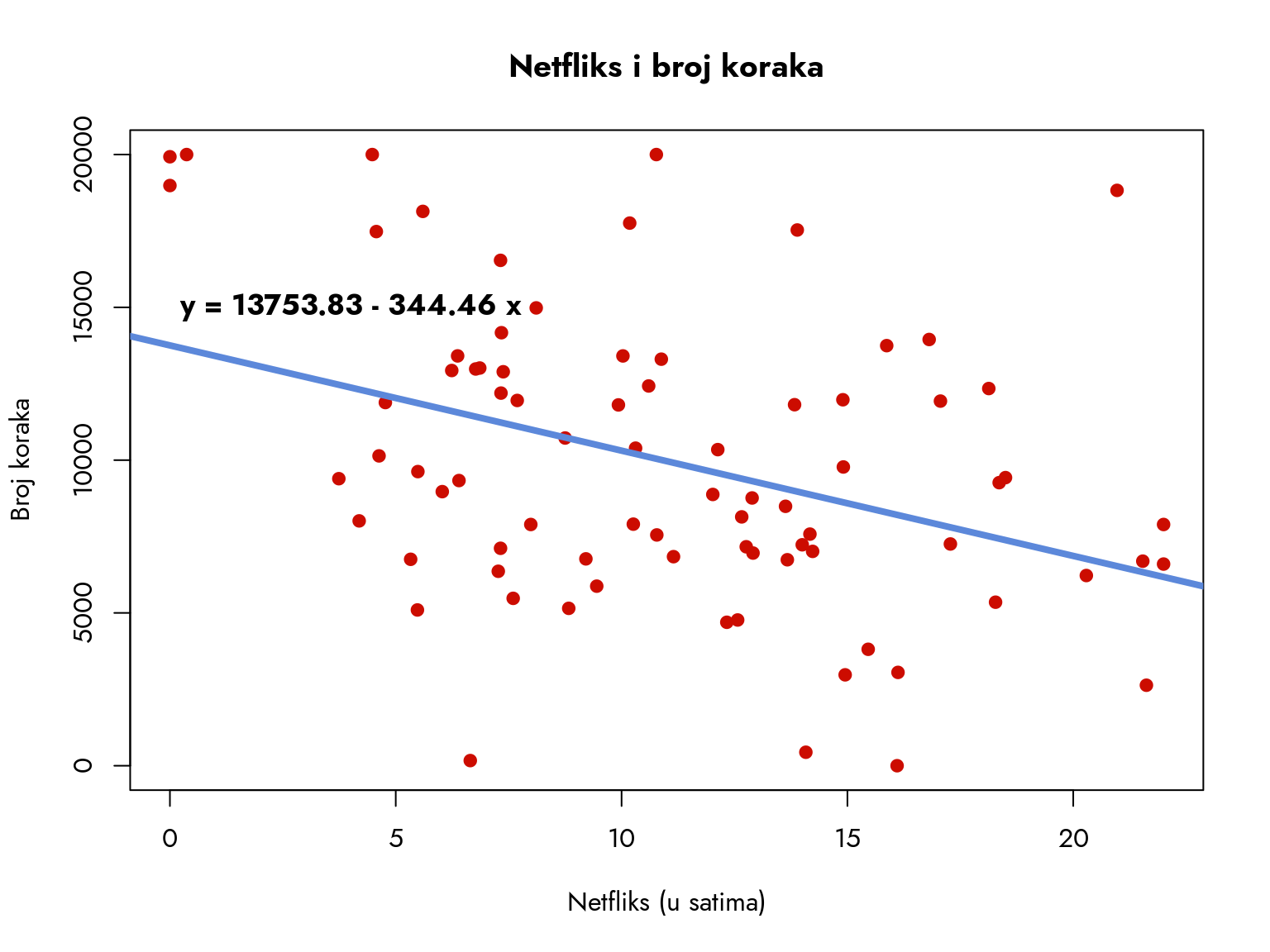
par(family ="Jost")regresija1 <-lm(koraci ~ netflix, data = podaci)plot(podaci$netflix, podaci$koraci,xlab ="Netfliks (u satima)",ylab ="Broj koraka",main ="Netfliks i broj koraka",col ="#CC0C00FF", pch =19)abline(regresija1, col ="#5C88DAFF", lwd =4)text(4, 15000,labels =paste("y =", round(regresija1$coefficients[1], 2),"-", abs(round(regresija1$coefficients[2], 2)),"x"),font =2, cex=1.1)
1
Konstruišemo regresioni model putem funkcije lm
2
Kreiramo dijagram raspršenosti
3
Dodajemo regresionu liniju sa koeficijentima iz objekta regresija1
Slika 10.2: Regresiona linija. Netfliks je na x-osi, a broj koraka na y-osi.
Kako razumeti ovaj rezultat? Koeficijent \(b_0\) iznosi približno 13753 koraka. To predstavlja vrednost \(Y\) kada je \(X\) jednako 0. U našem primeru, to znači da kada ispitanici uopšte ne gledaju Netflix, u proseku prelaze oko 13700 koraka.
Koeficijent \(b_1\) iznosi -344. Ovaj koeficijent prikazuje promenu u \(Y\) za jediničnu promenu u \(X\). Bitno je uočiti da je vrednost negativna. Konkretno, to znači da svaki dodatni sat proveden u gledanju Netflix-a smanjuje prosečan broj koraka za 344.
Umesto dalje analize ovog regresionog modela, fokusiraćemo se na inverzni odnos između ove dve varijable. Ispitaćemo regresionu liniju koja pokazuje kako broj koraka utiče na vreme provedeno u gledanju Netflix-a: netflix ~ koraci.
Prikaži kod
par(family ="Jost")regresija2 <-lm(netflix ~ koraci, data = podaci)plot(podaci$koraci, podaci$netflix,xlab ="Broj koraka",ylab ="Netfliks (u satima)",main ="Broj koraka i Netfliks",col ="#CC0C00FF", pch =19)abline(regresija2, col ="#5C88DAFF", lwd =4) text(5000, 17,labels =paste("y =", round(regresija2$coefficients[1], 2),"-", abs(round(regresija2$coefficients[2], 5)), "x"),font =2, cex=1.1)
Slika 10.3: Regresiona linija. Broj koraka je na x-osi, a Netfliks na y-osi.
Pogledajmo sada drugačiju interpretaciju regresionih koeficijenata. Koeficijent \(b_0\) iznosi 15.2 - ovo predstavlja vrednost \(Y\) kada je \(X\) jednako 0. U našem kontekstu, ako ispitanik ne napravi nijedan korak, očekujemo da će u proseku gledati 15.2 sati Netflix-a.
Koeficijent \(b_1\) je izuzetno mali, približno -0.00042. Praktično, to znači da svaki dodatni korak smanjuje vreme provedeno uz Netflix za 0.00042 sata. Prevedeno u sekunde, svaki dodatni korak smanjuje vreme gledanja za 1.5 sekunde.
Radi jasnijeg razumevanja, razmotrimo efekat na nivou od 1000 koraka. Za svakih 1000 dodatnih koraka, vreme provedeno uz Netflix se u proseku smanjuje za 0.42 sata.
Kada analiziramo međusobni odnos ove dve varijable, uočavamo sledeće:
Nagib regresione linije koja opisuje zavisnost broja sati Netflix-a od broja koraka iznosi -344.46
Nagib regresione linije koja opisuje zavisnost broja koraka od broja sati Netflix-a iznosi -0.00042
Ovde se prirodno nameće pitanje: kako bismo mogli da kombinujemo ova dva pokazatelja u jedinstveni indikator? Potrebna nam je mera koja će dati jasan odgovor na dva ključna pitanja:
Postoji li međusobna povezanost između ove dve varijable?
Ako postoji, kakav je njen smer i intenzitet?
Problem bismo mogli rešiti uzimanjem aritmetičke sredine dva regresiona koeficijenta. Ali tu nailazimo na prepreku - vrednosti koeficijenata se drastično razlikuju. Prvi je oko 100.000 puta veći od drugog. Zašto? Razlog je u različitim jedinicama mere. Dnevni broj koraka varira od 0 do 20.000, dok se sati gledanja Netflix-a kreću od 0 do 24. Zbog toga dobijamo značajno različite vrednosti regresionih koeficijenata, zavisno od izbora zavisne varijable.
Kako prevazići ovaj problem različitih vrednosti? Rešenje je u geometrijskoj sredini. Označimo prvi regresioni koeficijent kao \(b_{NK}\) (uticaj sati Netflix-a na broj koraka), a drugi kao \(b_{KN}\) (uticaj broja koraka na sate Netflix-a). Objedinjeni indikator njihovog međusobnog odnosa označićemo sa \(r\). Primenom geometrijske sredine dobijamo:
\[
r = \sqrt{b_{NK} \times b_{KN}}
\]
Implementacijom ove formule u R-u dobijamo sledeći rezultat:
Izdvajanje regresionog koeficijenta za netflix iz prvog modela
2
Izdvajanje regresionog koeficijenta za koraci iz drugog modela
3
Izračunavanje koeficijenta korelacije kao geometrijske sredine
Rezultat je: 0.3792
Šta nam ovaj rezultat govori? Kako da interpretiramo vrednost 0.3792? Odgovor na ova pitanja postaje jasan kada detaljnije razmotrimo pokazatelj koji smo izračunali. Ovaj pokazatelj je poznat kao Pirsonov koeficijent korelacije.
10.2 Pirsonov koeficijent korelacije
Pirsonov koeficijent korelacije je mera koja pokazuje intenzitet i smer povezanosti između dve kvantitativne varijable. Za razliku od regresije, koja analizira uticaj jedne varijable na drugu, korelacija se usmerava na međusobnu povezanost. Ne zanimaju nas objašnjenje i predviđanje, već merenje jačine veze između dva fenomena koje smo opisali kvantitativnim varijablama.
Suštinska odlika korelacije je njen intenzitet. Šta to konkretno znači? Pirsonov koeficijent korelacije uzima vrednosti od -1 do 1. Ako zanemarimo predznak, apsolutna vrednost koeficijenta (između 0 i 1) određuje intenzitet povezanosti. Vrednosti bliske 0 ukazuju na odsustvo povezanosti, dok vrednosti koje teže ka 1 ili -1 pokazuju snažnu vezu. Ovo vam verovatno zvuči poznato iz prethodnog poglavlja.
Pirsonov koeficijent predstavlja elegantno rešenje - standardizovanu verziju kovarijanse. Kod kovarijanse imamo samo jednu referentnu tačku: vrednosti oko 0 koje ukazuju na odsustvo doslednih zajedničkih promena (balansirana distribucija između 4 kvadranta). Problem nastaje jer za ostale vrednosti kovarijanse nemamo jasne smernice za tumačenje. Upravo zato nam je potreban koeficijent korelacije.
Pomoću kovarijanse i standardnih devijacija, kovarijansu možemo pretvoriti u standardizovanu meru koja ima jasnu interpretaciju. Korelacija zadržava predznak kovarijanse, što nam pokazuje smer veze - pozitivan ili negativan. Intenzitet veze određujemo prema apsolutnoj vrednosti koeficijenta korelacije:
\(|r| < 0.3\): slaba povezanost
\(0.3 \leq |r| \leq 0.7\): umerena povezanost
\(|r| > 0.7\): jaka povezanost
U našem primeru sa Netflix-om i brojem koraka, dobili smo r = -0.38. Kako ovo tumačimo?
Negativan predznak ukazuje na obrnutu vezu: više vremena na Netflix-u znači manje koraka
Vrednost 0.38 govori o umerenoj povezanosti
Ovaj rezultat je intuitivan: ljudi koji više vremena provode gledajući serije, manje se kreću. Umerena korelacija nam govori da postoji srednji nivo doslednosti između vremena provedenog na Netflix-u i fizičke aktivnosti. Ali šta zapravo znači ta „doslednost“ u ovom kontekstu?
Korelacija i regresija su komparativni metodi. Konzistentnost merimo poređenjem podataka unutar uzorka. Zamislite da nasumično izaberemo dva ispitanika:
Prvi gleda Netflix manje od proseka
Drugi gleda Netflix više od proseka
Kolika je verovatnoća da će prvi imati više koraka od proseka, a drugi manje? Što je ta verovatnoća veća, veza je konzistentnija i korelacija jača.
Slabe i umerene korelacije ukazuju na postojanje drugih faktora koji utiču na vezu. U našem primeru, to mogu biti pol ili starost ispitanika. Recimo, dvadesetogodišnjaci možda uspevaju da kombinuju natprosečno gledanje Netflix-a sa natprosečnom fizičkom aktivnošću, za razliku od starijih ispitanika. Ovakvi „skriveni“ faktori smanjuju korelaciju jer umanjuju direktnu vezu između gledanja Netflix-a i broja koraka.
NotePoreklo povezanosti između varijabli
Pri analizi povezanosti dve varijable, tri osnovna pristupa nam pomažu da razumemo njihov odnos:
Zajednički uzrok: Varijable mogu biti povezane zbog treće varijable koja utiče na obe. Na primer, starost utiče i na vreme provedeno na Netflix-u i na fizičku aktivnost. Ovo je čest scenario u društvenim naukama i glavni razlog zašto moramo biti oprezni pri interpretaciji korelacija.
Refleksivna veza: Ponekad su varijable povezane jer mere različite aspekte istog fenomena. Na primer, visina i težina su povezane jer obe mere fizičke karakteristike tela. U ovom slučaju, korelacija pokazuje koliko konzistentno merimo isti fenomen kroz različite indikatore.
Kauzalni lanac: Varijable mogu biti povezane jer su deo istog uzročno-posledičnog lanca. Na primer: vreme učenja → ocene → mogućnosti za zaposlenje. Bitno je napomenuti da sama korelacija ne ukazuje na direktnu uzročnost.
Razumevanje izvora povezanosti je ključno za preciznu interpretaciju korelacije i izbegavanje pogrešnih zaključaka. Svaka statistička analiza mora početi od jasnog razumevanja prirode veze između varijabli.
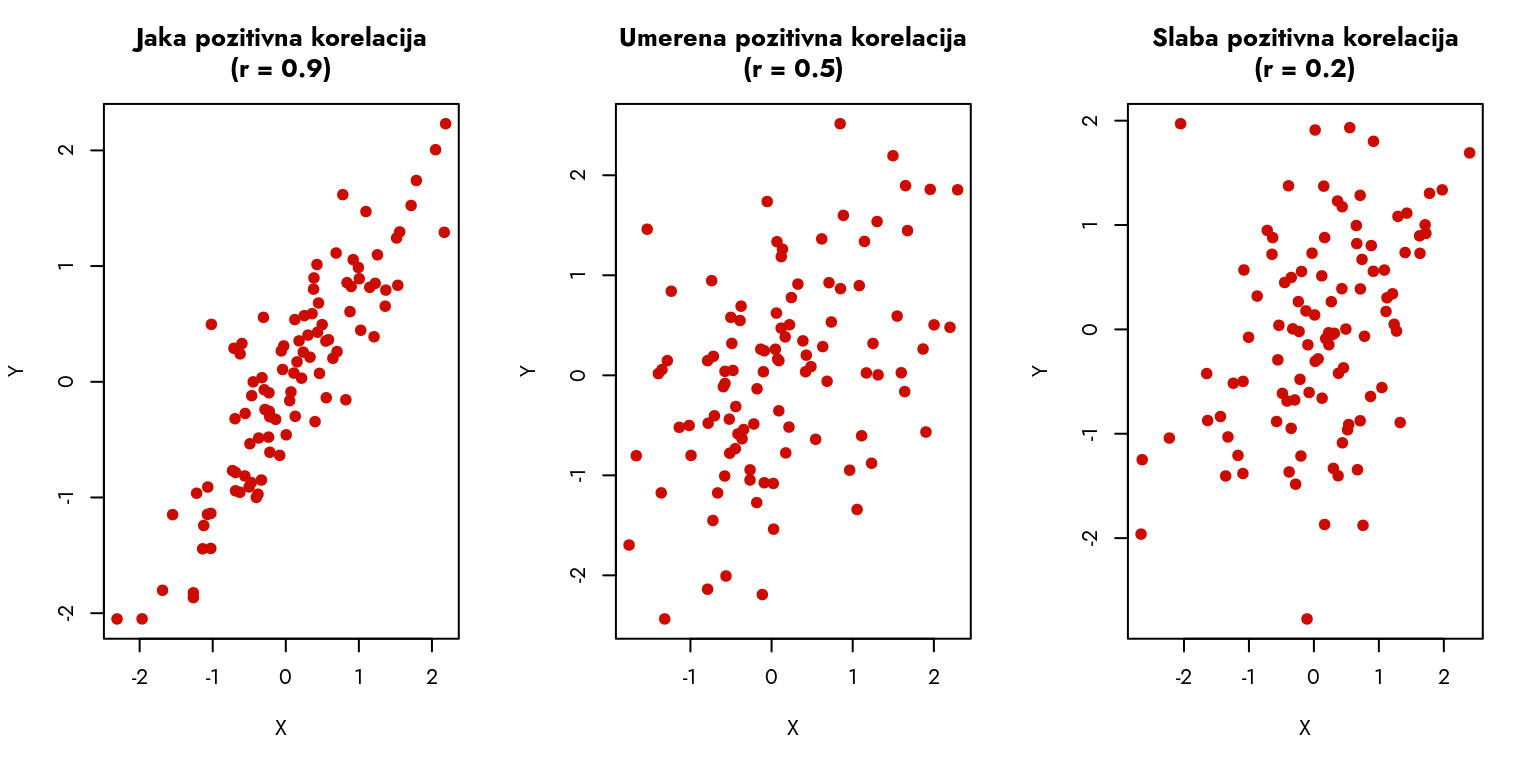
Da bismo bolje razumeli različite intenzitete korelacije, korisno je videti kako izgledaju dijagrami raspršenosti za različite vrednosti koeficijenta korelacije.
Slika 10.4: Primeri različitih nivoa korelacije
Gornji grafikoni prikazuju različite nivoe korelacije:
Jaka korelacija (|r| > 0.7): Tačke se grupišu oko jasne linije, formirajući izražen obrazac. Vrednost jedne varijable pouzdano predviđa vrednost druge varijable.
Umerena korelacija (0.3 ≤ |r| ≤ 0.7): Tačke prate prepoznatljiv trend, ali pokazuju veće odstupanje od linije. Povezanost je primetna, ali manje izražena nego kod jake korelacije.
Slaba korelacija (|r| < 0.3): Tačke pokazuju značajno rasipanje, bez jasnog obrasca. Veza između varijabli postoji, ali je slabog intenziteta.
Korelacija može biti i negativna - u tom slučaju dijagrami raspršenosti pokazuju opadajući trend. Intenzitet korelacije tumačimo na isti način, pri čemu negativan predznak ukazuje na inverznu vezu između varijabli. Do kraja poglavlja objasnićemo logiku iza graničnih vrednosti 0.7 i 0.3.
Vratimo se Pirsonovom koeficijentu korelacije. Prethodno smo ga definisali kao geometrijsku sredinu dva regresiona koeficijenta.
Hajde da vidimo šta će se desiti ako u formuli za \(r\) zamenimo regresione koeficijente njhovim formulama.
\[
r = \sqrt{\frac{S_{XY}}{S_{X}^2} \times \frac{S_{XY}}{S_{Y}^2}}
\]
Ako korenujemo ovu formulu, dobijamo:
\[
r = \frac{S_{XY}}{S_{X}S_{Y}}
\]
Ovo je formula za izračunavanje empirijskog Pirsonovog koeficijenta korelacije. Formula je praktična, sa jasnom interpretacijom.
Korelacija predstavlja količnik između:
kovarijanse - mere zajedničkog varijabiliteta dve varijable
proizvoda standardnih devijacija - mere individualnog varijabiliteta dve varijable
Jednostavnije rečeno, korelacija pokazuje koliko se dve varijable konzistentno menjaju zajedno u odnosu na njihove individualne promene. To je odnos zajedničkog varijabiliteta (kovarijansa) i individualnog varijabiliteta (standardne devijacije).
TipKo je bio Pirson?
Karl Pirson (eng. Karl Pearson, 1857-1936) je bio engleski matematičar i biostatističar koji je značajno doprineo razvoju moderne statistike. Kao jedan od osnivača statističke nauke, razvio je mnoge metode koje su i danas temelj statističke analize. Njegovo ime vezujemo za brojne koncepte, uključujući i Pirsonov koeficijent korelacije koji smo upravo objasnili.
Interesantna istorijska činjenica je da Pirson nije originalni tvorac ovog koeficijenta - on ga je učinio široko poznatim i primenjivim. Koncept je prvobitno razvio njegov mentor Frensis Galton krajem 19. veka. Galton je eksperimentisao sa terminologijom, krenuvši od pojma „reverzija“, preko „regresije“, da bi konačno usvojio termin „korelacija“. Sama matematička formula je još starija - prvi put se pojavila u radu francuskog fizičara Ogista Bravea.
Posebno je važno istaći da su ovi naučnici matematički dokazali da količnik kovarijanse i proizvoda standardnih devijacija uvek ima vrednost između -1 i 1. Iako Pirson nije originalni tvorac ovog koeficijenta, njegov doprinos leži u njegovoj sistematizaciji i širokoj primeni u praksi. Ovo je karakterističan primer kako u nauci često pripisujemo zasluge onima koji su uspešno implementirali i popularizovali određene metode, a ne nužno njihovim originalnim autorima.
Ova formula nam omogućava da analiziramo korelaciju između dve varijable nezavisno od regresionih modela. Upravo zato i pravimo razliku između regresije i korelacije. Regresija nam pokazuje uticaj jedne varijable na drugu, dok korelacija opisuje njihovu međusobnu povezanost. Međutim, sa čisto statističkog stanovišta, koeficijenti regresije i korelacije su veoma slični - oba predstavljaju odnose između kovarijanse i standardnih devijacija. Ključna razlika je u tome što regresija koristi odnos kovarijanse i standardne devijacije nezavisne varijable, dok korelacija uzima u obzir standardne devijacije obe varijable.
Vrednost koeficijenta \(r\) nam govori o smeru i intenzitetu veze između varijabli. Kada je \(r < 0\), govorimo o negativnoj korelaciji - varijable se menjaju u suprotnim smerovima, baš kao u našem Netflix primeru gde više sati gledanja serija prati manji broj koraka. Kada je \(r > 0\), imamo pozitivnu korelaciju - varijable se menjaju u istom smeru. Vrednosti \(r\) blizu 0 ukazuju na odsustvo linearne veze. Vrednosti 0.3 i 0.7 predstavljaju korisne granice za procenu jačine korelacije.
Bitno je istaći da se ovi zaključci odnose samo na naš uzorak. Za izvođenje zaključaka o vezi između varijabli na nivou cele populacije, neophodno je primeniti metode statističkog zaključivanja kroz testiranje hipoteza i intervale poverenja.
10.3 Test za Pirsonov koeficijent korelacije
Kao i u slučaju regresije, nakon što izračunamo koeficijent korelacije na nivou uzorka, potrebno je proveriti njegovu značajnost na nivou populacije. Nulta i alternativna hipoteza su:
\[H_0: \rho = 0\]\[H_1: \rho \neq 0\]
Pri čemu je \(\rho\) koeficijent korelacije dve varijable na nivou čitave populacije. Nulta hipoteza označava odsustvo korelacije u populaciji, dok alternativna potvrđuje da korelacija postoji na nivou populacije.
Za proveru ovih hipoteza koristimo \(t\) test, pri čemu t-statistika predstavlja odnos između koeficijenta korelacije izračunatog na nivou uzorka i standardne greške koeficijenta korelacije:
\[t = \frac{r}{\sqrt{\frac{1-r^2}{n-2}}}\]
Donji deo razlomka predstavlja standardnu grešku koeficijenta korelacije. Ova formula je slična formuli za \(t\) test u regresiji, s tim što je ovde standardna greška koeficijenta korelacije definisana kao:
\[s_r = \sqrt{\frac{1-r^2}{n-2}}\]
Standardna greška koeficijenta korelacije meri preciznost procene koeficijenta korelacije na nivou populacije. U slučaju korelacije, ovo izračunavanje je jednostavno. Što je koeficijent korelacije bliži maksimalnoj apsolutnoj vrednosti (1 ili -1), preciznost je veća, a greška manja. Kao i kod svake standardne greške, veći uzorak daje precizniju procenu.
Demonstriraćemo kako možemo izračunati standardnu grešku koeficijenta korelacije i testirati značajnost korelacije na nivou populacije koristeći R. Prvo ćemo ponovo izračunati koeficijent korelacije za naš uzorak koristeći formulu iz prethodnog odeljka.
Standardna greška je oko 0.1. Sada računamo \(t\) statistiku.
Prikaži kod
t = r / srcat("t-statistika je: ", round(t, 4), "\n")
1
Izračunavanje t-statistike.
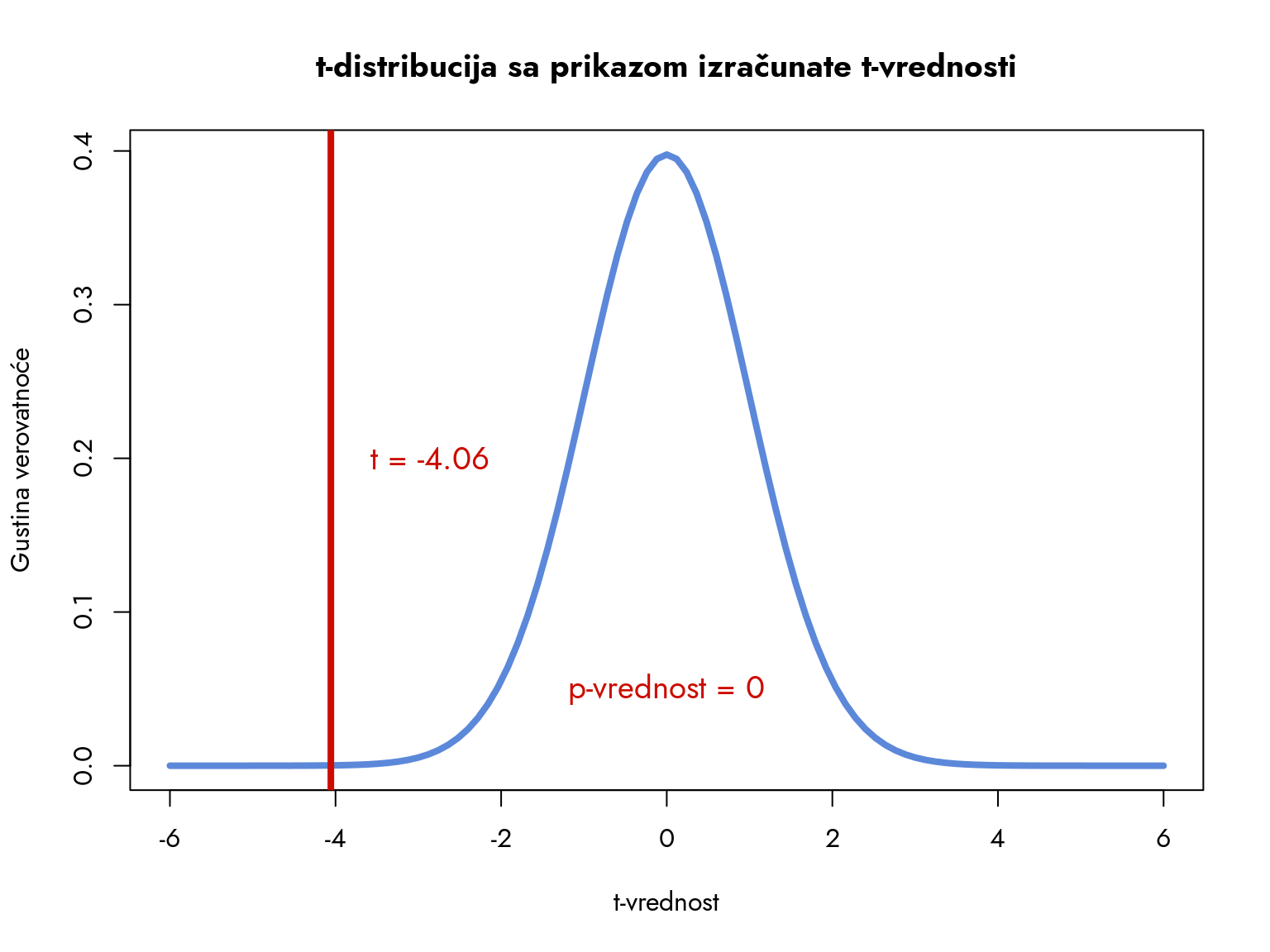
t-statistika je: -4.0565
Iz dosadašnjeg iskustva sa t-distribucijom, možemo pretpostaviti kakvom zaključku nas vodi vrednost statistike koja je približno \(-4\). Ovaj rezultat je ekstremno niži u odnosu na vrednost koju pretpostavlja nulta hipoteza (\(\rho = 0\)). Da bismo bili sigurni u naš zaključak, proverićemo p-vrednost.
Slika 10.5: Vizualizacija t-statistike. Crvena vertikalna linija označava izračunatu t-vrednost.
Izračunavanje stepena slobode za t-distribuciju.
Izračunavanje p-vrednosti.
P-vrednost je praktično nula, što znači da je korelacija statistički značajna. Odbacujemo \(H_0\) i zaključujemo da korelacija postoji u populaciji.
Važna napomena: korelaciju interpretiramo samo kada odbacimo \(H_0\). Ako je korelacija nije značajna (prihvatimo \(H_0\)), ne treba je interpretirati jer je verovatno proizvod slučajnosti u uzorku.
10.4 Interval poverenja za Pirsonov koeficijent korelacije
Interval poverenja za Pirsonov koeficijent korelacije je izuzetno koristan alat jer nam omogućava da preciznije zaključimo o intenzitetu korelacije.
Formula za interval poverenja ima standardni oblik:
\[
r \pm t_{\alpha/2} \times s_r
\]
U R-u to izgleda ovako.
Prikaži kod
alpha <-0.05t_alpha <-qt(1- alpha/2, df)donja_granica <- r - t_alpha * srgornja_granica <- r + t_alpha * srcat("Interval poverenja za koeficijent korelacije je: (", round(donja_granica, 4), ", ", round(gornja_granica, 4), ")\n")
1
Izračunavanje vrednosti \(t_{\alpha/2}\) za odgovarajući stepen slobode.
2
Izračunavanje donje i gornje granice intervala poverenja.
Vidimo da se interval poverenja kreće od -0.56 do -0.19. Na ovom nivou pouzdanosti možemo zaključiti da je korelacija u populaciji negativna i da varira od slabe do umerene. Ovaj interval nam jasno pokazuje da nije reč o snažnoj korelaciji između dve varijable.
R nam nudi elegantno rešenje za testiranje hipoteze o Pirsonovom koeficijentu korelacije i računanje intervala poverenja kroz funkciju cor.test. Jednom linijom koda dobijamo sve potrebne rezultate!
Prikaži kod
cor.test(podaci$netflix, podaci$koraci)
Pearson's product-moment correlation
data: podaci$netflix and podaci$koraci
t = -3.6189, df = 78, p-value = 0.0005234
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.5528280 -0.1739408
sample estimates:
cor
-0.3791668
Iz ovih rezultata možemo brzo izdvojiti sve bitne informacije:
t-statistiku, stepene slobode i p vrednost
interpretaciju alternativne hipoteze
95% interval poverenja za koeficijent korelacije
vrednost koeficijenta korelacije u uzorku
Ova elegantna jednostavnost u primeni i interpretaciji čini koeficijent korelacije izuzetno korisnim alatom u istraživanjima, naročito kada ispitujemo povezanost varijabli bez zalaženja u kompleksnu problematiku uzročnosti.
No, tu nije kraj. Zbog svoje neraskidive veze sa regresijom, korelacija služi i kao moćan dijagnostički alat. Razmotrimo formulu za standardnu grešku korelacije - u njoj se pojavljuje kvadrat koeficijenta korelacije. Šta dobijamo ovim kvadriranjem? S obzirom da se korelacija kreće između -1 i 1, njen kvadrat će uvek biti između 0 i 1, što možemo izraziti i kao procenat od 0% do 100%. Ovaj broj nazivamo koeficijentom determinacije i on predstavlja ključni element u dijagnostici regresije.
10.5 Koeficijent determinacije
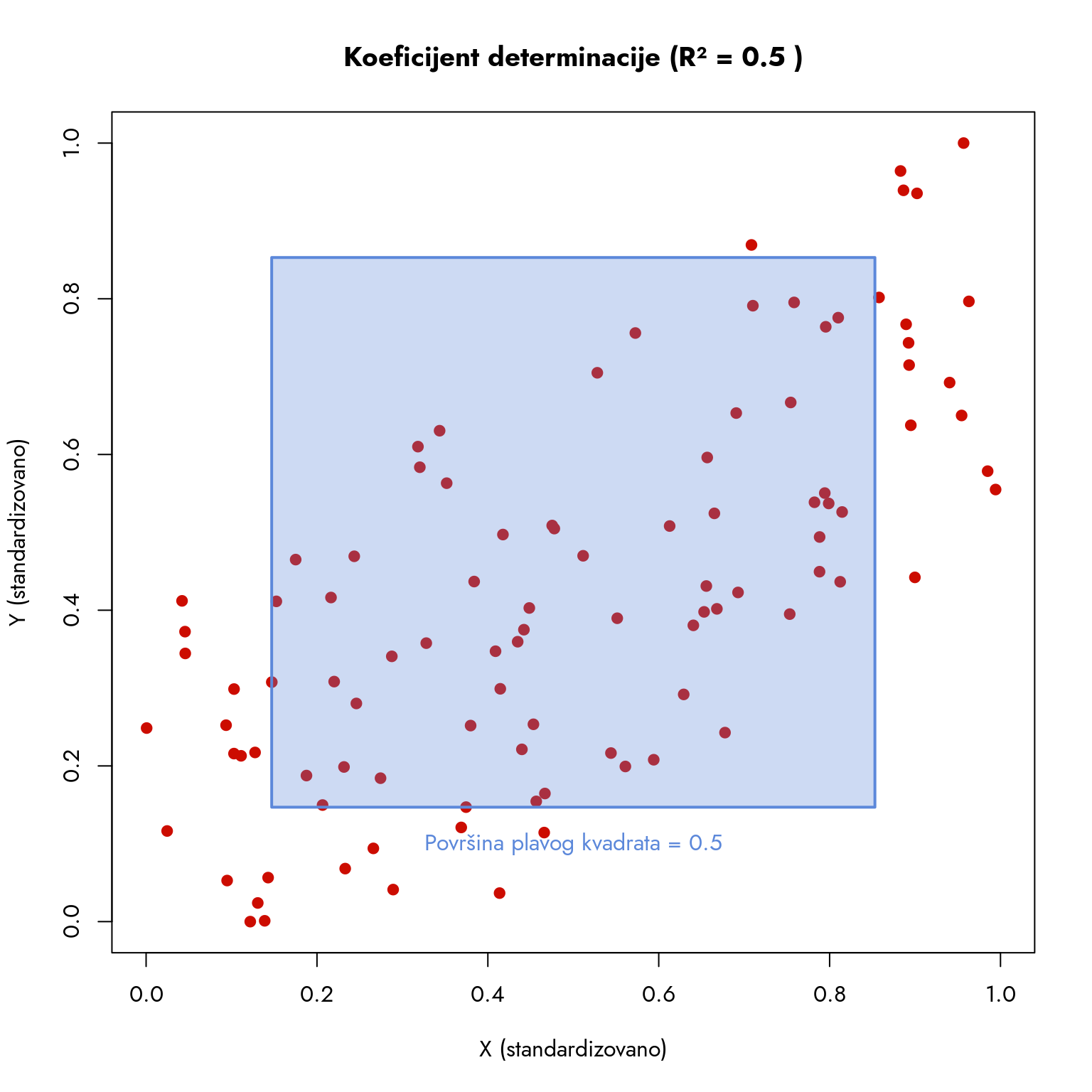
Koeficijent determinacije, koji označavamo sa \(R^2\), jeste kvadrat koeficijenta korelacije. Za njegovo bolje razumevanje, predstavićemo ga vizuelno kroz jednostavan primer. Umesto da nastavimo sa Netflix primerom, posmatraćemo odnos dve standardizovane varijable merene na skali od 0 do 1. Iako je ovo pojednostavljen primer koji olakšava interpretaciju i vizuelizaciju, ista logika se primenjuje i na složenije varijable merene na drugim skalama.
Slika 10.6: Vizuelizacija koeficijenta determinacije (R²)
Grafikon prikazuje dve standardizovane varijable (na skali od 0 do 1) čija korelacija iznosi približno 0.7. Koeficijent determinacije (\(R^2\)), koji je kvadrat ove vrednosti, iznosi oko 0.5. Plavi kvadrat na grafikonu ima površinu jednaku \(R^2\), što vizuelno predstavlja procenat varijanse jedne varijable koji možemo objasniti drugom varijablom.
Ova vizuelizacija nam pomaže da razumemo zašto su vrednosti 0.3 i 0.7 bitne granice za interpretaciju korelacije:
Kada je \(|r| < 0.3\), \(R^2\) je manji od 0.1 (10% objašnjene varijanse)
Kada je \(0.3 \leq |r| \leq 0.7\), \(R^2\) je između 0.1 i 0.5 (10-50% objašnjene varijanse)
Kada je \(|r| > 0.7\), \(R^2\) je veći od 0.5 (preko 50% objašnjene varijanse)
Granica \(|r|=0.7\), odnosno \(R^2=0.5\), ima posebno intuitivno značenje. Ona nam govori da određeni regresioni model može da objasni najmanje polovinu varijabiliteta zavisne varijable. Jednostavnije rečeno, model objašnjava više nego što ostavlja neobjašnjeno. Zato korelacije preko 0.7 nazivamo jakim - one nam omogućavaju da sa visokom pouzdanošću predvidimo promene jedne varijable na osnovu promena druge.
Granica \(|r|=0.3\) predstavlja konvenciju - označava korelacije koje objašnjavaju manje od 10% varijabilnosti zavisne varijable. Ovako slab stepen povezanosti ukazuje da postoji mnogo prostora za druge faktore koji utiču na zavisnu varijablu. Kada otkrijemo slabu korelaciju između dve varijable, to nas usmerava ka istraživanju dodatnih faktora koji bi mogli bolje objasniti promene u zavisnoj varijabli. Jasno je da u takvim slučajevima trenutna nezavisna varijabla nije dovoljno precizan prediktor.
Kod analize bivarijatnih korelacija (korelacija između dve varijable), potreban je poseban oprez pri interpretaciji slabih korelacija. U praksi se često fokusiramo na korelacije koje se približavaju ili prelaze prag od 0.7, jer one pružaju čvršću empirijsku osnovu za zaključivanje o povezanosti varijabli.
Koeficijent determinacije predstavlja prirodan uvod u analizu varijabiliteta koji se može objasniti statističkim modelom. U prethodnom poglavlju smo naveli da je jedan od glavnih ciljeva regresionog (i donekle korelacionog) modela objašnjenje varijabiliteta zavisne varijable. Šta to konkretno znači?
Objašnjavanje varijabiliteta neke varijable znači da razumemo razlike koje postoje među opservacijama tako što ih direktno povezujemo sa razlikama u vrednostima nezavisne varijable. Konzistentnost tih razlika je naše glavno eksplanatorno sredstvo - alat pomoću kojeg gradimo objašnjenje. Kada utvrdimo da razlike u broju koraka dosledno prate razlike u vremenu provedenom uz Netflix, možemo preciznije objasniti zašto neki ljudi provode više ili manje vremena gledajući serije.
U svakom statističkom modelu razlikujemo dva tipa varijabiliteta:
Objašnjeni varijabilitet: deo varijacija zavisne varijable koji možemo direktno povezati sa promenama u nezavisnoj varijabli. Ovo je onaj deo koji naš model uspešno zahvata i opisuje.
Neobjašnjeni varijabilitet: preostali deo varijacija zavisne varijable koji nije povezan sa nezavisnom varijablom i ostaje van domašaja našeg modela.
Kako bismo precizno razumeli odnos između objašnjenog i neobjašnjenog varijabiliteta, koristimo moćan alat - analizu varijanse. O njoj detaljno govorimo u sledećem poglavlju.
10.6 Zadaci
CautionZadatak 1
Imamo podatke o broju sati provedenih na društvenim mrežama nedeljno (X) i prosečnoj oceni na studijama (Y) za uzorak od 50 studenata.
Izračunajte kovarijansu i Pirsonov koeficijent korelacije u uzorku. Šta nam oni govore o vezi između vremena provedenog na društvenim mrežama i akademskog uspeha?
Testirajte značajnost ove korelacije na nivou α = 0.05. Postavite hipoteze i sprovedite test.
Konstruišite 95% interval poverenja za populacionu korelaciju. Šta nam on govori o jačini veze u populaciji?
Istraživači su sproveli studiju o povezanosti između tri varijable na uzorku od 60 zaposlenih: - X: broj sati prekovremenog rada mesečno - Y: nivo stresa (skala 1-10) - Z: zadovoljstvo poslom (skala 1-10)
Izračunajte korelacije između svih parova varijabli.
Testirajte značajnost svih korelacija na nivou \(\alpha = 0.05\).
Šta možete zaključiti o odnosu između prekovremenog rada, stresa i zadovoljstva poslom? Koji elementi ovih odnosa su ključni za razumevanje radnog okruženja?
Sa kojim izazovima se suočavamo pri interpretaciji ovakvih korelacionih podataka? Objasnite moguća ograničenja u zaključivanju.